mirror of
https://github.com/chefyuan/algorithm-base.git
synced 2026-03-12 04:41:24 +00:00
test
This commit is contained in:
100
gif-algorithm/数据结构和算法/希尔排序.md
Normal file
100
gif-algorithm/数据结构和算法/希尔排序.md
Normal file
@@ -0,0 +1,100 @@
|
|||||||
|
### **希尔排序 (Shell's Sort)**
|
||||||
|
|
||||||
|
我们在之前说过直接插入排序在记录基本有序的时候和元素较少时效率是很高的,基本有序时,只需执行少量的插入操作,就可以完成整个记录的排序工作。当元素较少时,效率也很高,就比如我们经常用的 Arrays.sort (),当元素个数少于47时,使用的排序算法就是直接插入排序。那么直接希尔排序和直接插入排序有什么关系呢?
|
||||||
|
|
||||||
|
希尔排序是**插入排序**的一种,又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序的高级变形,其思想简单点说就是有跨度的插入排序,这个跨度会逐渐变小,直到变为 1,变为 1 时记录也就基本有序,这时用到的也就是我们之前讲的直接插入排序了。
|
||||||
|
|
||||||
|
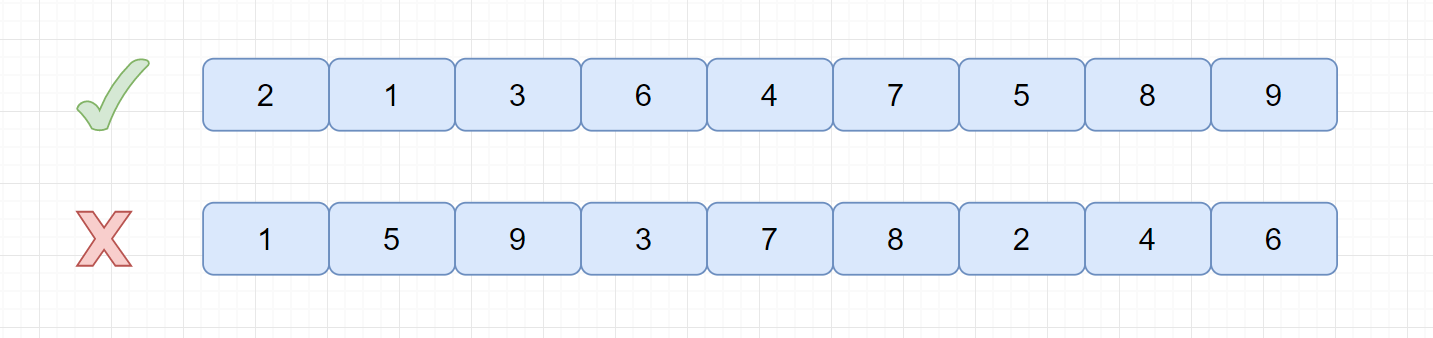
基本有序:就是小的关键字基本在前面,大的关键字基本在后面,不大不小的基本在中间。见下图。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我们已经了解了希尔排序的基本思想,下面我们通过一个绘图来描述下其执行步骤。
|
||||||
|
|
||||||
|
.1oixbv11eork.png)
|
||||||
|
|
||||||
|
先逐步分组进行粗调,在进行直接插入排序的思想就是希尔排序。我们刚才的分组跨度(4,2,1)被称为希尔排序的增量,我们上面用到的是逐步折半的增量方法,这也是在发明希尔排序时提出的一种朴素方法,被称为希尔增量,
|
||||||
|
|
||||||
|
下面我们用动图模拟下使用希尔增量的希尔排序的执行过程
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
大家可能看了视频模拟,也不是特别容易写出算法代码,不过你们看到代码肯定会很熟悉滴。
|
||||||
|
|
||||||
|
**希尔排序代码**
|
||||||
|
|
||||||
|
```java
|
||||||
|
class Solution {
|
||||||
|
public int[] sortArray(int[] nums) {
|
||||||
|
int increment = nums.length;
|
||||||
|
//注意看结束条件
|
||||||
|
while (increment > 1) {
|
||||||
|
//这里可以自己设置
|
||||||
|
increment = increment / 2;
|
||||||
|
//根据增量分组
|
||||||
|
for (int i = 0; i < increment; ++i) {
|
||||||
|
//这快是不是有点面熟,回去看看咱们的插入排序
|
||||||
|
for (int j = i + increment; j < nums.length; ++j) {
|
||||||
|
int temp = nums[j];
|
||||||
|
int k;
|
||||||
|
for (k = j - increment; k >= 0; k -= increment) {
|
||||||
|
if (temp < nums[k]) {
|
||||||
|
nums[k+increment] = nums[k];
|
||||||
|
continue;
|
||||||
|
}
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
nums[k+increment] = temp;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return nums;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
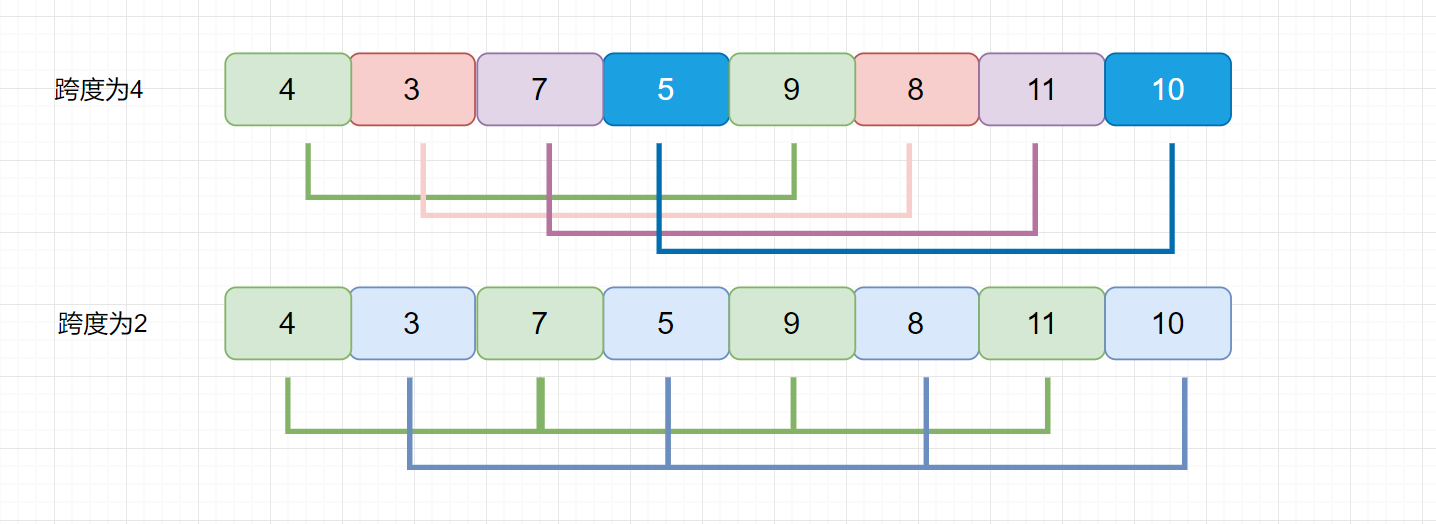
我们刚才说,我们的增量可以自己设置的,我们上面的例子是用的希尔增量,下面我们看这个例子,看看使用希尔增量会出现什么问题。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
我们发现无论是以 4 为增量,还是以 2 为增量,每组内部的元素没有任何交换。直到增量为 1 时,数组才会按照直接插入排序进行调整。所以这种情况希尔排序的效率是低于直接插入排序呢?
|
||||||
|
|
||||||
|
我们的希尔增量因为每一轮之间是等比的,所以会有盲区,这里增量的选取就非常关键了。
|
||||||
|
|
||||||
|
下面给大家介绍两个比较有代表性的 Sedgewick 增量和 Hibbard 增量
|
||||||
|
|
||||||
|
Sedgewick 增量序列如下:
|
||||||
|
|
||||||
|
1,5,19,41,109.。。。
|
||||||
|
|
||||||
|
通项公式 9*4^k - 9*2^
|
||||||
|
|
||||||
|
利用此种增量方式的希尔排序,最坏时间复杂度是O(n^(4/3))
|
||||||
|
|
||||||
|
Hibbard增量序列如下:
|
||||||
|
|
||||||
|
1,3,7,15......
|
||||||
|
|
||||||
|
通项公式2 ^ k-1
|
||||||
|
|
||||||
|
利用此种增量方式的希尔排序,最坏时间复杂度为O(n^(3/2))
|
||||||
|
|
||||||
|
上面是两种比较具有代表性的增量方式,可究竟应该选取怎样的增量才是最好,目前还是一个数学难题。不过我们需要注意的一点,就是增量序列的最后一个增量值必须等于1才行。
|
||||||
|
|
||||||
|
**希尔排序时间复杂度分析**
|
||||||
|
|
||||||
|
希尔排序的时间复杂度跟增量序列的选择有关,范围为 O(n^(1.3-2)) 在此之前的排序算法时间复杂度基本都是O(n^2),希尔排序是突破这个时间复杂度的第一批算法之一。
|
||||||
|
|
||||||
|
**希尔排序空间复杂度分析**
|
||||||
|
|
||||||
|
根据我们的视频可知希尔排序的空间复杂度为 O(1),
|
||||||
|
|
||||||
|
**希尔排序的稳定性分析**
|
||||||
|
|
||||||
|
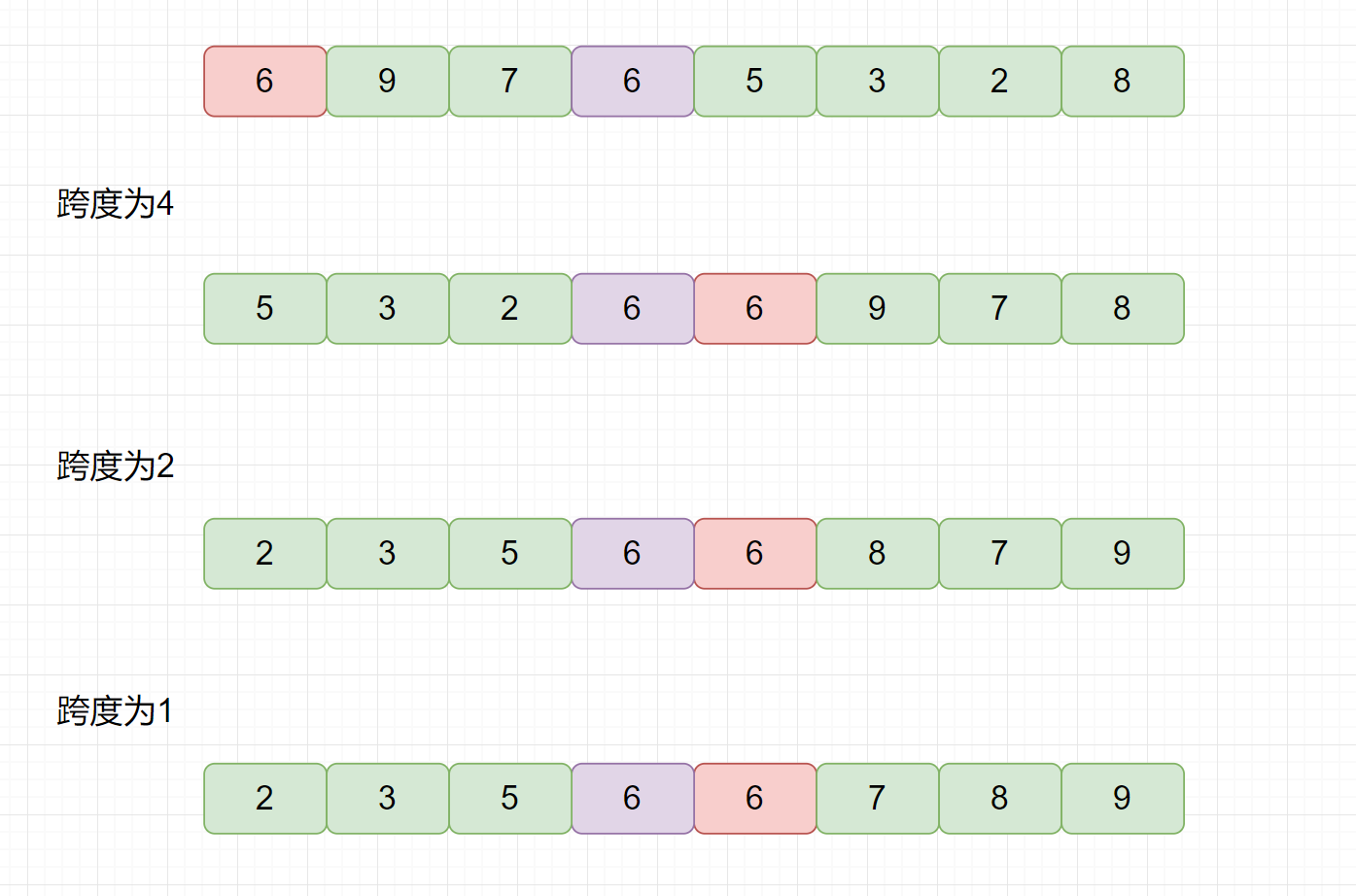
我们见下图,一起来分析下希尔排序的稳定性。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
通过上图,可知,如果我们选用 4 为跨度的话,交换后,两个相同元素 2 的相对位置会发生改变,所以希尔排序是一个不稳定的排序
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
61
gif-algorithm/数据结构和算法/直接插入排序.md
Normal file
61
gif-algorithm/数据结构和算法/直接插入排序.md
Normal file
@@ -0,0 +1,61 @@
|
|||||||
|
### **直接插入排序(Straight Insertion Sort)**
|
||||||
|
|
||||||
|
袁记菜馆内
|
||||||
|
|
||||||
|
袁厨:好嘞,我们打烊啦,一起来玩会扑克牌吧。
|
||||||
|
|
||||||
|
小二:好啊,掌柜的,咱们玩会斗地主吧。
|
||||||
|
|
||||||
|
相信大家应该都玩过扑克牌吧,我们平常摸牌时,是不是一边摸牌,一边理牌,摸到新牌时,会将其插到合适的位置。这其实就是我们的插入排序思想。
|
||||||
|
|
||||||
|
直接插入排序:将一个记录插入到已经排好序的有序表中,从而得到一个新的有序表。通俗理解,我们首先将序列分成两个区间,有序区间和无序区间,我们每次在无序区间内取一个值,在已排序区间中找到合适的插入位置将其插入,并保证已排序区间一直有序。下面我们看一下动图吧。
|
||||||
|
|
||||||
|
注:为了更清晰表达算法思想,则采用了挖掉待排序元素的形式展示,后面也会采取此形式表达。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**直接插入排序代码**
|
||||||
|
|
||||||
|
```java
|
||||||
|
class Solution {
|
||||||
|
public int[] sortArray(int[] nums) {
|
||||||
|
//注意 i 的初始值为 1,也就是第二个元素开始
|
||||||
|
for (int i = 1; i < nums.length; ++i) {
|
||||||
|
//待排序的值
|
||||||
|
int temp = nums[i];
|
||||||
|
//需要注意
|
||||||
|
int j;
|
||||||
|
for (j = i-1; j >= 0; --j) {
|
||||||
|
//找到合适位置
|
||||||
|
if (temp < nums[j]) {
|
||||||
|
nums[j+1] = nums[j];
|
||||||
|
continue;
|
||||||
|
}
|
||||||
|
//跳出循环
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
//插入到合适位置,这也就是我们没有在 for 循环内定义变量的原因
|
||||||
|
nums[j+1] = temp;
|
||||||
|
}
|
||||||
|
return nums;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**直接插入排序时间复杂度分析**
|
||||||
|
|
||||||
|
最好情况时,也就是有序的时候,我们不需要移动元素,每次只需要比较一次即可找到插入位置,那么最好情况时的时间复杂度为O(n)。
|
||||||
|
|
||||||
|
最坏情况时,即待排序表是逆序的情况,则此时需要比较2+3+....+n = (n+2)*(n-1)/2,移动次数也达到了最大值,3 +4+5+....n+1 = (n+4)*(n-1)/2,时间复杂度为O(n^2).
|
||||||
|
|
||||||
|
我们每次插入一个数据的时间复杂度为O(n),那么循环执行 n 次插入操作,平均时间复杂度为O(n^2)。
|
||||||
|
|
||||||
|
**直接插入排序空间复杂度分析**
|
||||||
|
|
||||||
|
根据动画可知,插入排序不需要额外的存储空间,所以其空间复杂度为O(1)
|
||||||
|
|
||||||
|
**直接插入排序稳定性分析**
|
||||||
|
|
||||||
|
我们根据代码可知,我们只会移动比 temp 值大的元素,所以我们排序后可以保证相同元素的相对位置不变。所以直接插入排序为稳定性排序算法。
|
||||||
|
|
||||||
|

|
||||||
66
gif-algorithm/数据结构和算法/简单选择排序.md
Normal file
66
gif-algorithm/数据结构和算法/简单选择排序.md
Normal file
@@ -0,0 +1,66 @@
|
|||||||
|
### **简单选择排序**
|
||||||
|
|
||||||
|
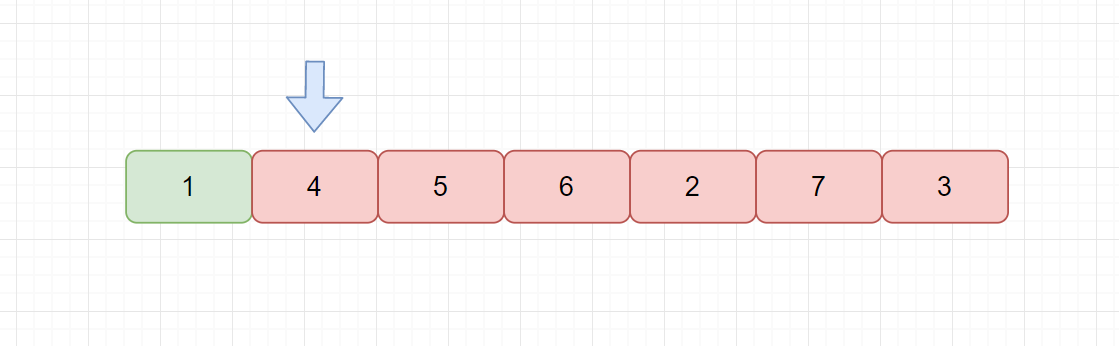
我们的冒泡排序不断进行交换,通过交换完成最终的排序,我们的简单选择排序的思想也很容易理解,主要思路就是我们每一趟在 n-i+1 个记录中选取关键字最小的记录作为有序序列的第 i 个记录。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
例如上图,绿色代表已经排序的元素,红色代表未排序的元素。我们当前指针指向 4 ,则我们遍历红色元素,从中找到最小值,然后与 4 交换。我们发现选择排序执行完一次循环也至少可以将 1 个元素归位。
|
||||||
|
|
||||||
|
下面我们来看一下代码的执行过程,看过之后肯定能写出代码的。
|
||||||
|
|
||||||
|
注:我们为了更容易理解,min 值保存的是值,而不是索引,实际代码中保存的是索引
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**简单选择排序代码**
|
||||||
|
|
||||||
|
```java
|
||||||
|
class Solution {
|
||||||
|
public int[] sortArray(int[] nums) {
|
||||||
|
|
||||||
|
int len = nums.length;
|
||||||
|
int min = 0;
|
||||||
|
for (int i = 0; i < len; ++i) {
|
||||||
|
min = i;
|
||||||
|
//遍历到最小值
|
||||||
|
for (int j = i + 1; j < len; ++j) {
|
||||||
|
if (nums[min] > nums[j]) min = j;
|
||||||
|
}
|
||||||
|
if (min != i) swap(nums,i,min);
|
||||||
|
}
|
||||||
|
return nums;
|
||||||
|
}
|
||||||
|
public void swap (int[] nums, int i, int j) {
|
||||||
|
int temp = nums[i];
|
||||||
|
nums[i] = nums[j];
|
||||||
|
nums[j] = temp;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
**简单选择排序时间复杂度分析**
|
||||||
|
|
||||||
|
从简单选择排序的过程来看,他最大的特点就是交换移动数据次数相当少,这样也就节省了排序时间,简单选择和冒泡排序不一样,我们发现无论最好情况和最坏情况,元素间的比较次数是一样的,第 i 次排序,需要 n - i 次比较,n 代表数组长度,则一共需要比较(n-1) + (n-2) +.... + 2 + 1= n*(n-1)/2 次,对于交换而言,最好情况交换 0 次,最坏情况(逆序时)交换 n - 1次。那么简单选择排序时间复杂度也为 O(n^2) 但是其交换次数远小于冒泡排序,所以其效率是好于冒泡排序的。
|
||||||
|
|
||||||
|
**简单选择排序空间复杂度分析**
|
||||||
|
|
||||||
|
由我们动图可知,我们的简单选择排序只用到了常量级的额外空间,所以空间复杂度为 O(1)。
|
||||||
|
|
||||||
|
**简单选择排序稳定性分析**
|
||||||
|
|
||||||
|
我们思考一下,我们的简单选择排序是稳定的吗?显然不是稳定的,因为我们需要在指针后面找到最小的值,与指针指向的值交换,见下图。
|
||||||
|
|
||||||
|
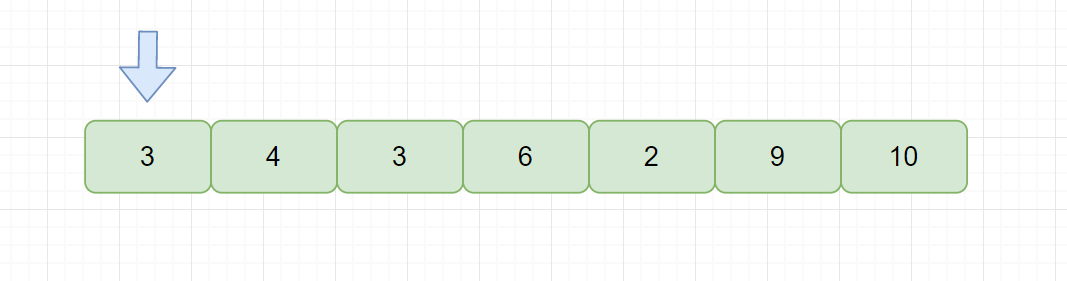
|
||||||
|
|
||||||
|
此时我们需要从后面元素中找到最小的元素与指针指向元素交换,也就是元素 2 。但是我们交换后发现,两个相等元素 3 的相对位置发生了改变,所以简单选择排序是不稳定的排序算法。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|
||||||
|
| ------------ | -------------- | -------------- | -------------- | ---------- | -------- |
|
||||||
|
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
|
||||||
|
|
||||||
Reference in New Issue
Block a user