mirror of
https://github.com/chefyuan/algorithm-base.git
synced 2024-11-05 03:33:38 +00:00
425 lines
18 KiB
Markdown
425 lines
18 KiB
Markdown
|
|
### 快速排序
|
|||
|
|
|
|||
|
|
今天我们来说一下快速排序,这个排序算法也是面试的高频考点,原理很简单,我们一起来扒一下他吧。
|
|||
|
|
|
|||
|
|
我们先来说一下快速排序的基本思想。
|
|||
|
|
|
|||
|
|
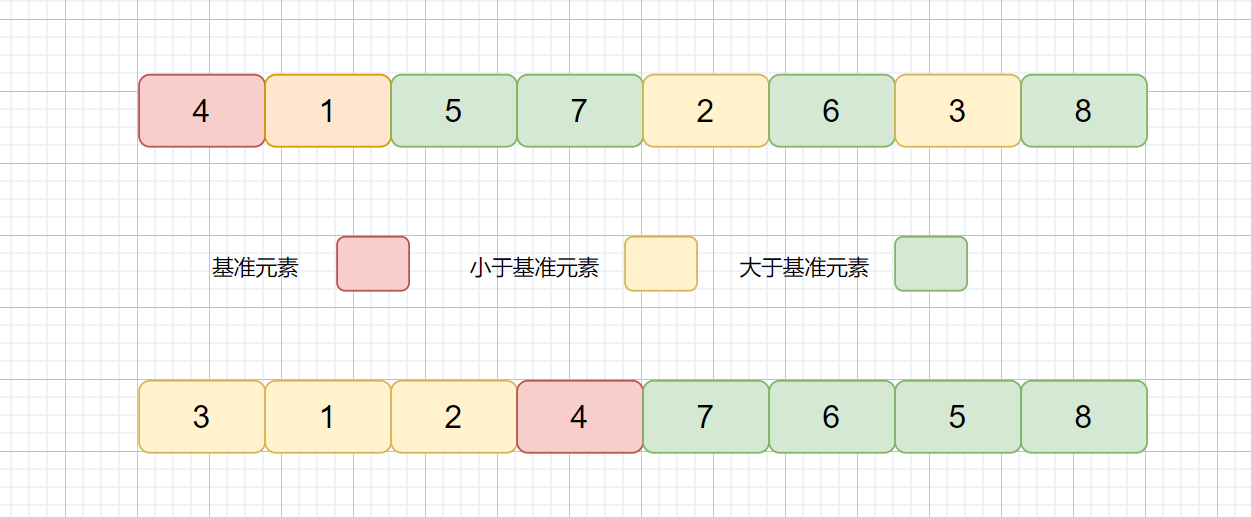
1.先从数组中找一个基准数
|
|||
|
|
|
|||
|
|
2.让其他比它大的元素移动到数列一边,比他小的元素移动到数列另一边,从而把数组拆解成两个部分。
|
|||
|
|
|
|||
|
|
3.再对左右区间重复第二步,直到各区间只有一个数。
|
|||
|
|
|
|||
|
|
见下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
上图则为一次快排示意图,下面我们再利用递归,分别对左半边区间也就是 [3,1,2] 和右半区间 [7,6,5,8] 执行上诉过程,直至区间缩小为 1 也就是第三条,则此时所有的数据都有序。
|
|||
|
|
|
|||
|
|
简单来说就是我们利用基准数通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比基准数小,另一部分记录的关键字均比基准数大,然后分别对这两部分记录继续进行排序,进而达到有序。
|
|||
|
|
|
|||
|
|
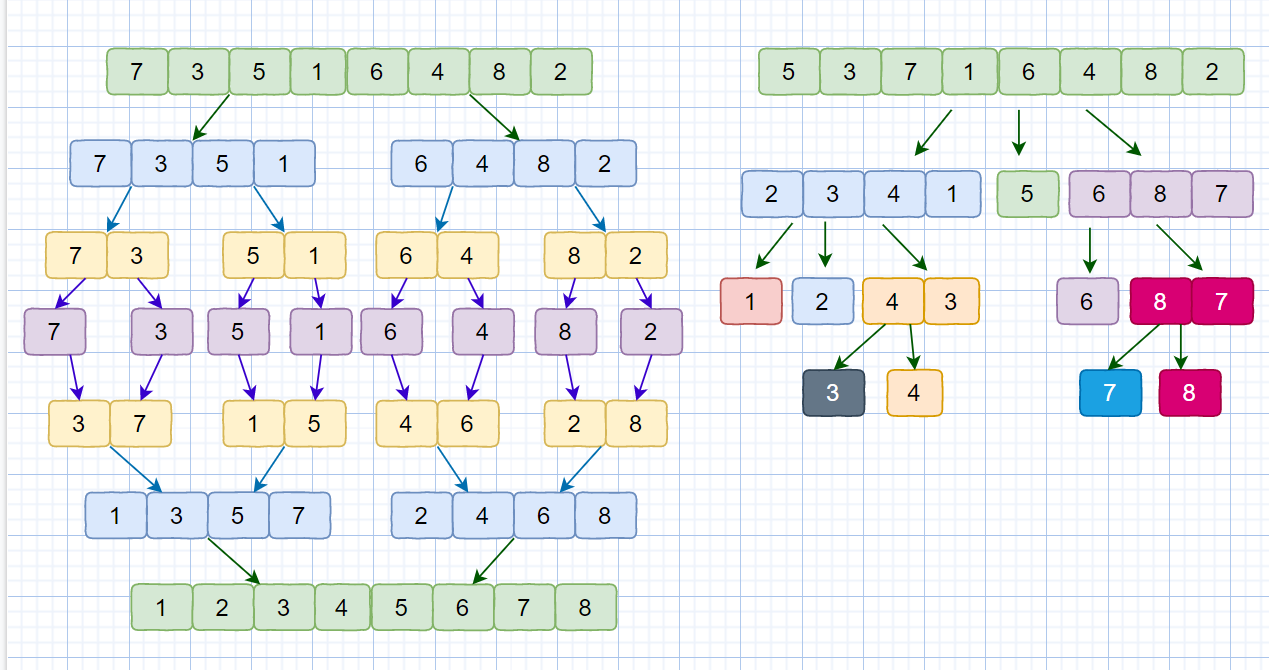
我们现在应该了解了快速排序的思想,那么大家还记不记得我们之前说过的归并排序,他们两个用到的都是分治思想,那他们两个有什么不同呢?见下图
|
|||
|
|
|
|||
|
|
注:快速排序我们以序列的第一个元素作为基准数
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
虽然归并排序和快速排序都用到了分治思想,但是归并排序是自下而上的,先处理子问题,然后再合并,将小集合合成大集合,最后实现排序。而快速排序是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题
|
|||
|
|
|
|||
|
|
我们根据思想可知,排序算法的核心就是如何利用基准数将记录分区,这里我们主要介绍两种容易理解的方法,一种是挖坑填数,另一种是利用双指针思想进行元素交换。
|
|||
|
|
|
|||
|
|
下面我们先来介绍下挖坑填数的分区方法
|
|||
|
|
|
|||
|
|
基本思想是我们首先以序列的第一个元素为基准数,然后将该位置挖坑,下面判断 nums[hight] 是否大于基准数,如果大于则左移 hight 指针,直至找到一个小于基准数的元素,将其填入之前的坑中,则 hight 位置会出现一个新的坑,此时移动 low 指针,找到大于基准数的元素,填入新的坑中。不断迭代直至完成分区。
|
|||
|
|
|
|||
|
|
大家直接看我们的视频模拟吧,一目了然。
|
|||
|
|
|
|||
|
|
注:为了便于理解所以采取了挖坑的形式展示
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
是不是很容易就理解啦,下面我们直接看代码吧。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int[] sortArray(int[] nums) {
|
|||
|
|
|
|||
|
|
quickSort(nums,0,nums.length-1);
|
|||
|
|
return nums;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
public void quickSort (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
if (low < hight) {
|
|||
|
|
int index = partition(nums,low,hight);
|
|||
|
|
quickSort(nums,low,index-1);
|
|||
|
|
quickSort(nums,index+1,hight);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
public int partition (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
int pivot = nums[low];
|
|||
|
|
while (low < hight) {
|
|||
|
|
//移动hight指针
|
|||
|
|
while (low < hight && nums[hight] >= pivot) {
|
|||
|
|
hight--;
|
|||
|
|
}
|
|||
|
|
//填坑
|
|||
|
|
if (low < hight) nums[low] = nums[hight];
|
|||
|
|
while (low < hight && nums[low] <= pivot) {
|
|||
|
|
low++;
|
|||
|
|
}
|
|||
|
|
//填坑
|
|||
|
|
if (low < hight) nums[hight] = nums[low];
|
|||
|
|
}
|
|||
|
|
//基准数放到合适的位置
|
|||
|
|
nums[low] = pivot;
|
|||
|
|
return low;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
下面我们来看一下交换思路,原理一致,实现也比较简单。
|
|||
|
|
|
|||
|
|
见下图。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
其实这种方法,算是对上面方法的挖坑填坑步骤进行合并,low 指针找到大于 pivot 的元素,hight 指针找到小于 pivot 的元素,然后两个元素交换位置,最后再将基准数归位。两种方法都很容易理解和实现,即使是完全没有学习过快速排序的同学,理解了思想之后也能自己动手实现,下面我们继续用视频模拟下这种方法的执行过程吧。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
两种方法都很容易实现,对新手非常友好,大家可以自己去 AC 一下啊。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int[] sortArray (int[] nums) {
|
|||
|
|
|
|||
|
|
quickSort(nums,0,nums.length-1);
|
|||
|
|
return nums;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public void quickSort (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
if (low < hight) {
|
|||
|
|
int index = partition(nums,low,hight);
|
|||
|
|
quickSort(nums,low,index-1);
|
|||
|
|
quickSort(nums,index+1,hight);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public int partition (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
int pivot = nums[low];
|
|||
|
|
int start = low;
|
|||
|
|
|
|||
|
|
while (low < hight) {
|
|||
|
|
while (low < hight && nums[hight] >= pivot) hight--;
|
|||
|
|
while (low < hight && nums[low] <= pivot) low++;
|
|||
|
|
if (low >= hight) break;
|
|||
|
|
swap(nums, low, hight);
|
|||
|
|
}
|
|||
|
|
//基准值归位
|
|||
|
|
swap(nums,start,low);
|
|||
|
|
return low;
|
|||
|
|
}
|
|||
|
|
public void swap (int[] nums, int i, int j) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
nums[i] = nums[j];
|
|||
|
|
nums[j] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**快速排序的时间复杂度分析**
|
|||
|
|
|
|||
|
|
快排也是用递归来实现的。所以快速排序的时间性能取决于快速排序的递归树的深度。如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那么此时的递归树是平衡的,性能也较好,递归树的深度也就和之前归并排序求解方法一致,然后我们每一次分区需要对数组扫描一遍,做 n 次比较,所以最优情况下,快排的时间复杂度是 O(nlogn)。
|
|||
|
|
|
|||
|
|
但是大多数情况下我们不能划分的很均匀,比如数组为正序或者逆序时,即 [1,2,3,4] 或 [4,3,2,1] 时,此时为最坏情况,那么此时我们则需要递归调用 n-1 次,此时的时间复杂度则退化到了 O(n^2)。
|
|||
|
|
|
|||
|
|
**快速排序的空间复杂度分析**
|
|||
|
|
|
|||
|
|
快速排序主要时递归造成的栈空间的使用,最好情况时其空间复杂度为O (logn),对应递归树的深度。最坏情况时则需要 n-1 次递归调用,此时空间复杂度为O(n).
|
|||
|
|
|
|||
|
|
**快速排序的稳定性分析**
|
|||
|
|
|
|||
|
|
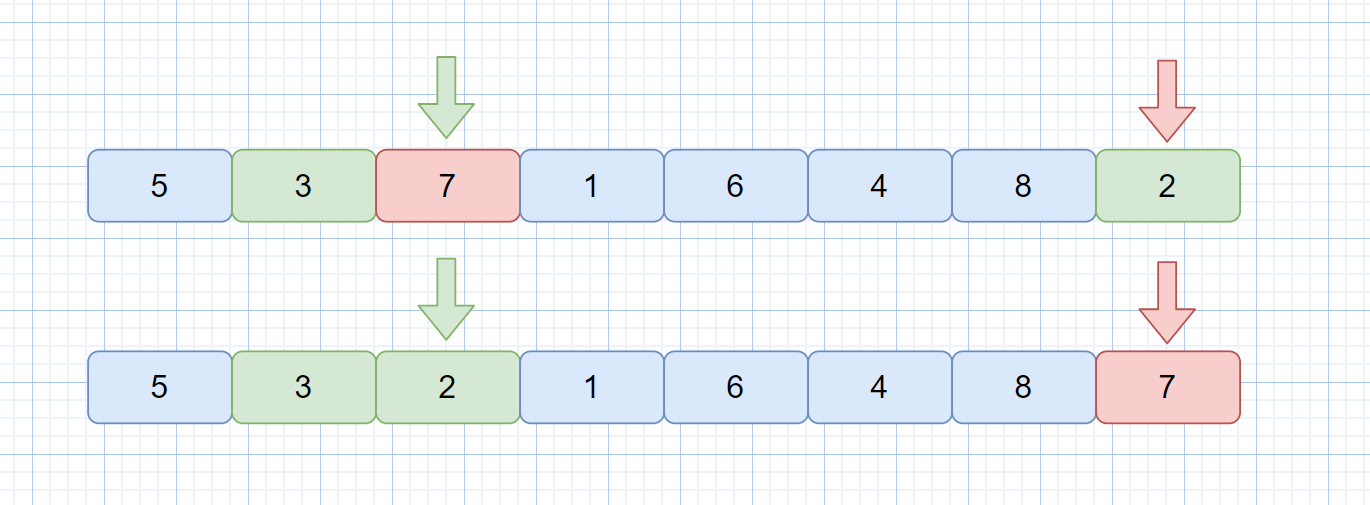
快速排序是一种不稳定的排序算法,因为其关键字的比较和交换是跳跃进行的,见下图。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
此时无论使用哪一种方法,第一次排序后,黄色的 1 都会跑到红色 1 的前面,所以快速排序是不稳定的排序算法。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
好啦,快速排序我们掌握的差不多了,下面我们一起来看看如何对其优化吧。
|
|||
|
|
|
|||
|
|
**快速排序的迭代写法**
|
|||
|
|
|
|||
|
|
该方法实现也是比较简单的,借助了栈来实现,很容易实现。主要利用了先进后出的特性,这里需要注意的就是入栈的顺序,这里算是一个小细节,需要注意一下。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
|
|||
|
|
public int[] sortArray(int[] nums) {
|
|||
|
|
Stack<Integer> stack = new Stack<>();
|
|||
|
|
stack.push(nums.length - 1);
|
|||
|
|
stack.push(0);
|
|||
|
|
while (!stack.isEmpty()) {
|
|||
|
|
int low = stack.pop();
|
|||
|
|
int hight = stack.pop();
|
|||
|
|
|
|||
|
|
if (low < hight) {
|
|||
|
|
int index = partition(nums, low, hight);
|
|||
|
|
stack.push(index - 1);
|
|||
|
|
stack.push(low);
|
|||
|
|
stack.push(hight);
|
|||
|
|
stack.push(index + 1);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
return nums;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public int partition (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
int pivot = nums[low];
|
|||
|
|
int start = low;
|
|||
|
|
while (low < hight) {
|
|||
|
|
|
|||
|
|
while (low < hight && nums[hight] >= pivot) hight--;
|
|||
|
|
while (low < hight && nums[low] <= pivot) low++;
|
|||
|
|
if (low >= hight) break;
|
|||
|
|
swap(nums, low, hight);
|
|||
|
|
}
|
|||
|
|
swap(nums,start,low);
|
|||
|
|
return low;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
public void swap (int[] nums, int i, int j) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
nums[i] = nums[j];
|
|||
|
|
nums[j] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**快速排序优化**
|
|||
|
|
|
|||
|
|
**三数取中法**
|
|||
|
|
|
|||
|
|
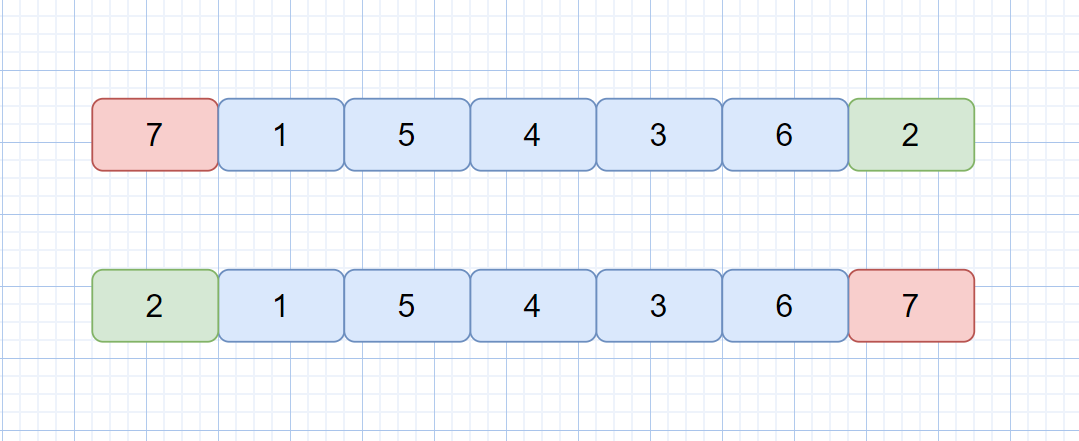
我们在上面的例子中选取的都是 nums[low] 做为我们的基准值,那么当我们遇到特殊情况时呢?见下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
我们按上面的方法,选取第一个元素做为基准元素,那么我们执行一轮排序后,发现仅仅是交换了 2 和 7 的位置,这是因为 7 为序列的最大值。所以我们的 pivot 的选取尤为重要,选取时应尽量避免选取序列的最大或最小值做为基准值。则我们可以利用三数取中法来选取基准值。
|
|||
|
|
|
|||
|
|
也就是选取三个元素中的中间值放到 nums[low] 的位置,做为基准值。这样就避免了使用最大值或最小值做为基准值。
|
|||
|
|
|
|||
|
|
所以我们可以加上这几行代码实现三数取中法。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
int mid = low + ((hight-low) >> 1);
|
|||
|
|
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
|||
|
|
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
|||
|
|
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
其含义就是让我们将中间元素放到 nums[low] 位置做为基准值,最大值放到 nums[hight],最小值放到 nums[mid],即 [4,2,3] 经过上面代码处理后,则变成了 [3,2,4].此时我们选取 3 做为基准值,这样也就避免掉了选取最大或最小值做为基准值的情况。
|
|||
|
|
|
|||
|
|
**三数取中法**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int[] sortArray(int[] nums) {
|
|||
|
|
quickSort(nums,0,nums.length-1);
|
|||
|
|
return nums;
|
|||
|
|
}
|
|||
|
|
public void quickSort (int[] nums, int low, int hight) {
|
|||
|
|
if (low < hight) {
|
|||
|
|
int index = partition(nums,low,hight);
|
|||
|
|
quickSort(nums,low,index-1);
|
|||
|
|
quickSort(nums,index+1,hight);
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public int partition (int[] nums, int low, int hight) {
|
|||
|
|
//三数取中,大家也可以使用其他方法
|
|||
|
|
int mid = low + ((hight-low) >> 1);
|
|||
|
|
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
|||
|
|
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
|||
|
|
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
|||
|
|
//下面和之前一样,仅仅是多了上面几行代码
|
|||
|
|
int pivot = nums[low];
|
|||
|
|
int start = low;
|
|||
|
|
while (low < hight) {
|
|||
|
|
while (low < hight && nums[hight] >= pivot) hight--;
|
|||
|
|
while (low < hight && nums[low] <= pivot) low++;
|
|||
|
|
if (low >= hight) break;
|
|||
|
|
swap(nums, low, hight);
|
|||
|
|
}
|
|||
|
|
swap(nums,start,low);
|
|||
|
|
return low;
|
|||
|
|
}
|
|||
|
|
public void swap (int[] nums, int i, int j) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
nums[i] = nums[j];
|
|||
|
|
nums[j] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
**和插入排序搭配使用**
|
|||
|
|
|
|||
|
|
我们之前说过,插入排序在元素个数较少时效率是最高的,所以当元素数量较少时,快速排序反而不如插入排序好用,所以我们可以设定一个阈值,当元素个数大于阈值时使用快速排序,小于等于该阈值时则使用插入排序。我们设定阈值为 7 。
|
|||
|
|
|
|||
|
|
**三数取中+插入排序**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
private static final int INSERTION_SORT_MAX_LENGTH = 7;
|
|||
|
|
|
|||
|
|
public int[] sortArray(int[] nums) {
|
|||
|
|
quickSort(nums,0,nums.length-1);
|
|||
|
|
return nums;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public void quickSort (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
if (hight - low <= INSERTION_SORT_MAX_LENGTH) {
|
|||
|
|
insertSort(nums,low,hight);
|
|||
|
|
return;
|
|||
|
|
}
|
|||
|
|
int index = partition(nums,low,hight);
|
|||
|
|
quickSort(nums,low,index-1);
|
|||
|
|
quickSort(nums,index+1,hight);
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public int partition (int[] nums, int low, int hight) {
|
|||
|
|
//三数取中,大家也可以使用其他方法
|
|||
|
|
int mid = low + ((hight-low) >> 1);
|
|||
|
|
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
|||
|
|
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
|||
|
|
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
|||
|
|
int pivot = nums[low];
|
|||
|
|
int start = low;
|
|||
|
|
while (low < hight) {
|
|||
|
|
while (low < hight && nums[hight] >= pivot) hight--;
|
|||
|
|
while (low < hight && nums[low] <= pivot) low++;
|
|||
|
|
if (low >= hight) break;
|
|||
|
|
swap(nums, low, hight);
|
|||
|
|
}
|
|||
|
|
swap(nums,start,low);
|
|||
|
|
return low;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
public void insertSort (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
for (int i = low+1; i <= hight; ++i) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
int j;
|
|||
|
|
for (j = i-1; j >= 0; --j) {
|
|||
|
|
if (temp < nums[j]) {
|
|||
|
|
nums[j+1] = nums[j];
|
|||
|
|
continue;
|
|||
|
|
}
|
|||
|
|
break;
|
|||
|
|
}
|
|||
|
|
nums[j+1] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
public void swap (int[] nums, int i, int j) {
|
|||
|
|
|
|||
|
|
int temp = nums[i];
|
|||
|
|
nums[i] = nums[j];
|
|||
|
|
nums[j] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
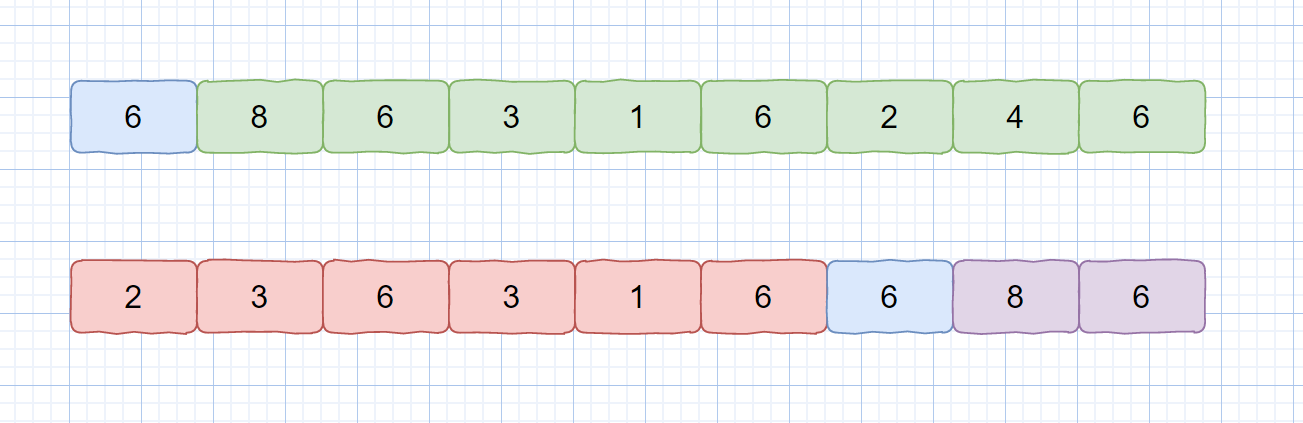
我们继续看下面这种情况
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
我们对其执行一次排序后,则会变成上面这种情况,然后我们继续对蓝色基准值的左区间和右区间执行相同操作。也就是 [2,3,6,3,1,6] 和 [8,6] 。我们注意观察一次排序的结果数组中是含有很多重复元素的。
|
|||
|
|
|
|||
|
|
那么我们为什么不能将相同元素放到一起呢?这样就能大大减小递归调用时的区间大小,见下图。
|
|||
|
|
|
|||
|
|
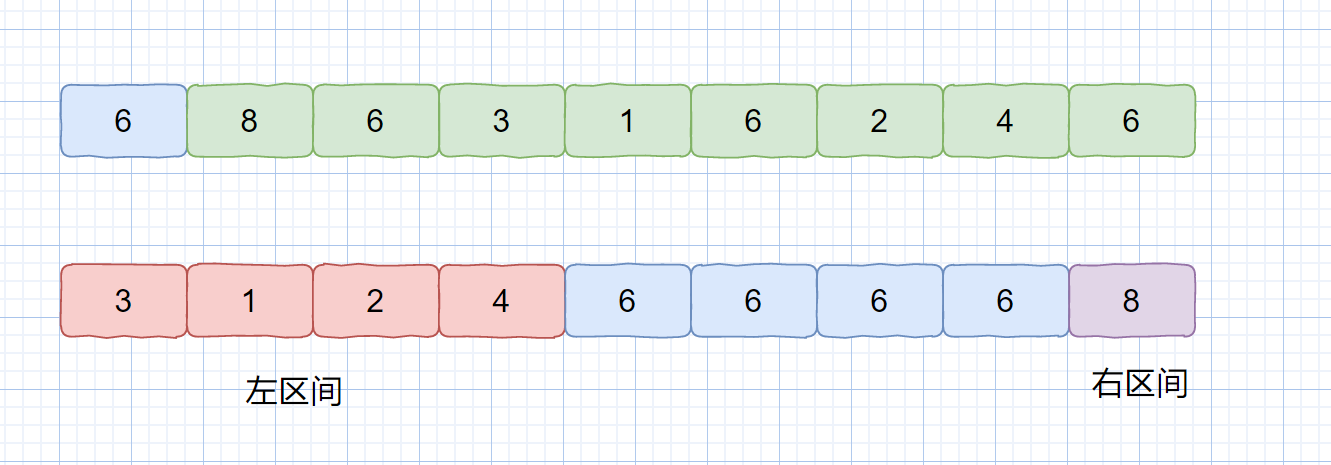
|
|||
|
|
|
|||
|
|
这样就减小了我们的区间大小,将数组切分成了三部分,小于基准数的左区间,大于基准数的右区间,等于基准数的中间区间。
|
|||
|
|
|
|||
|
|
下面我们来看一下如何达到上面的情况,我们先来进行视频模拟,模拟之后应该就能明白啦。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
我们来剖析一下视频,其实原理很简单,我们利用探路指针也就是 i,遇到比 pivot 大的元素,则和 right 指针进行交换,此时 right 指向的元素肯定比 pivot 大,则 right--,但是,此时我们的 nums[i] 指向的元素并不知道情况,所以我们的 i 指针不动,如果此时 nums[i] < pivot 则与 left 指针交换,注意此时我们的 left 指向的值肯定是 等于 povit的,所以交换后我们要 left++,i++, nums[i] == pivot 时,仅需要 i++ 即可,继续判断下一个元素。 我们也可以借助这个思想来解决经典的荷兰国旗问题。
|
|||
|
|
|
|||
|
|
好啦,我们下面直接看代码吧。
|
|||
|
|
|
|||
|
|
**三数取中+三向切分+插入排序**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
private static final int INSERTION_SORT_MAX_LENGTH = 7;
|
|||
|
|
public int[] sortArray(int[] nums) {
|
|||
|
|
quickSort(nums,0,nums.length-1);
|
|||
|
|
return nums;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
public void quickSort(int nums[], int low, int hight) {
|
|||
|
|
//插入排序
|
|||
|
|
if (hight - low <= INSERTION_SORT_MAX_LENGTH) {
|
|||
|
|
insertSort(nums,low,hight);
|
|||
|
|
return;
|
|||
|
|
}
|
|||
|
|
//三数取中
|
|||
|
|
int mid = low + ((hight-low) >> 1);
|
|||
|
|
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
|||
|
|
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
|||
|
|
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
|||
|
|
//三向切分
|
|||
|
|
int left = low, i = low + 1, right = hight;
|
|||
|
|
int pvoit = nums[low];
|
|||
|
|
while (i <= right) {
|
|||
|
|
if (pvoit < nums[i]) {
|
|||
|
|
swap(nums,i,right);
|
|||
|
|
right--;
|
|||
|
|
} else if (pvoit == nums[i]) {
|
|||
|
|
i++;
|
|||
|
|
} else {
|
|||
|
|
swap(nums,left,i);
|
|||
|
|
left++;
|
|||
|
|
i++;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
quickSort(nums,low,left-1);
|
|||
|
|
quickSort(nums,right+1,hight);
|
|||
|
|
}
|
|||
|
|
public void insertSort (int[] nums, int low, int hight) {
|
|||
|
|
|
|||
|
|
for (int i = low+1; i <= hight; ++i) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
int j;
|
|||
|
|
for (j = i-1; j >= 0; --j) {
|
|||
|
|
if (temp < nums[j]) {
|
|||
|
|
nums[j+1] = nums[j];
|
|||
|
|
continue;
|
|||
|
|
}
|
|||
|
|
break;
|
|||
|
|
}
|
|||
|
|
nums[j+1] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
public void swap (int[] nums, int i, int j) {
|
|||
|
|
int temp = nums[i];
|
|||
|
|
nums[i] = nums[j];
|
|||
|
|
nums[j] = temp;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
好啦,一些常用的优化方法都整理出来啦,还有一些其他的优化算法九数取中,优化递归操作等就不在这里进行描述啦,感兴趣的可以自己看一下。好啦,这期的文章就到这里啦,我们下期见,拜了个拜。
|
|||
|
|
|