mirror of
https://github.com/chefyuan/algorithm-base.git
synced 2026-03-11 20:31:21 +00:00
数据结构
This commit is contained in:
203
gif-algorithm/数据结构和算法/合成.md
Normal file
203
gif-algorithm/数据结构和算法/合成.md
Normal file
@@ -0,0 +1,203 @@
|
||||
之前我们说过了如何利用快速排序解决荷兰国旗问题,下面我们看下这两个题目
|
||||
|
||||
**剑指 Offer 45. 把数组排成最小的数**,**leetcode 179 最大数**
|
||||
|
||||
这两个问题根本上也是排序问题,下面我们一起来看一下题目描述
|
||||
|
||||
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
|
||||
|
||||
示例 1:
|
||||
|
||||
> 输入: [10,2]
|
||||
> 输出: "102"
|
||||
|
||||
示例 2:
|
||||
|
||||
> 输入: [3,30,34,5,9]
|
||||
> 输出: "3033459"
|
||||
|
||||
题目很容易理解,就是让我们找出拼接的所有数字中最小的一个,但是我们需要注意的是,因为输出结果较大,所以我们不能返回 int 应该将数字转换成字符串,所以这类问题还是隐形的大数问题。
|
||||
|
||||
我们看到这个题目时,可能想到的是这种解题思路,我们首先求出数组中所有数字的全排列,然后将排列拼起来,最后再从中取出最小的值,但是我们共有 n 个数,则有 n !个排列,显然数目是十分庞大的,那么我们有没有其他更高效的方法呢?
|
||||
|
||||
大家先来思考一下这个问题。
|
||||
|
||||
我们假设两个数字 m , n 可以拼接成 mn 和 nm 那么我们怎么返回最小的那个数字呢?
|
||||
|
||||
我们需要比较 mn 和 nm ,假设 mn < nm 则此时我们求得的最小数字就是 mn
|
||||
|
||||
> 注:mn 代表 m 和 n 进行拼接,例如 m = 10, n = 1,mn = 101
|
||||
|
||||
当 mn < nm 时,得到最小数字 mn, 因为在最小数字 mn 中 ,m 排在 n 的前面,我们此时定义 m "小于" n。
|
||||
|
||||
**注意:此时的 "小于" ,并不是数值的 < 。是我们自己定义,因为 m 在最小数字 mn 中位于 n 的前面,所以我们定义 m 小于 n。**
|
||||
|
||||
下面我们通过一个例子来加深下理解。
|
||||
|
||||
假设 m = 10,n = 1 则有 mn = 101 和 nm = 110
|
||||
|
||||
我们比较 101 和 110 ,发现 101 < 110 所以此时我们的最小数字为 101 ,又因为在最小数字中 10 (m) 排在 1(n) 的前面,我们根据定义则是 10 “小于” 1,反之亦然。
|
||||
|
||||
这时我们自己定义了一种新的,比较两个数字大小的规则,但是我们怎么保证这种规则是有效的?
|
||||
|
||||
怎么能确保通过这种规则,拼接数组中**所有数字**(我们之前仅仅是通过两个数字进行举例),得到的数就是最小的数字呢?
|
||||
|
||||
下面我们先来证明下规则的有效性
|
||||
|
||||
注:为了便于分辨我们用 A,B,C 表示元素, a,b,c 表示元素用十进制表示时的位数
|
||||
|
||||
(1)自反性:AA = AA,所以 A 等于 A
|
||||
|
||||
(2)对称性:如果 A "小于" B 则 AB < BA,所以 BA > AB 则 B "大于" A
|
||||
|
||||
(3)传递性:传递性的证明稍微有点复杂,大家记得认真阅读。
|
||||
|
||||
如果 A“小于” B,则 AB < BA, 假设 A 和 B 用十进制表示时分别有 a 位和 b 位
|
||||
|
||||
则 AB = A * 10 ^ b + B , BA = B * 10 ^ a + A
|
||||
|
||||
> 例 A = 10, a = 2 (两位数) B = 1, b = 1 (一位数)
|
||||
>
|
||||
> AB = A * 10 ^ b + B = 10 * 10 ^ 1 + 1 = 101
|
||||
>
|
||||
> BA = B * 10 ^ a + A = 1 * 10 ^ 2 + 10 = 110
|
||||
|
||||
AB < BA 则 **A * 10 ^ b + B < BA = B * 10 ^ a + A** 整理得
|
||||
|
||||
A / (10^a - 1) < B / (10 ^ b - 1)
|
||||
|
||||
同理,如果 B “小于” C 则 BC < CB ,C 用十进制表示时有 c 位,和前面推导过程一样
|
||||
|
||||
BC = B * 10 ^ c + C
|
||||
|
||||
CB = C * 10 ^ b + B
|
||||
|
||||
BC < CB 整理得 B / (10 ^ b - 1) < C / (10 ^ c - 1);
|
||||
|
||||
我们通过 A / (10 ^ a - 1) < B / (10 ^ b - 1) ,B / (10 ^ b - 1) < C / (10 ^ c - 1);
|
||||
|
||||
可以得到 A / (10^a - 1) < C / (10 ^ c - 1)
|
||||
|
||||
则可以得到 AC < CA 即 A “小于” C
|
||||
|
||||
传递性证得。
|
||||
|
||||
我们通过上面的证明过程知道了我们定义的规则,满足自反性,对称性,传递性,则说明规则是有效的。
|
||||
|
||||
接下来我们证明,利用这种规则得到的数字,的确是最小的。我们利用反证法来进行证明
|
||||
|
||||
我们先来回顾一下我们之前定义的规则
|
||||
|
||||
> 当 mn < nm 时,得到最小数字 mn, 因为在最小数字 mn 中 ,m 排在 n 的前面,
|
||||
>
|
||||
> 我们此时定义 m "小于" n。
|
||||
|
||||
我们假设我们根据上诉规则得到的数字为 xxxxxxxx
|
||||
|
||||
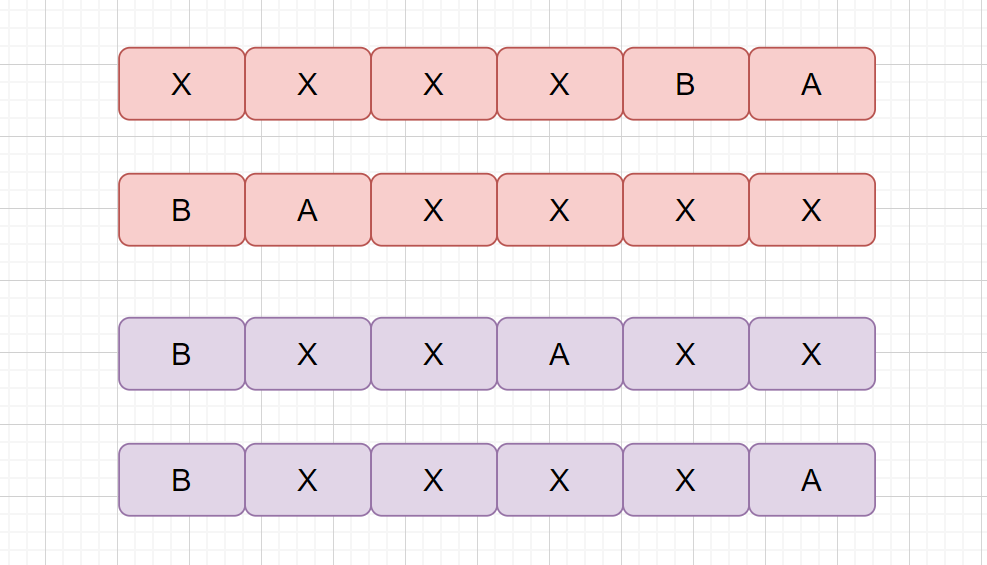
存在这么一对字符串 A B ,虽然 AB < BA, 按照规则 A 应该排在 B 的前面,但是在最后结果中 A 排在 B 的后面。则此时共有这么几种情况
|
||||
|
||||
见下图
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
其实我们可以归结为两大类, B 和 A 之间没有其他值, B 和 A 之间有其他值。
|
||||
|
||||
我们先来看**没有其他值**的情况
|
||||
|
||||
假设我们求得的最小值为 XXXXBA, 虽然 A "小于" B,但是在最后结果中 B 排在了 A 的前面,这和我们之前定义的规则是冲突的,大家思考一下这个值为最小值吗?
|
||||
|
||||
假设 XXXXBA为最小值,但是因为 A "小于" B ,则 AB < BA ,
|
||||
|
||||
所以 XXXXAB 一定小于 XXXXBA 。
|
||||
|
||||
和我们之前的假设矛盾。
|
||||
|
||||
当然 BAXXXX 也一样。
|
||||
|
||||
下面我们来看当 B 和 A 之间有其他值的情况
|
||||
|
||||
即 BXXXXA
|
||||
|
||||
我们可以将 XXXX 看成一个字符串 C,则为 BCA
|
||||
|
||||
因为求得的最小值为 BCA ,
|
||||
|
||||
在最小值 BCA 中 B 在 C 的前面,C 在 A 的前面,
|
||||
|
||||
则 BC < CB, CA < AC,B "小于 C", C “小于” A
|
||||
|
||||
根据我们之前证明的传递性
|
||||
|
||||
则 B "小于" A
|
||||
|
||||
但是我们假设是 A “小于” B ,与假设冲突,证得
|
||||
|
||||
综上所述,得出假设不成立,从而得出结论:对于排成的最小数字,不存在满足下述关系的一对字符串:虽然 A "小于" B , 但是在最后结果中 B 排在了 A 的前面.
|
||||
|
||||
好啦,我们证明我们定义的规则有效下面我们直接看代码吧。继续使用我们的三向切分来解决
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public String minNumber(int[] nums) {
|
||||
String[] arr = new String[nums.length];
|
||||
//解决大数问题,将数字转换为字符串
|
||||
for (int i = 0 ; i < nums.length; ++i) {
|
||||
arr[i] = String.valueOf(nums[i]);
|
||||
}
|
||||
|
||||
quickSort(arr,0,arr.length-1);
|
||||
StringBuffer str = new StringBuffer();
|
||||
|
||||
for (String x : arr) {
|
||||
str.append(x);
|
||||
}
|
||||
return str.toString();
|
||||
}
|
||||
public void quickSort(String[] arr, int left, int right) {
|
||||
if (left >= right) {
|
||||
return;
|
||||
}
|
||||
int low = left;
|
||||
int hight = right;
|
||||
int i = low+1;
|
||||
String pivot = arr[low];
|
||||
|
||||
while (i <= hight) {
|
||||
//比较大小
|
||||
if ((pivot+arr[i]).compareTo(arr[i]+pivot) > 0 ) {
|
||||
swap(arr,i++,low++);
|
||||
} else if ((pivot+arr[i]).compareTo(arr[i]+pivot) < 0) {
|
||||
swap(arr,i,hight--);
|
||||
} else {
|
||||
i++;
|
||||
}
|
||||
}
|
||||
|
||||
quickSort(arr,left,low-1);
|
||||
quickSort(arr,hight+1,right);
|
||||
|
||||
}
|
||||
public void swap(String[] arr, int i, int j) {
|
||||
String temp = arr[i];
|
||||
arr[i] = arr[j];
|
||||
arr[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
259
gif-algorithm/数据结构和算法/堆排序.md
Normal file
259
gif-algorithm/数据结构和算法/堆排序.md
Normal file
@@ -0,0 +1,259 @@
|
||||
### **堆排序**
|
||||
|
||||
说堆排序之前,我们先简单了解一些什么是堆?堆这种数据结构应用场景非常多,所以我们需要熟练掌握呀!
|
||||
|
||||
那我们了解堆之前,先来简单了解下,什么是完全二叉树?
|
||||
|
||||
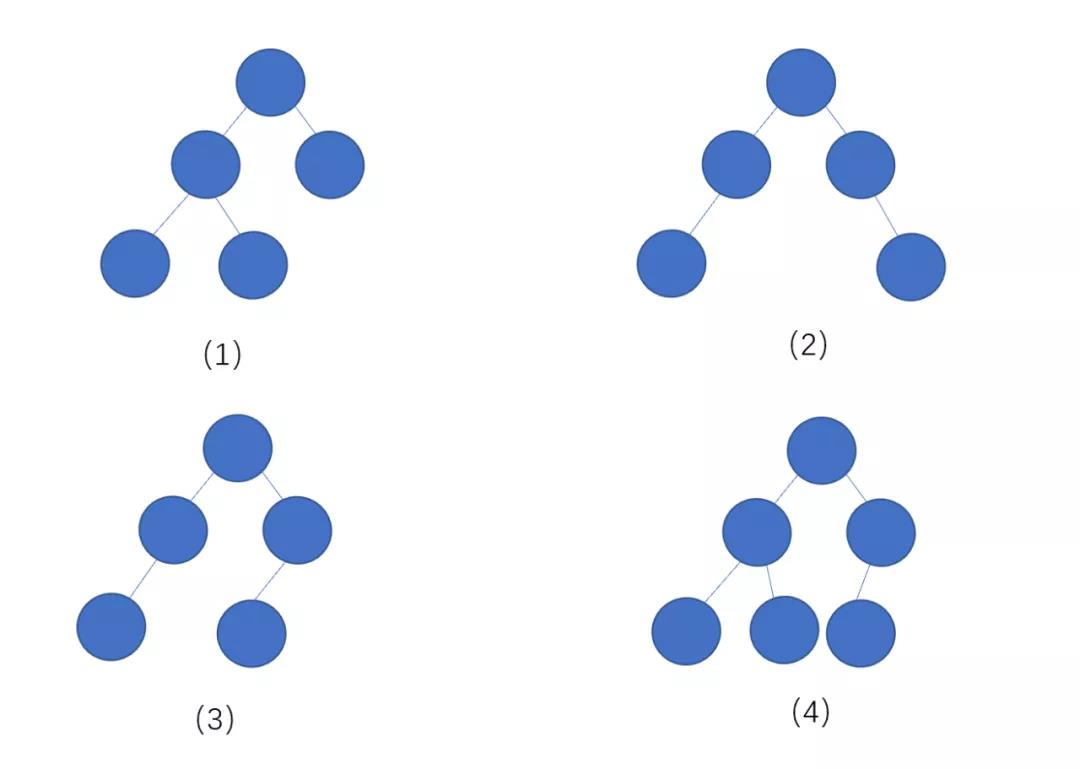
我们来看下百度百科的定义,完全二叉树:叶子结点只能出现在最下层和次下层,且最下层的叶子结点集中在树的左部。
|
||||
|
||||
哦!我们可以这样理解,除了最后一层,其他层的节点个数都是满的,而且最后一层的叶子节点必须靠左。
|
||||
|
||||
下面我们来看一下这几个例子
|
||||
|
||||
|
||||
|
||||
上面的几个例子中,(1)(4)为完全二叉树,(2)(3)不是完全二叉树,通过上面的几个例子,我们了解了什么是完全二叉树,
|
||||
|
||||
那么堆到底是什么呢?
|
||||
|
||||
下面我们来看一下二叉堆的要求
|
||||
|
||||
(1)必须是完全二叉树
|
||||
|
||||
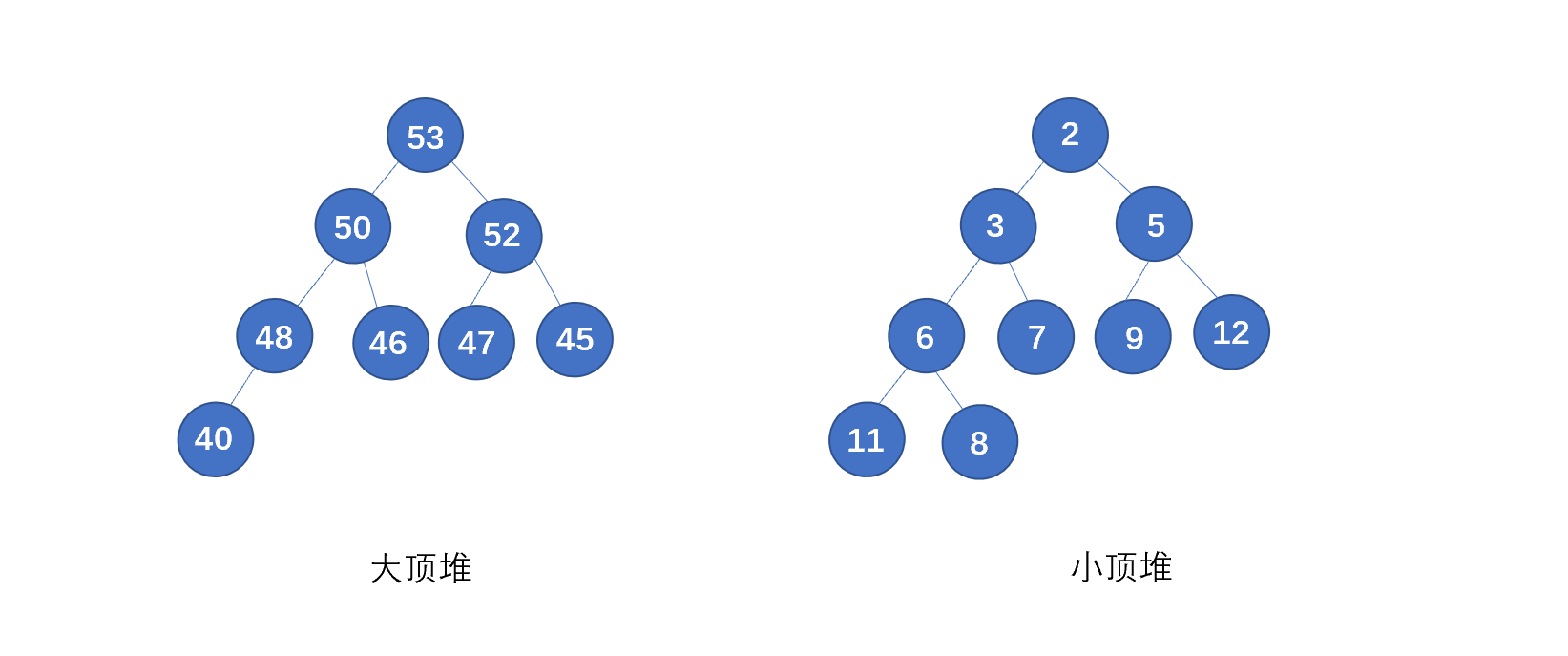
(2)二叉堆中的每一个节点,都必须大于等于(或小于等于)其子树中每个节点的值。
|
||||
|
||||
若是每个节点大于等于子树中的每个节点,我们称之为大顶堆,小于等于子树中的每个节点,我们则称之为小顶堆。见下图
|
||||
|
||||
下面我们再来看一下二叉堆的具体例子。
|
||||
|
||||
|
||||
|
||||
上图则为大顶堆和小顶堆,我们再来回顾一下堆的要求,看下是否符合
|
||||
|
||||
(1)必须是完全二叉树
|
||||
|
||||
(2)堆中的每一个节点,都必须大于等于(或小于等于)其子树中每个节点的值。
|
||||
|
||||
好啦,到这里我们已经完全掌握二叉堆了,那么二叉堆又是怎么存储的呢?因为堆是完全二叉树,所以我们完全可以用数组存储。具体思想见下图,我们仅仅按照顺序将节点存入数组即可,我们通过小顶堆进行演示。
|
||||
|
||||
注:我们是从下标 1 开始存储的,这样能省略一些计算,下文中我们将二叉堆简称为堆
|
||||
|
||||
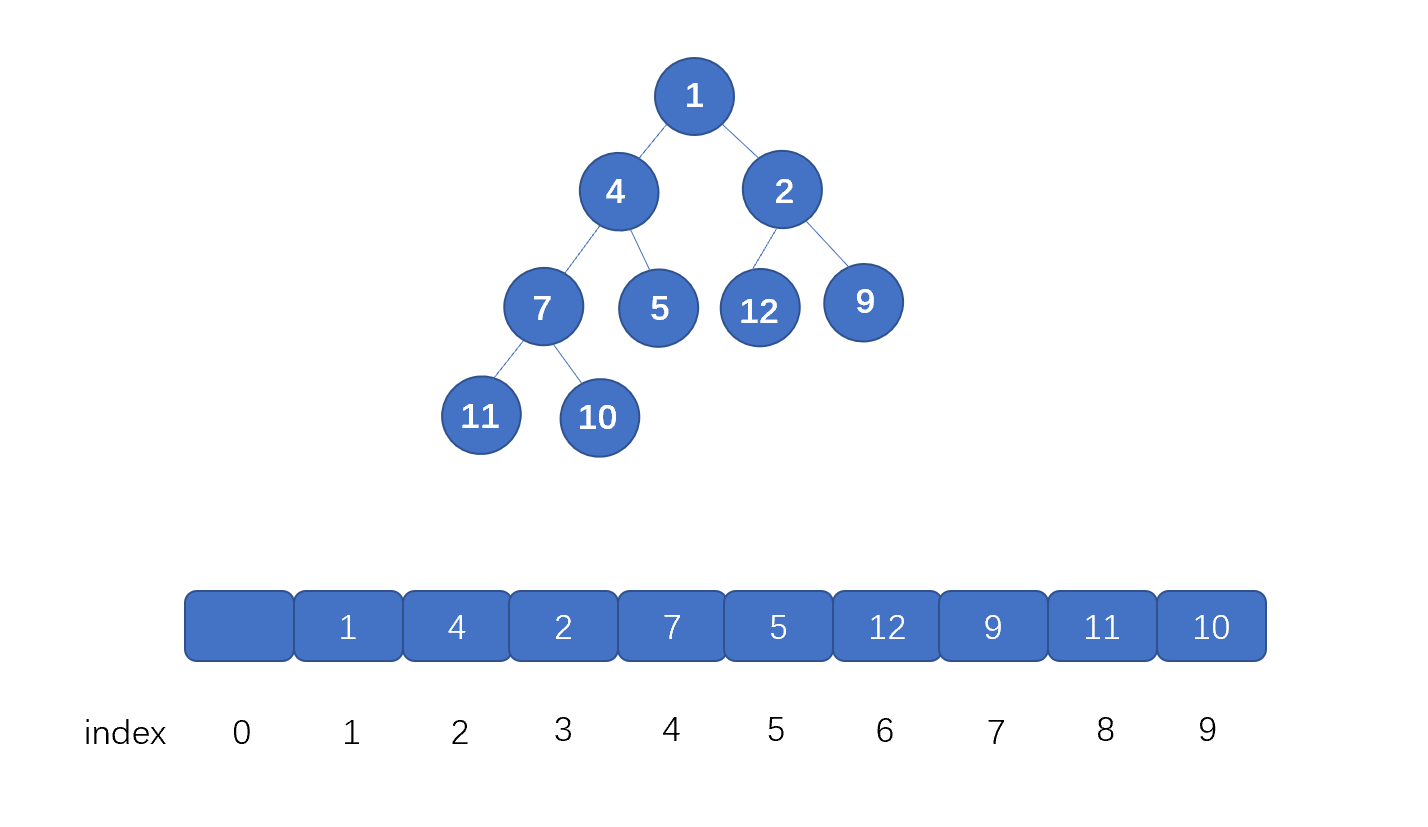
|
||||
|
||||
|
||||
|
||||
我们来看一下为什么我们可以用数组来存储堆呢?
|
||||
|
||||
我们首先看根节点,也就是值为 1 的节点,它在数组中的下标为 1 ,它的左子节点,也就是值为 4 的节点,此时索引为 2,右子节点也就是值为 2 的节点,它的索引为 3。
|
||||
|
||||
我们发现其中的关系了吗?
|
||||
|
||||
数组中,某节点(非叶子节点)的下标为 i , 那么其**左子节点下标为 2*i** (这里可以直接通过相乘得到左孩子,如果从0 开始存,需要 2*i+1 才行), 右子节点为 2*i+1**,**其父节点为 i/2 。既然我们完全可以根据索引找到某节点的 **左子节点** 和 **右子节点**,那么我们用数组存储是完全没有问题的。
|
||||
|
||||
好啦,我们知道了什么是堆和如何用数组存储堆,那我们如何完成堆排序呢?
|
||||
|
||||
堆排序其实主要有两个步骤
|
||||
|
||||
- 建堆
|
||||
- 排序
|
||||
|
||||
下面我们先来了解下建堆
|
||||
|
||||
我们刚才说了用数组来存储大顶(小顶)堆,此时的元素已经满足某节点大于等于(或小于等于)子树节点,但是随机给我们一个数组,此时并不一定满足上诉要求,所以我们需要调整数组,使其满足大顶堆或小顶堆的要求。这个就是堆化,也可以称其为建堆。
|
||||
|
||||
建堆我们这里提出两种方法,利用上浮操作,也就是不断插入元素进行建堆,另一种是利用下沉操作,遍历父节点,不断将其下沉,进行建堆,我们一起来看吧。
|
||||
|
||||
我们先来说下第一种建堆方式
|
||||
|
||||
**利用上浮操作建堆**
|
||||
|
||||
说之前我们先来了解下,如何往已经建好的堆里,插入新的元素,我们直接看例子吧,一下就懂啦。
|
||||
|
||||
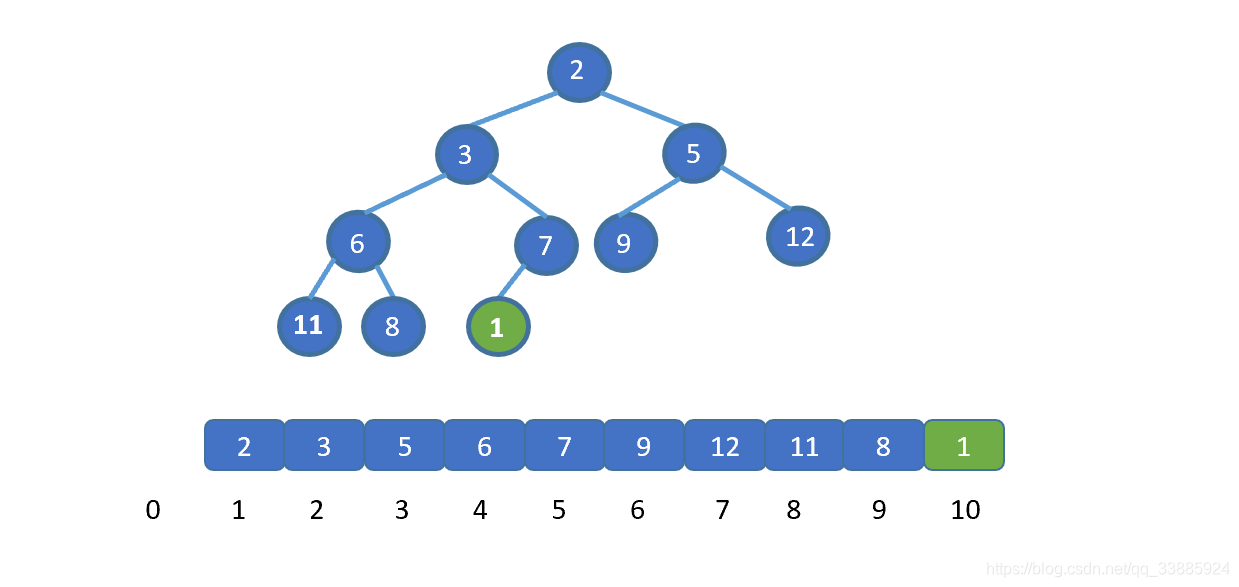
|
||||
|
||||
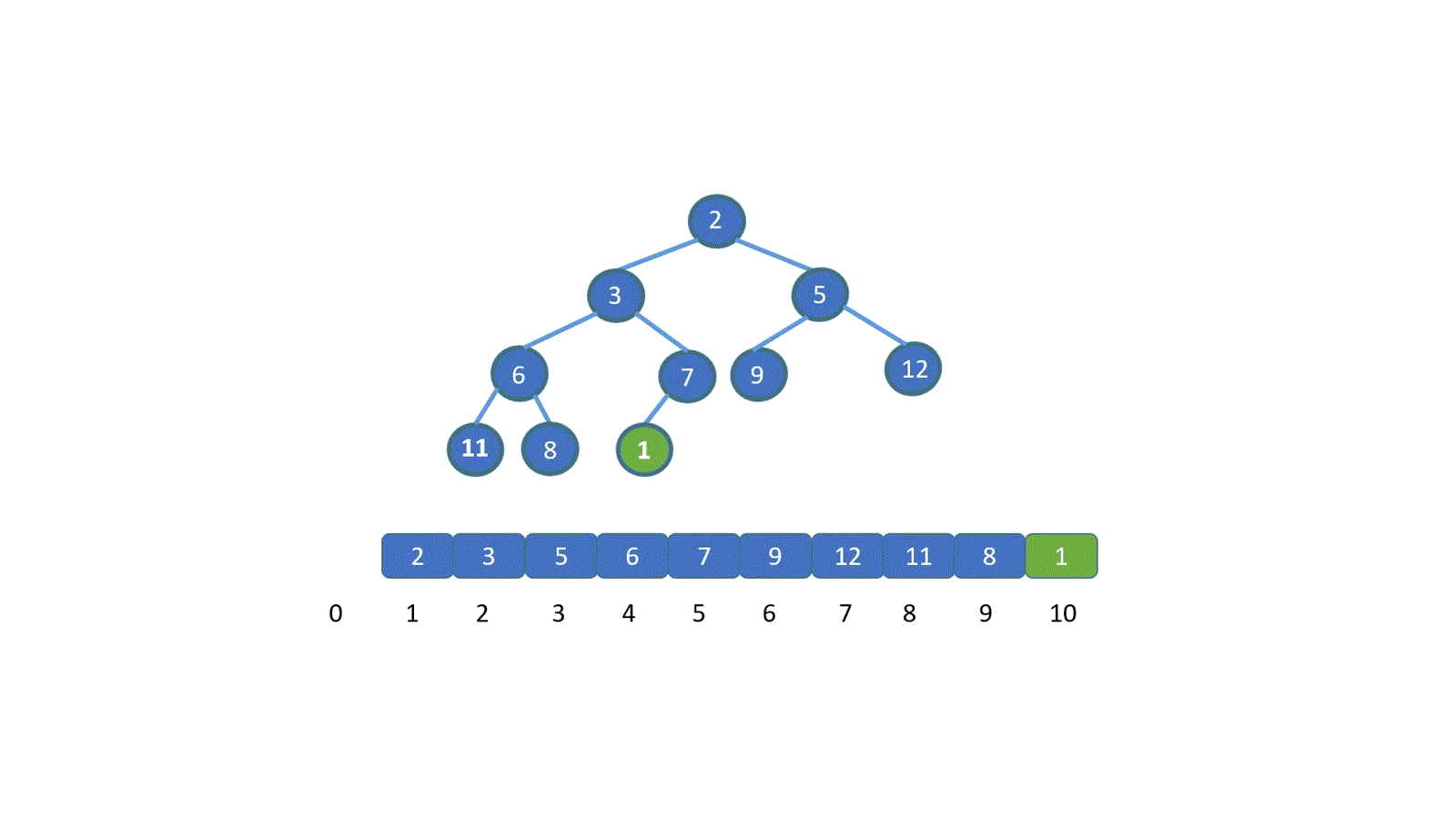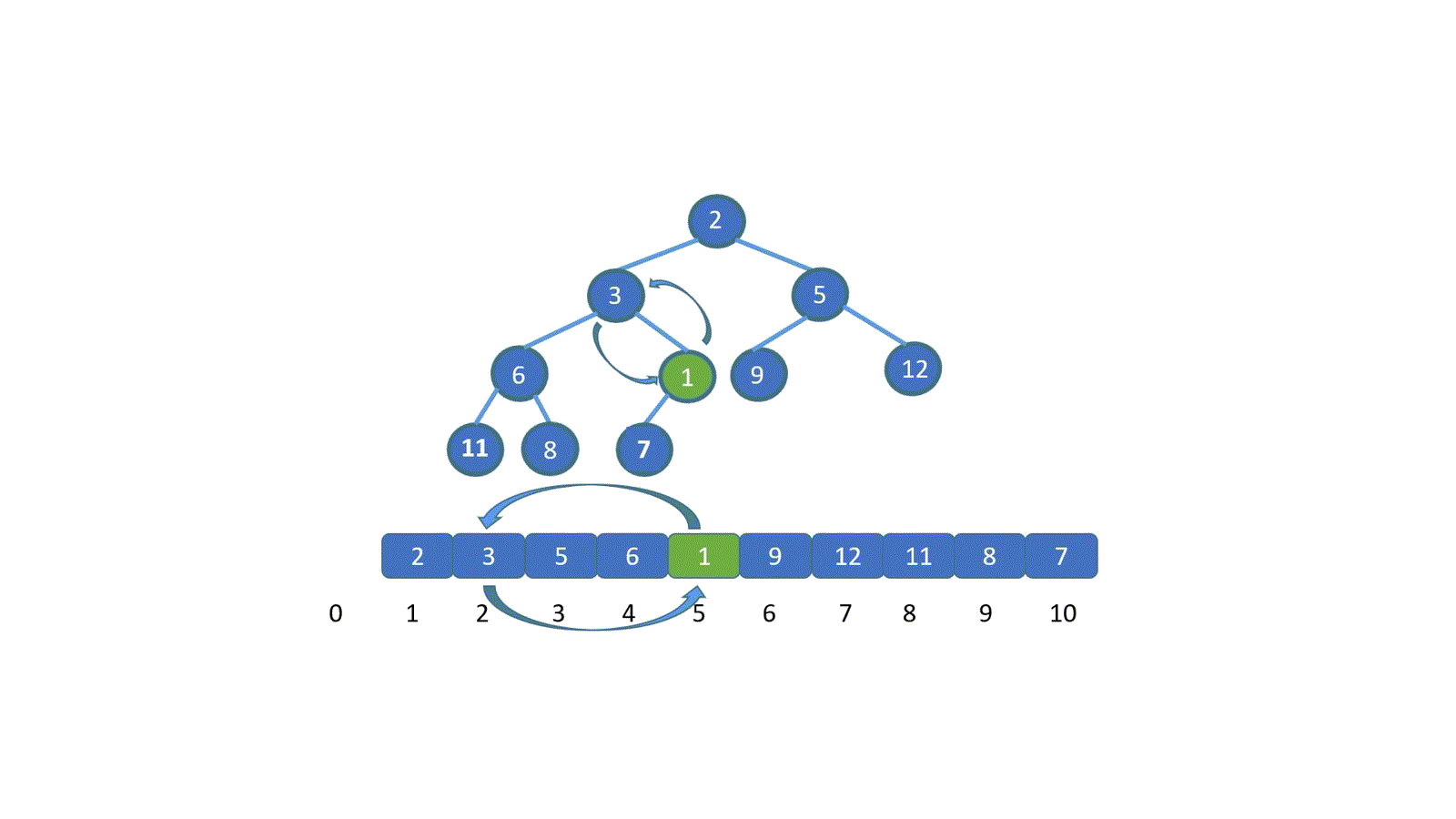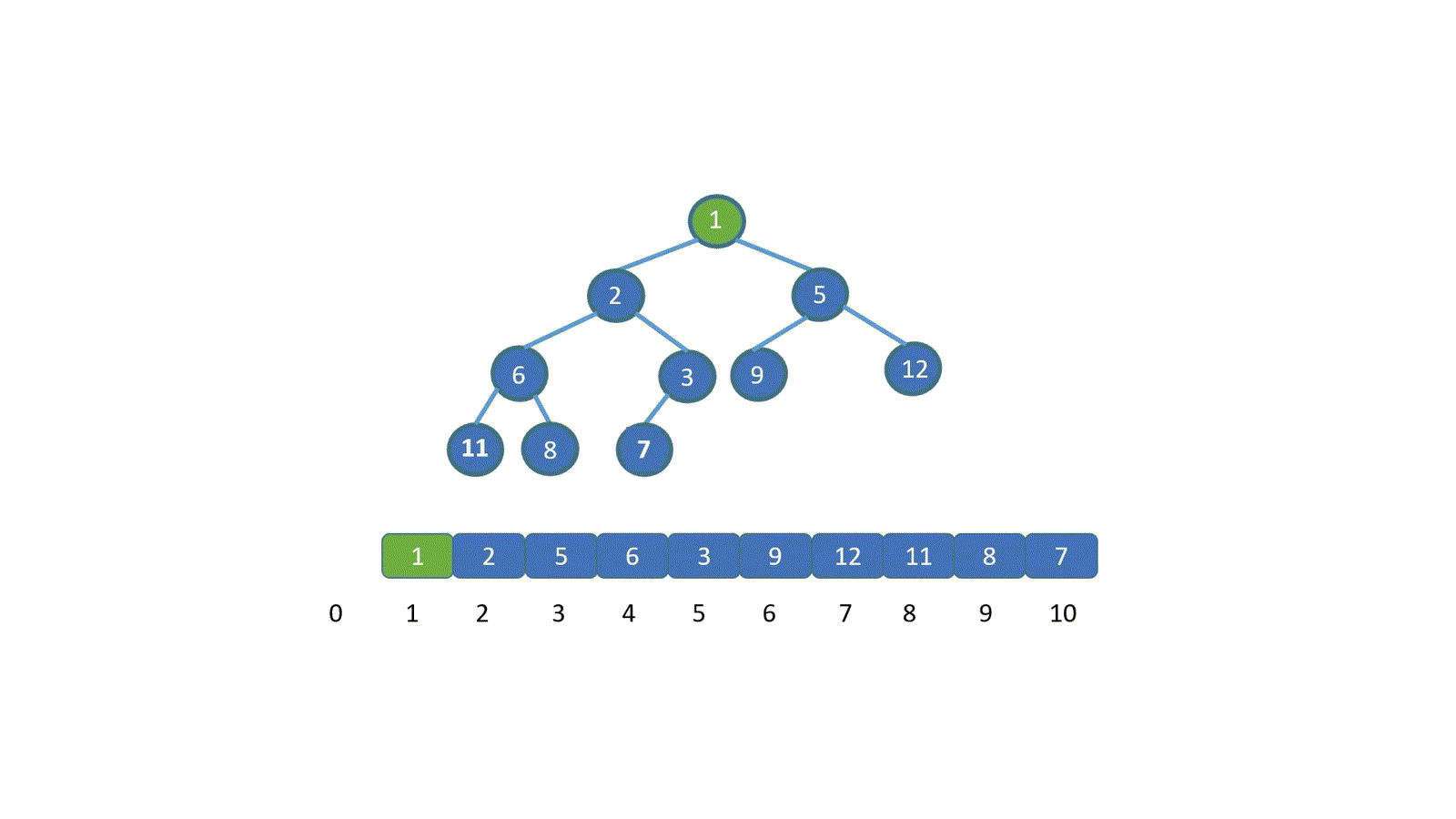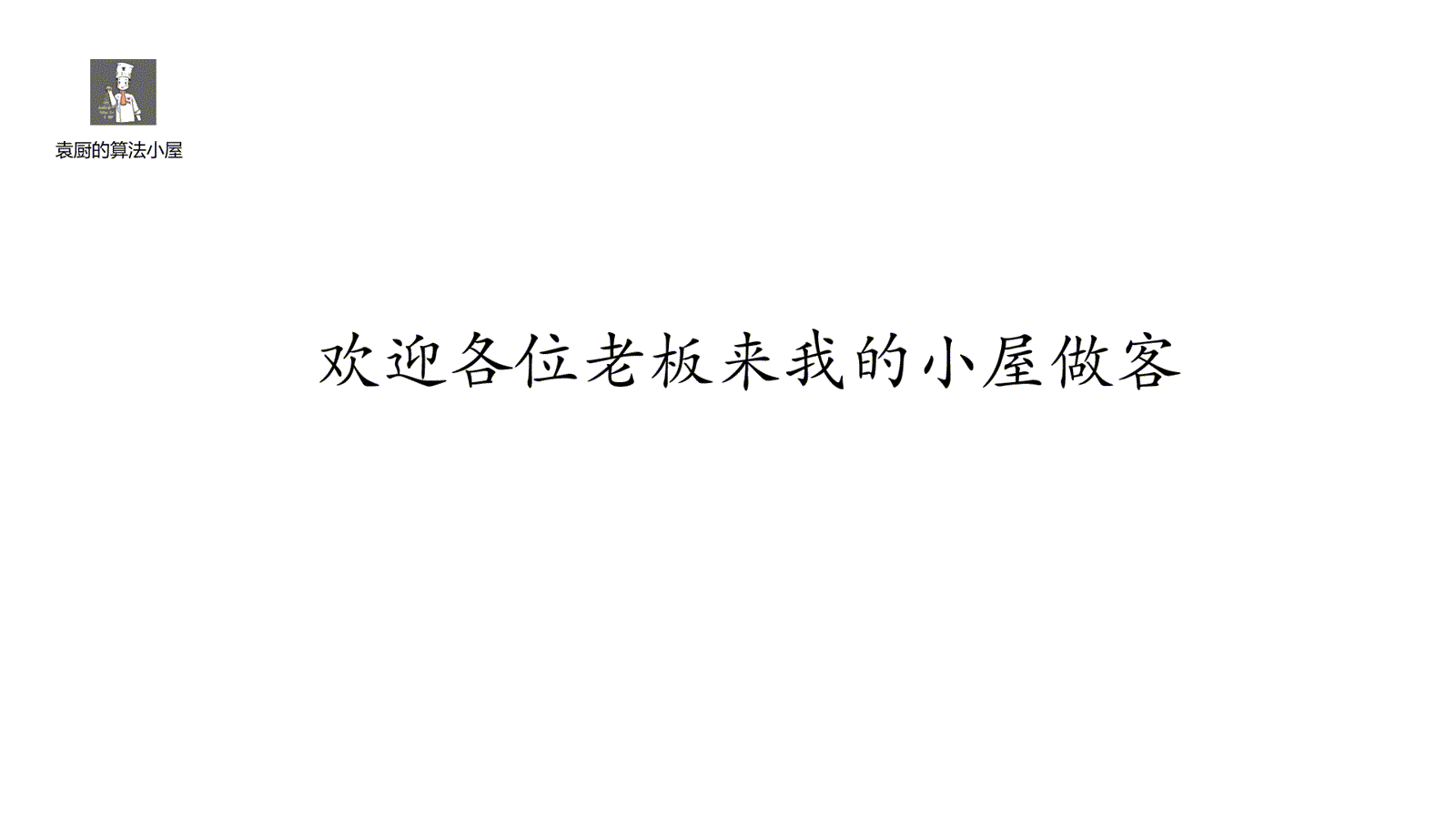
假设让我们插入新的元素 1 (绿色节点),我们发现此时 1 小于其父节点 的值 7 ,并不遵守小顶堆的规则,那我们则需要移动元素 1 。让 1 与 7 交换,(如果新插入元素大于父节点的值,则说明插入新节点后仍满足小顶堆规则,无需交换)。
|
||||
|
||||
之前我们说过,我们可以用数组保存堆,并且可以通过 i/2 得到其父节点的值,那么此时我们就明白怎么做啦。
|
||||
|
||||
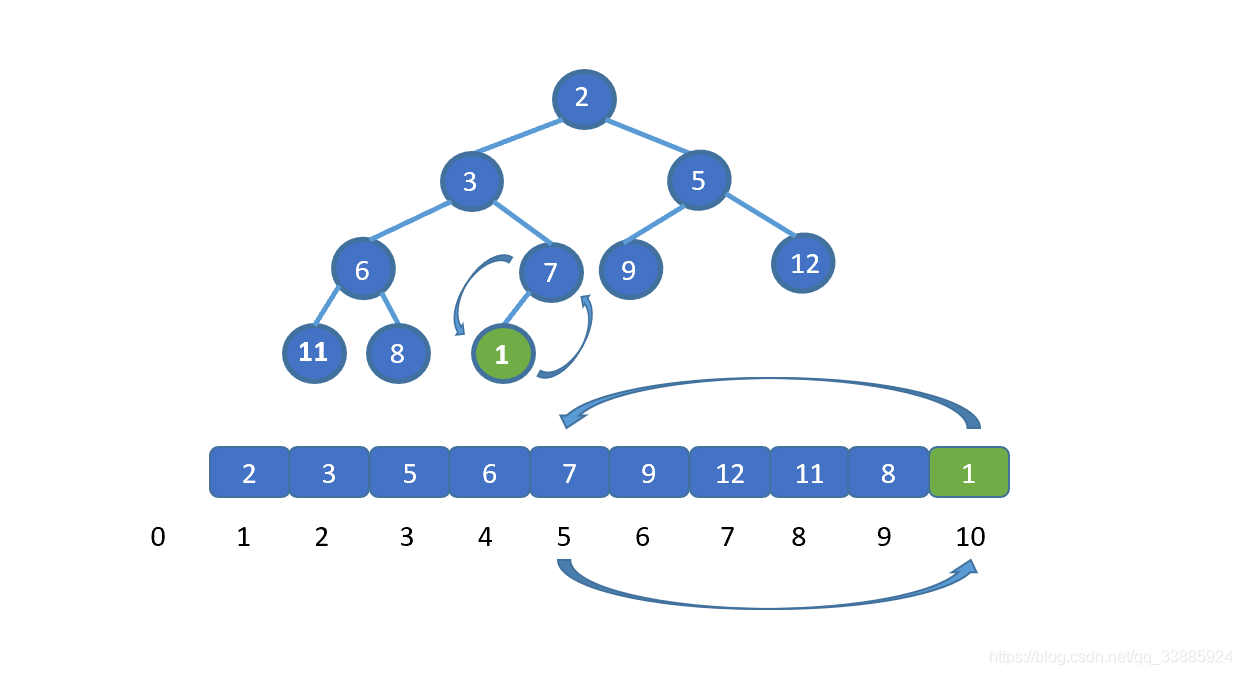
|
||||
|
||||
将插入节点与其父节点,交换。
|
||||
|
||||
|
||||
|
||||
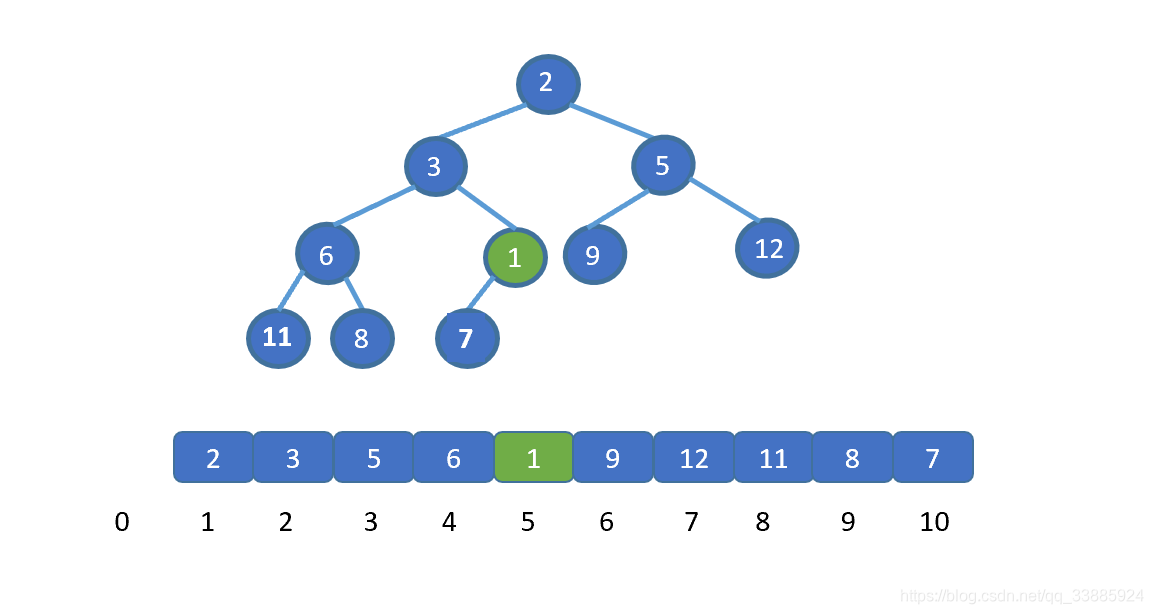
交换之后,我们继续将新插入元素,也就是 1 与其父节点比较,如果大于其父节点,则无需交换,循环结束。若小于则需要继续交换,直到 1 到达适合他的地方。大家是不是已经直到该怎么做啦!下面我们直接看动图吧。
|
||||
|
||||
|
||||
|
||||
看完动图是不是就妥了,其实很简单,我们只需将新加入元素与其父节点比较,判断是否小于堆顶元素(小顶堆),如果小于则进行交换,(让更小的节点为父节点)直到符合堆的规则位置,大顶堆则相反。
|
||||
|
||||
**我们发现,我们新插入的元素是不是一层层的上浮,直到找到属于自己的位置,我们将这个操作称之为上浮操作。**
|
||||
|
||||
那我们知道了上浮,岂不是就可以实现建堆了?是的,我们则可以依次遍历数组,就好比不断往堆中插入新元素,直至遍历结束,这样我们就完成了建堆,这种方法当然是可以的。
|
||||
|
||||
我们一起来看一下上浮操作代码。
|
||||
|
||||
```java
|
||||
public void swim (int index) {
|
||||
while (index > 1 && nums[index/2] > nums[index]) {
|
||||
swap(index/2,index);//交换
|
||||
index = index/2;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
既然利用上浮操作建堆已经搞懂啦,那么我们再来了解一下,利用下沉操作建堆吧,也很容易理解。
|
||||
|
||||
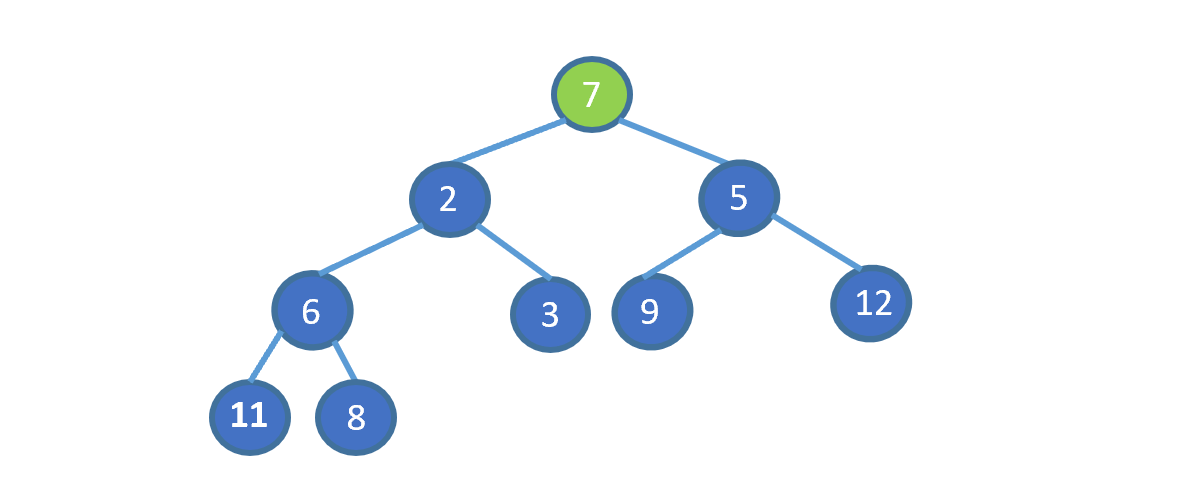
给我们一个无序数组(不满足堆的要求),见下图
|
||||
|
||||
|
||||
|
||||
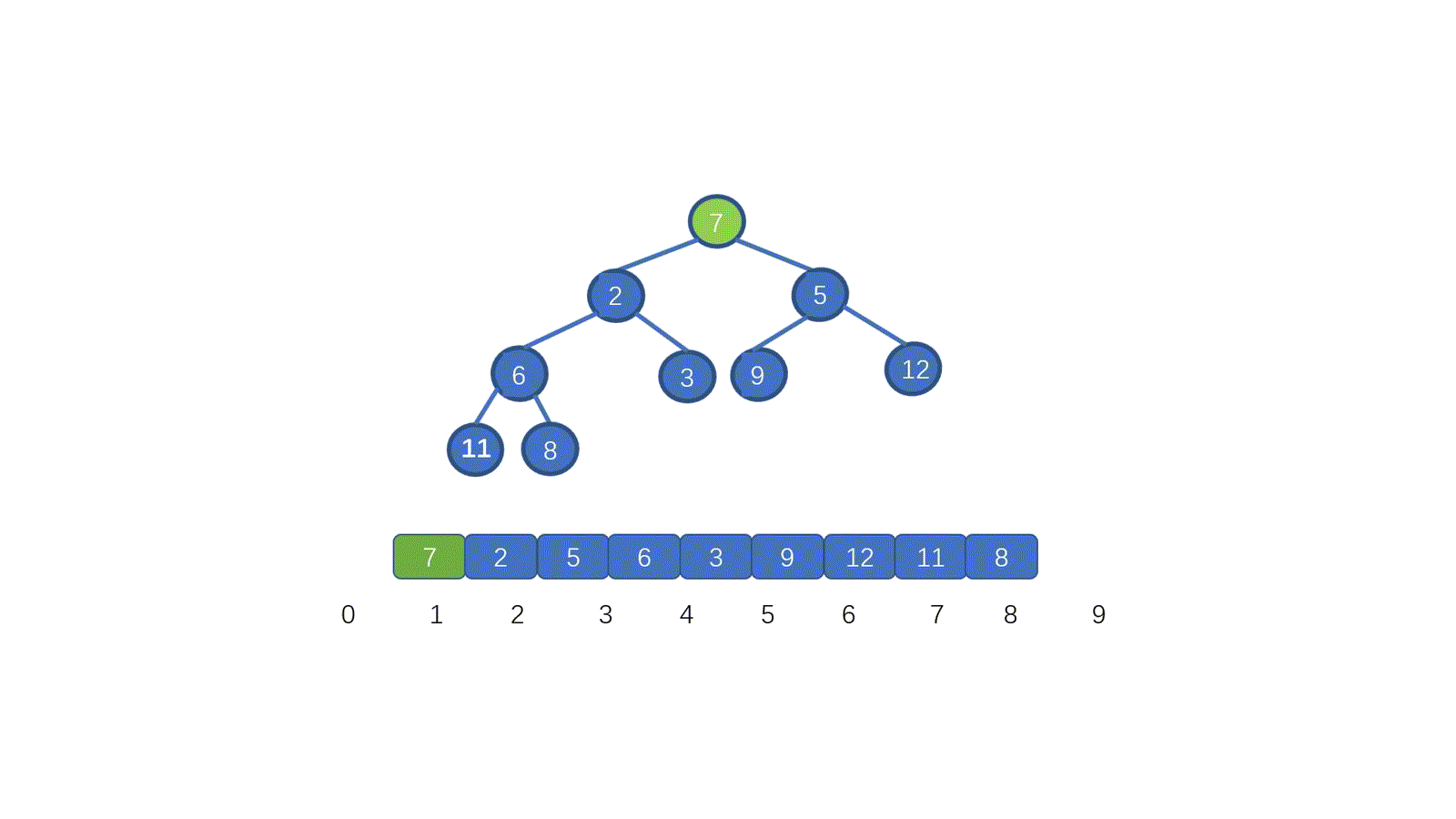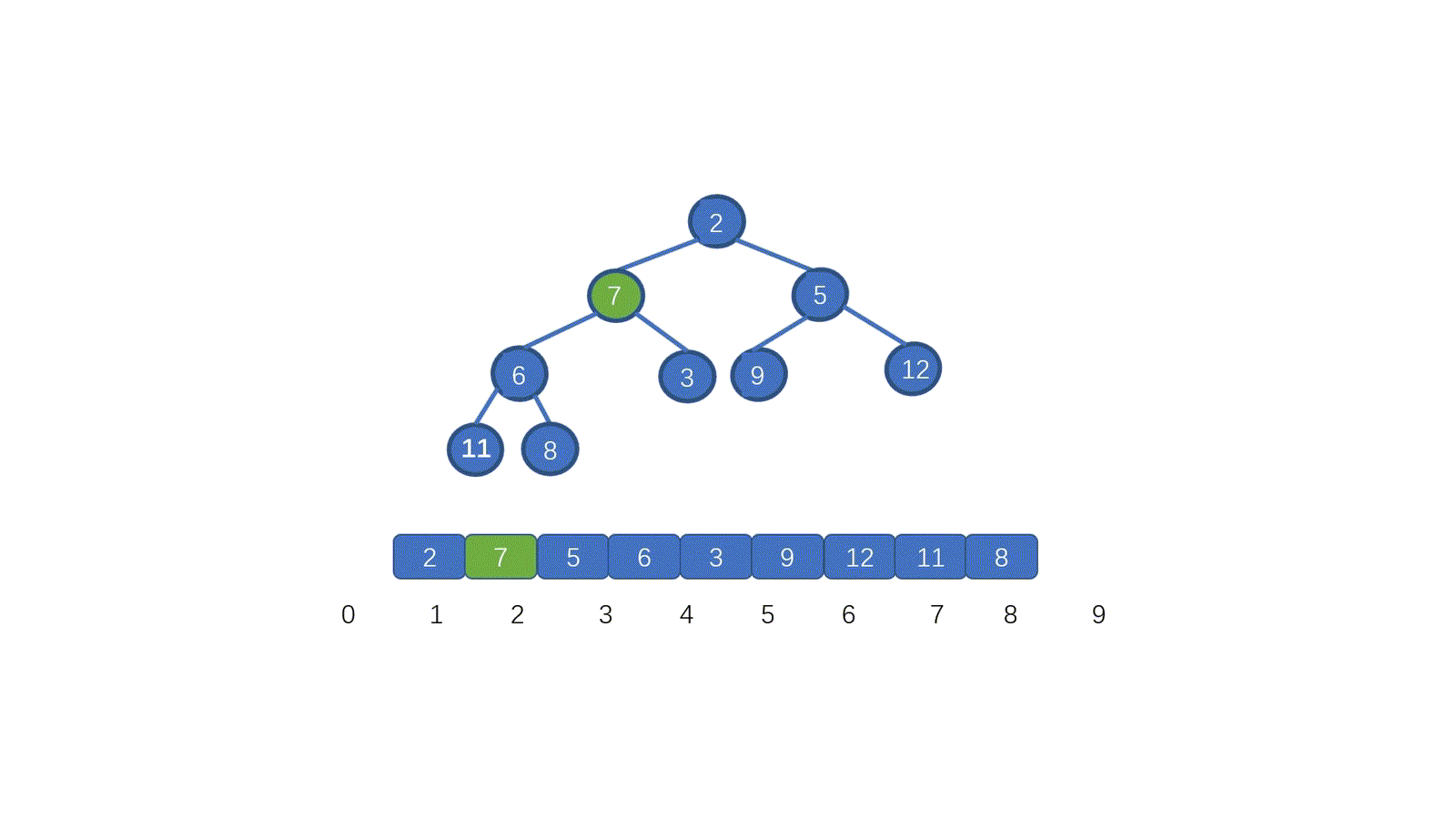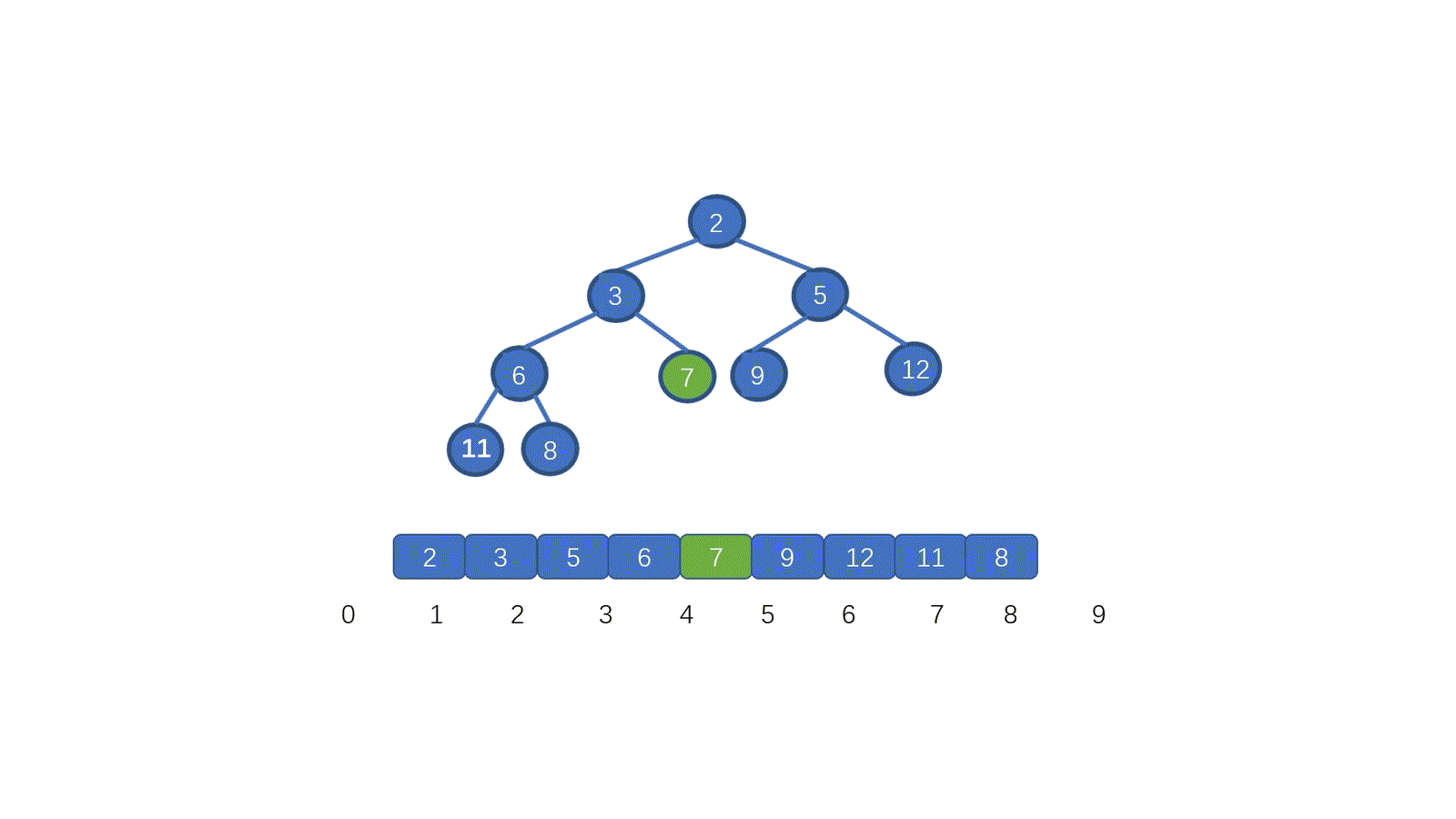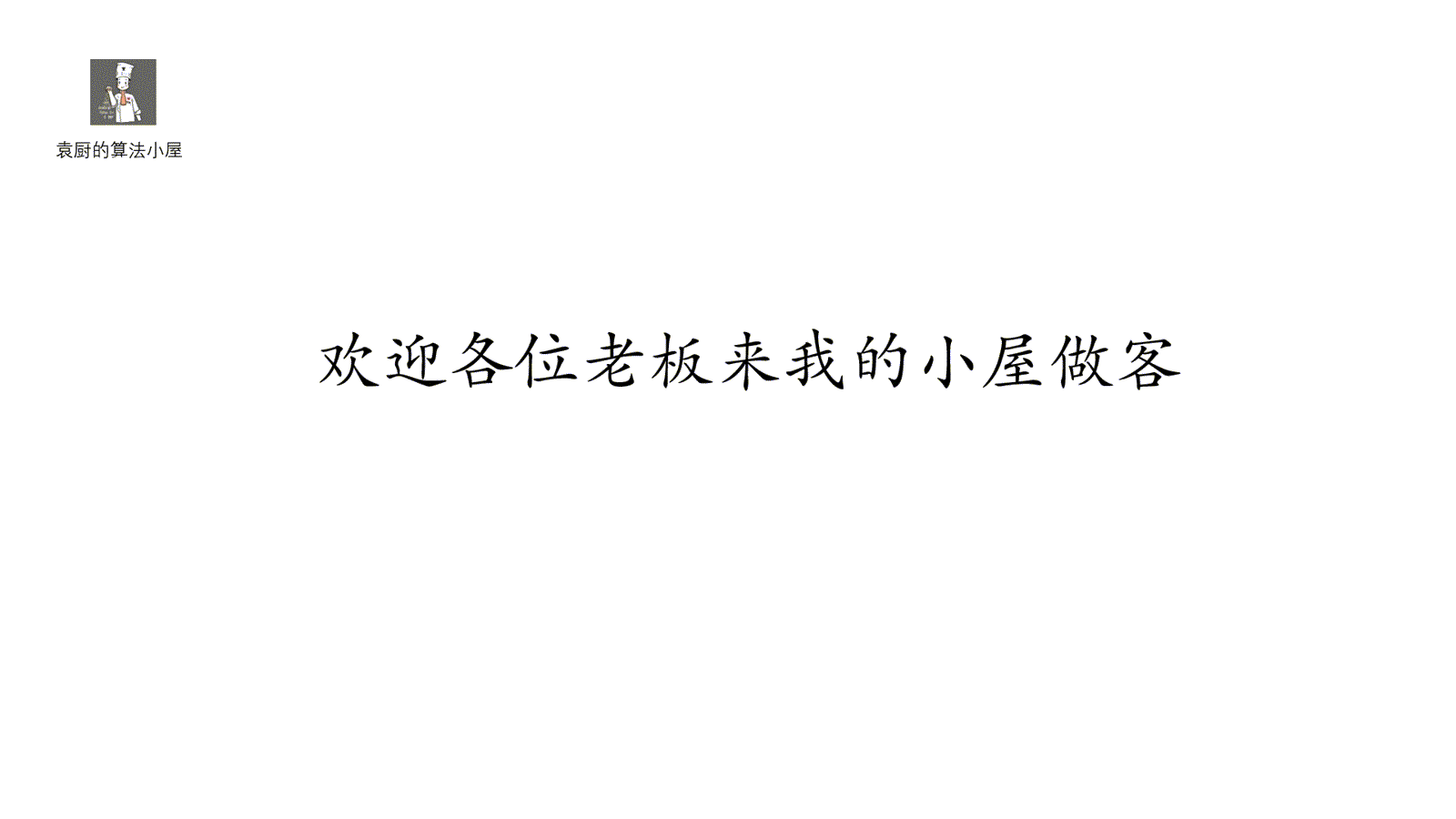
我们发现,7 位于堆顶,但是此时并不满足小顶堆的要求,我们需要把 7 放到属于它的位置,我们应该怎么做呢?
|
||||
|
||||
废话不多说,我们先来看视频模拟,看完保准可以懂
|
||||
|
||||
|
||||
|
||||
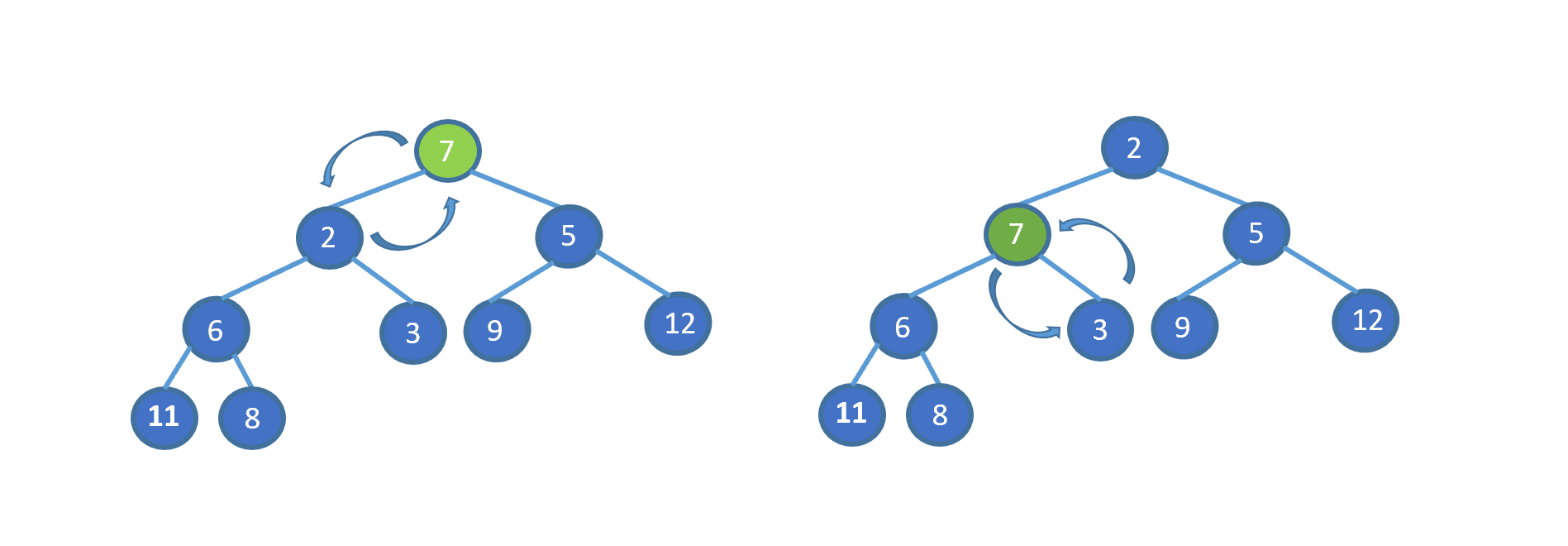
看完视频是不是懂个大概了,但是不知道大家有没有注意到这个地方。为什么 7 第一次与其左孩子节点 2 交换,第二次与右孩子节点 3 交换。见下图
|
||||
|
||||
|
||||
|
||||
其实很容易理解,我们需要与孩子节点中最小的那个交换,因为我们需要交换后,父节点小于两个孩子节点,如果我们第一步,7 与 5 进行交换的话,则同样不能满足小顶堆。
|
||||
|
||||
那我们怎么判断节点找到属于它的位置了呢?主要有两个情况
|
||||
|
||||
- 待下沉元素小于(大于)两个子节点,此时符合堆的规则,无序下沉,例如上图中的 6
|
||||
- 下沉为叶子节点,此时没有子节点,例如 7 下沉到最后变成了叶子节点。
|
||||
|
||||
我们将上面的操作称之为下沉操作。
|
||||
|
||||
这时我们又有疑问了,下沉操作我懂了,但是这跟建堆有个锤子关系啊!
|
||||
|
||||
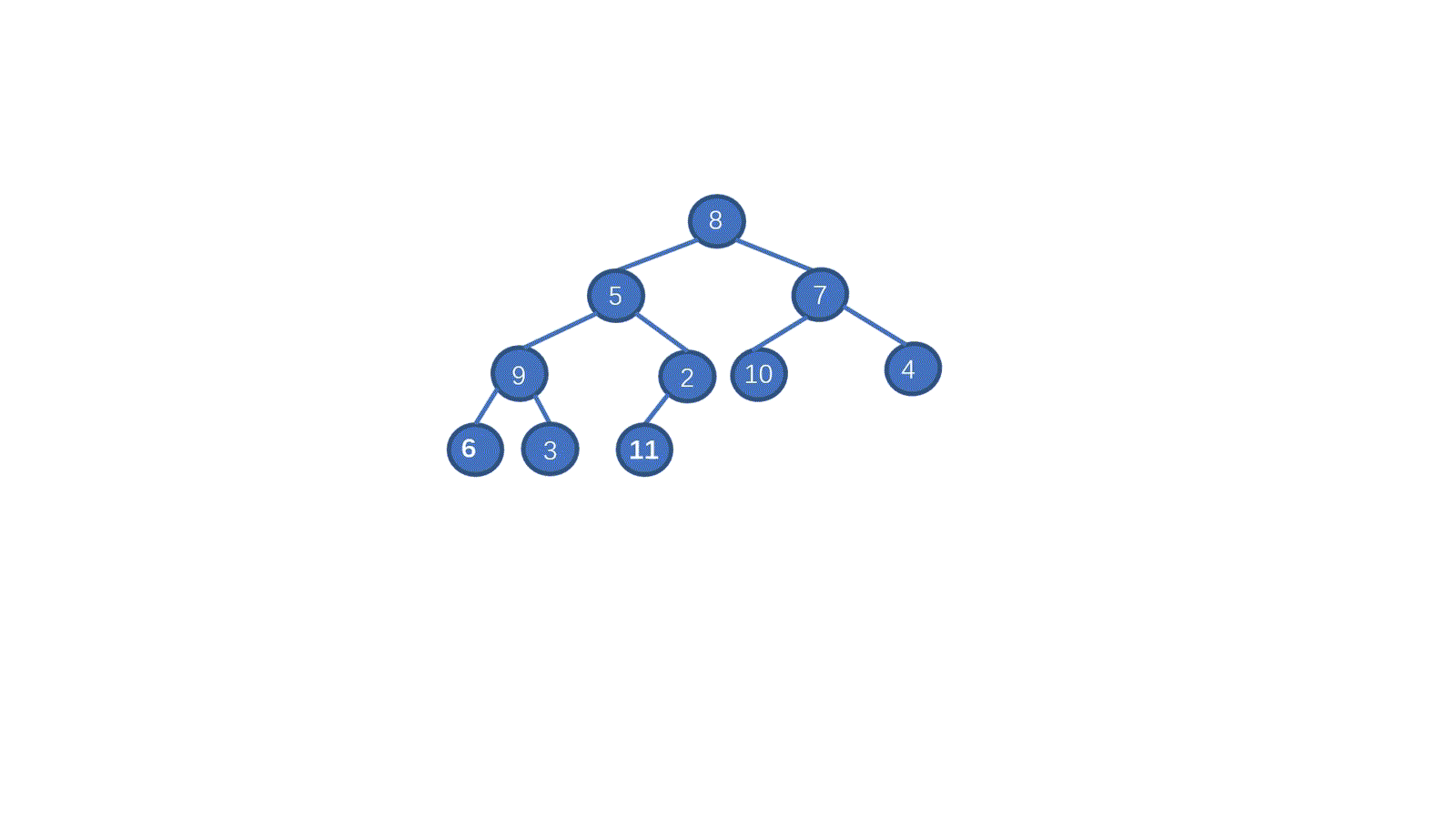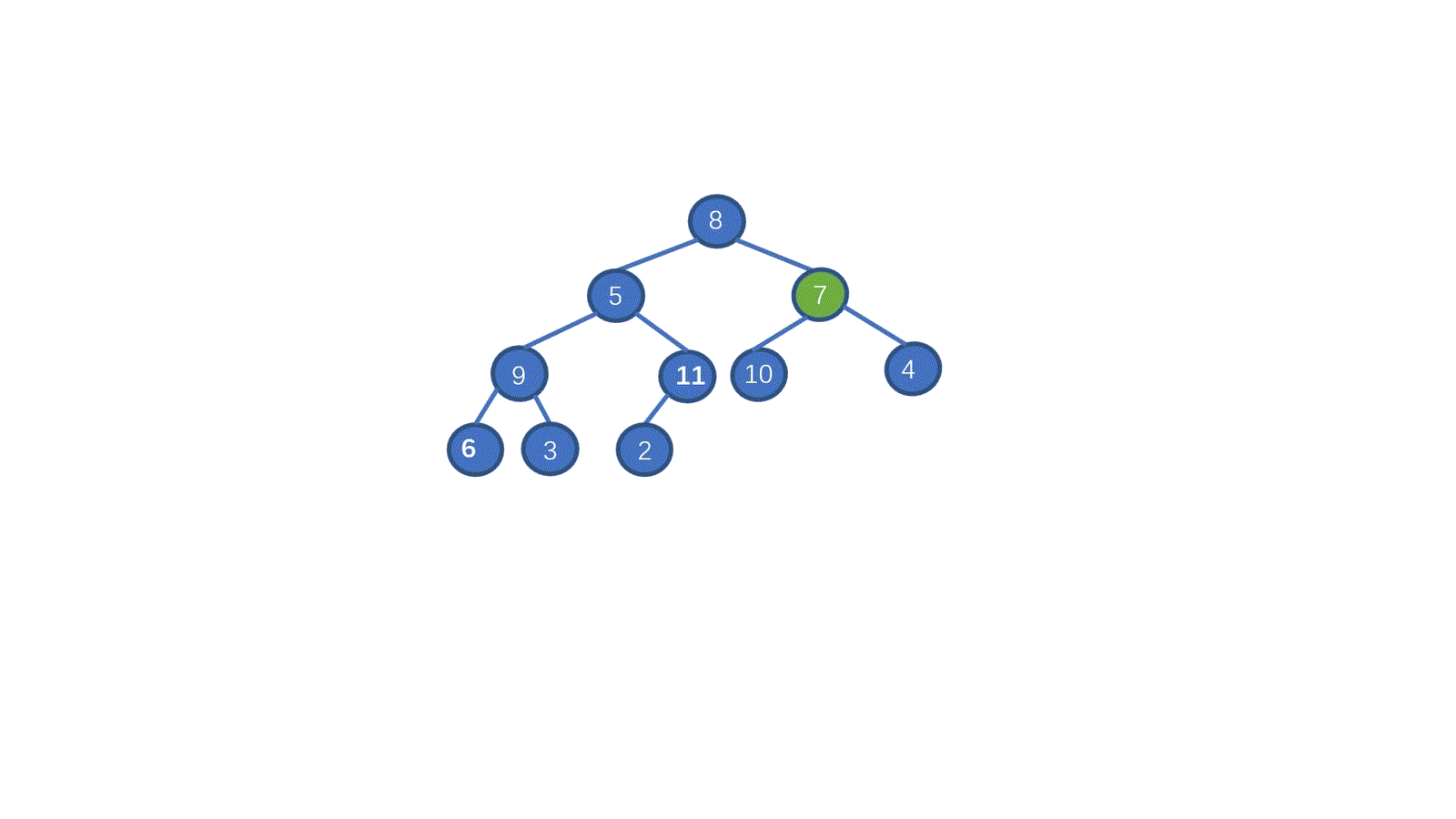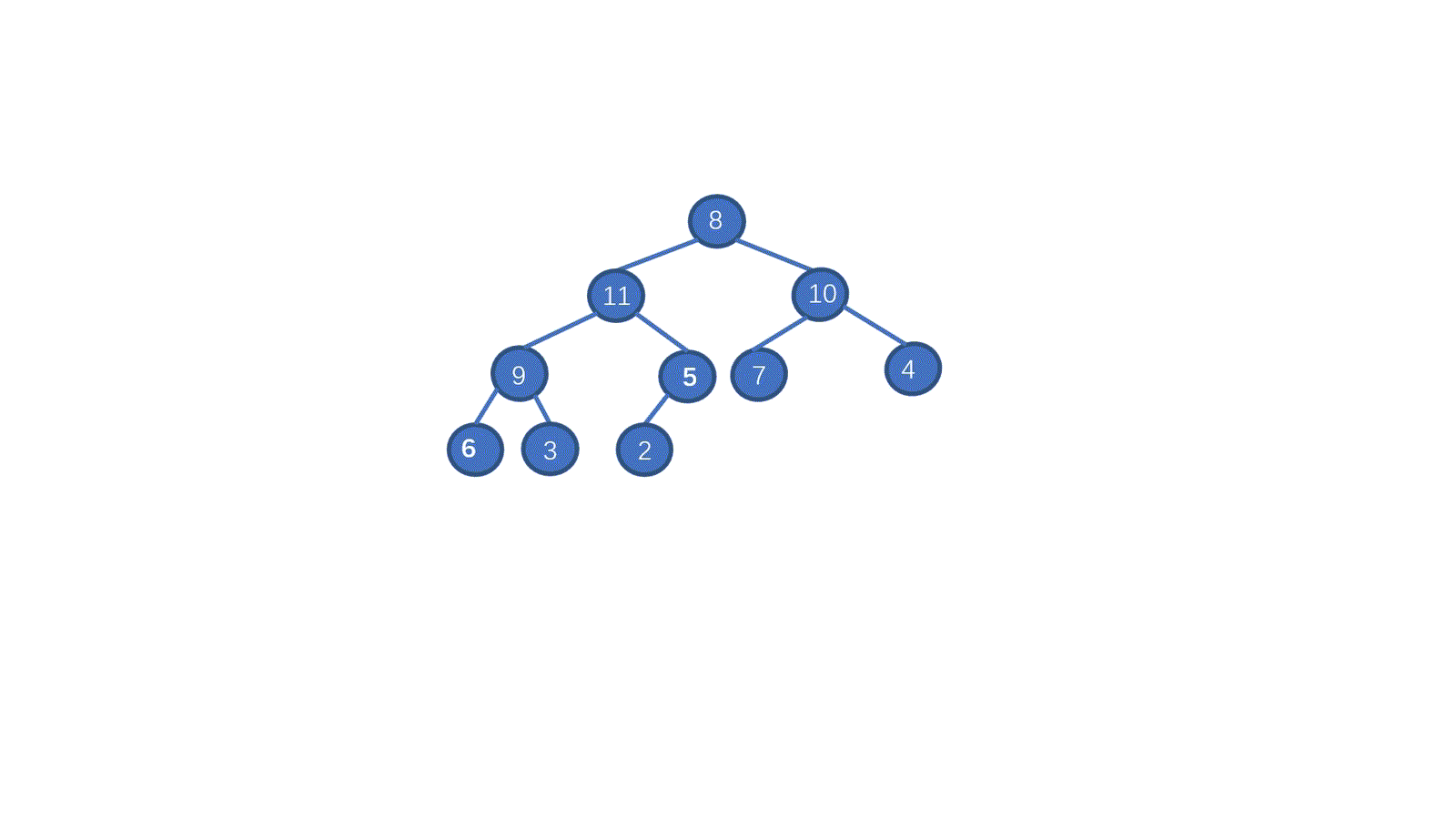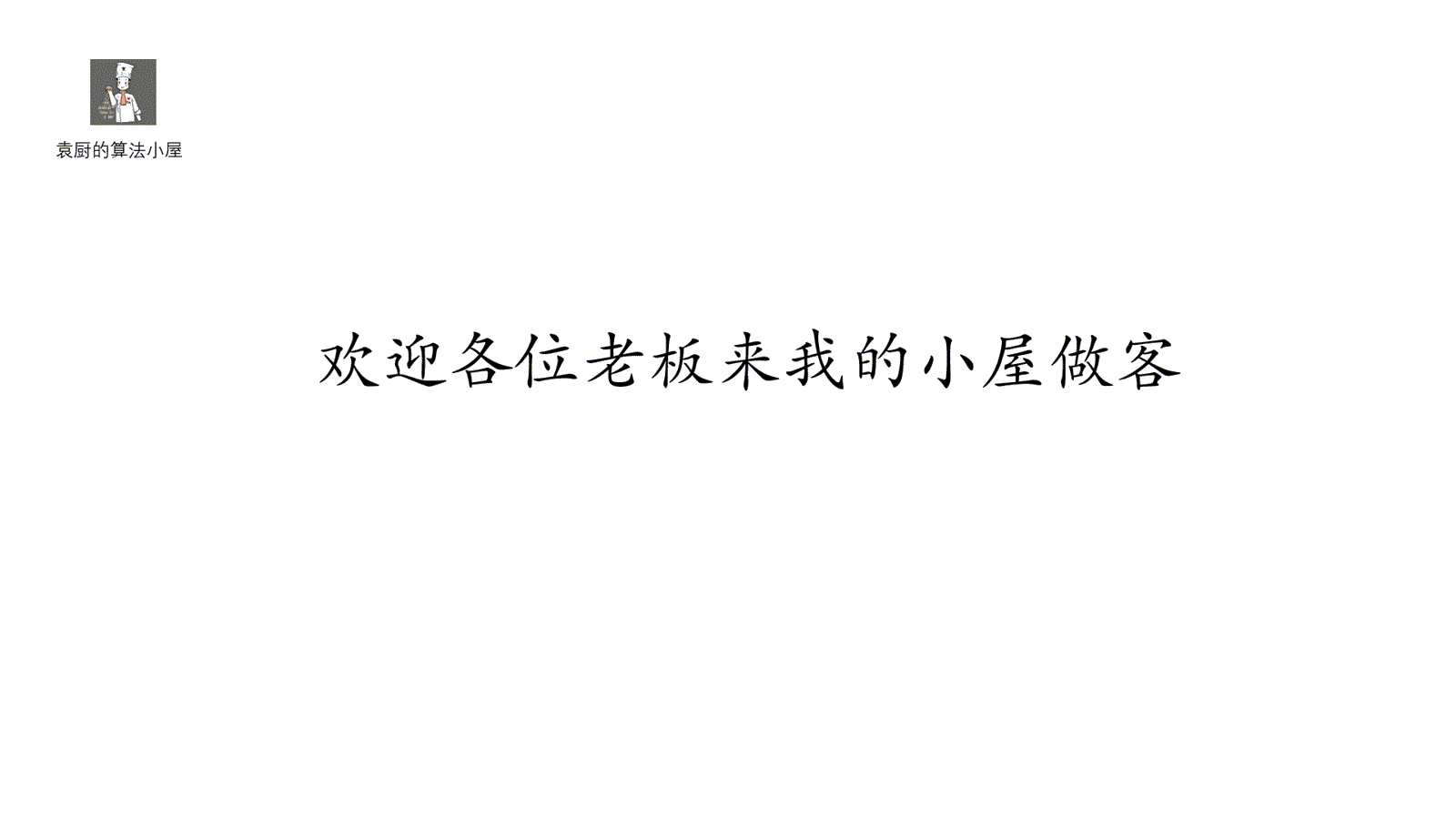
不要急,我们继续来看视频,这次我们通过下沉操作建个大顶堆。
|
||||
|
||||
> **初始数组 [8,5,7,9,2,10,1,4,6,3]**
|
||||
|
||||
|
||||
|
||||
我们一起来拆解一下视频,我们只需要从最后一个非叶子节点开始,依次执行下沉操作。执行完毕后我们就能够完成堆化。是不是一下就懂了呀。
|
||||
|
||||
好啦我们一起看哈下沉操作的代码吧。
|
||||
|
||||
```java
|
||||
public void sink (int[] nums, int index,int len) {
|
||||
while (true) {
|
||||
//获取子节点
|
||||
int j = 2 * index;
|
||||
if (j < len-1 && nums[j] < nums[j+1]) {
|
||||
j++;
|
||||
}
|
||||
//交换操作,父节点下沉,与最大的孩子节点交换
|
||||
if (j < len && nums[index] < nums[j]) {
|
||||
swap(nums,index,j);
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
//继续下沉
|
||||
index = j;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
好啦,两种建堆方式我们都已经了解啦,那么我们如何进行排序呢?
|
||||
|
||||
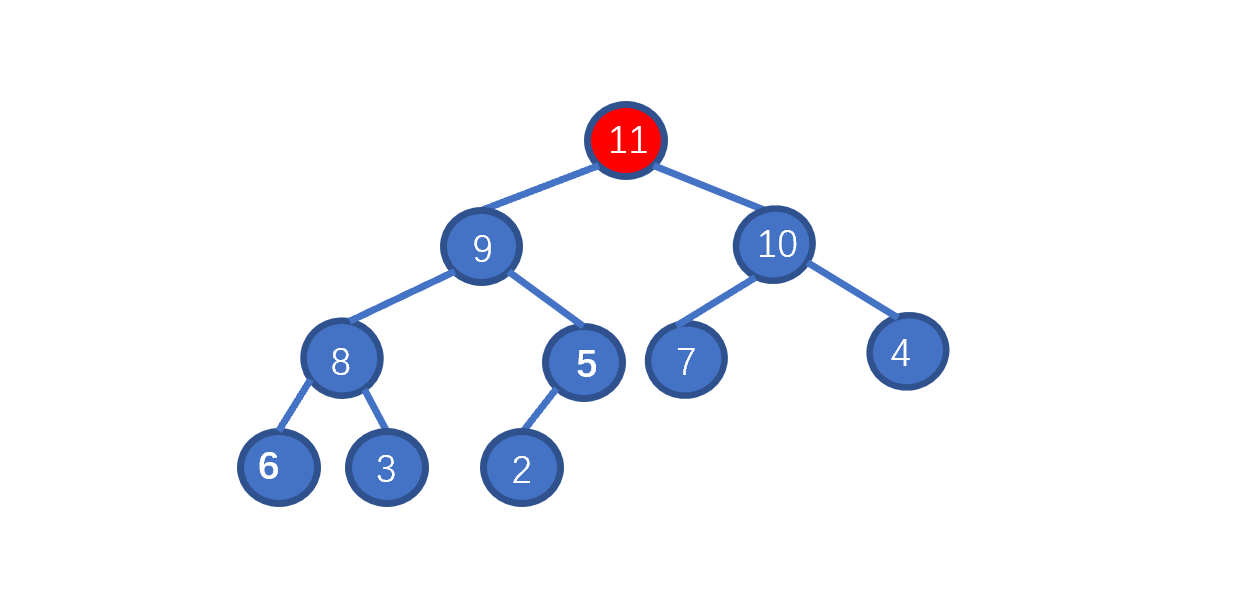
了解排序之前我们先来,看一下如何删除堆顶元素,我们需要保证的是,删除堆顶元素后,其他元素仍能满足堆的要求,我们思考一下如何实现呢?见下图
|
||||
|
||||
|
||||
|
||||
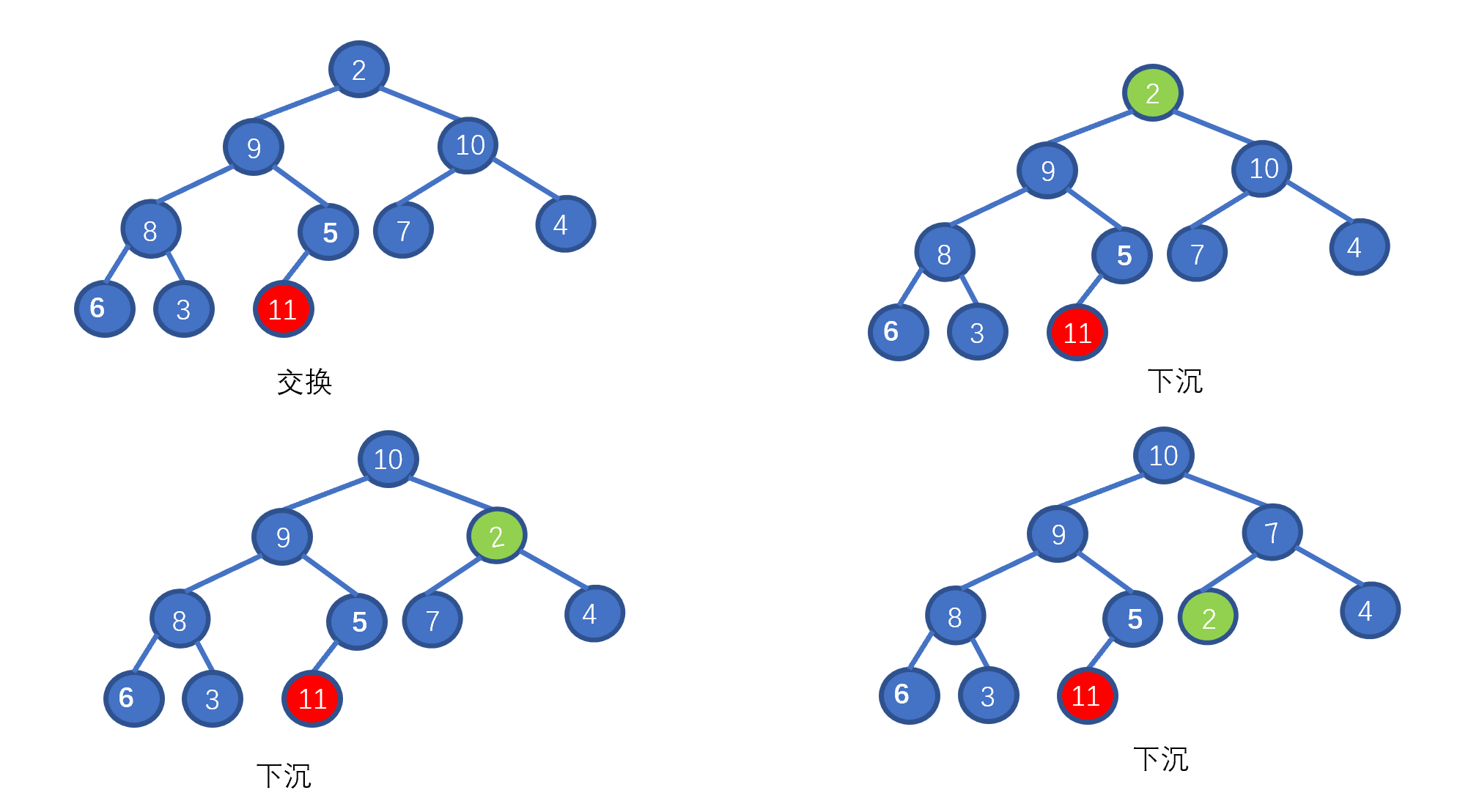
假设我们想要去除堆顶的 11 ,那我们则需要将其与堆的最后一个节点交换也就是 2 ,2然后再执行下沉操作,执行完毕后仍能满足堆的要求,见下图
|
||||
|
||||
|
||||
|
||||
好啦,其实你已经学会如何排序啦!你不信?那我给你放视频
|
||||
|
||||
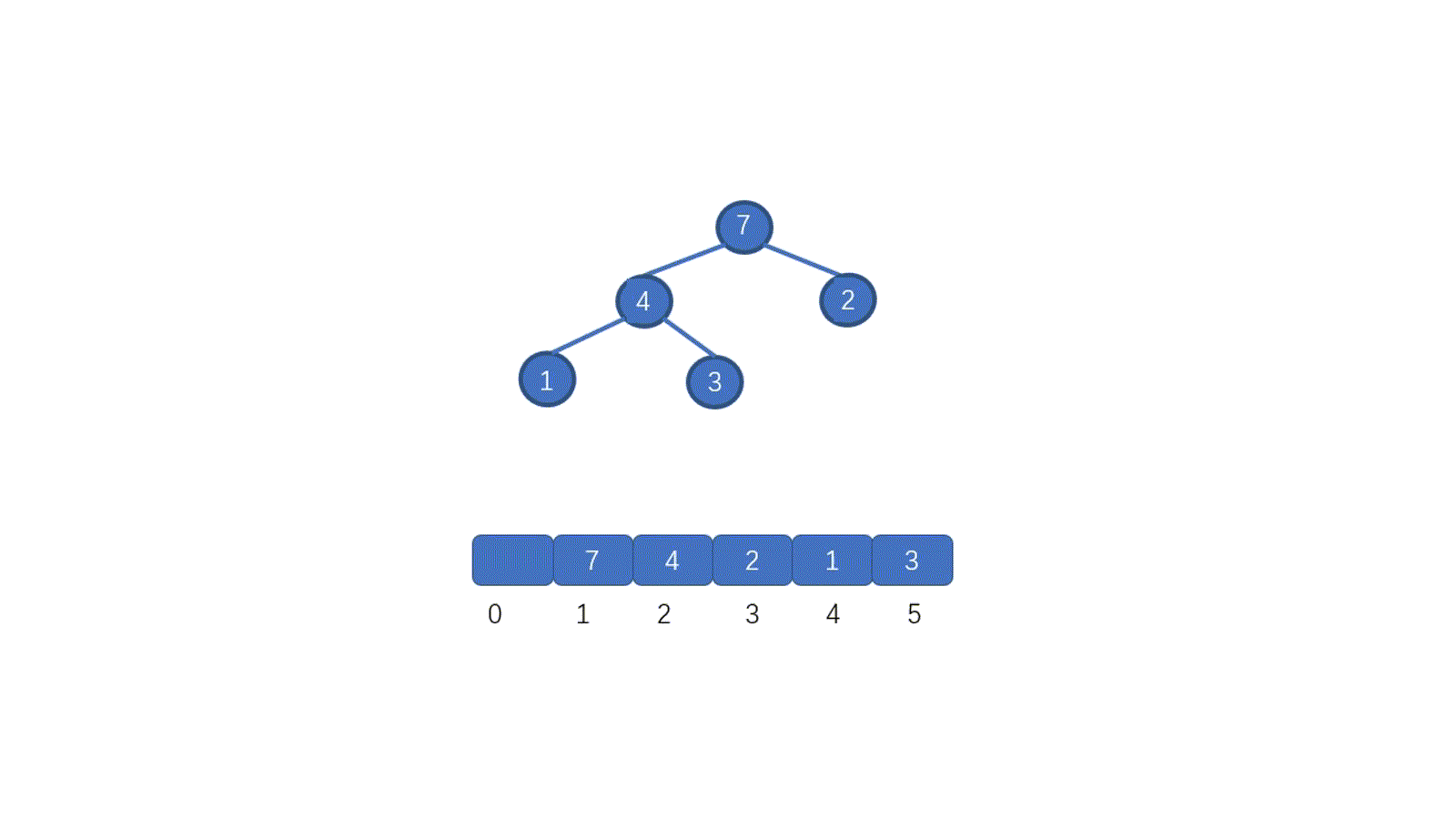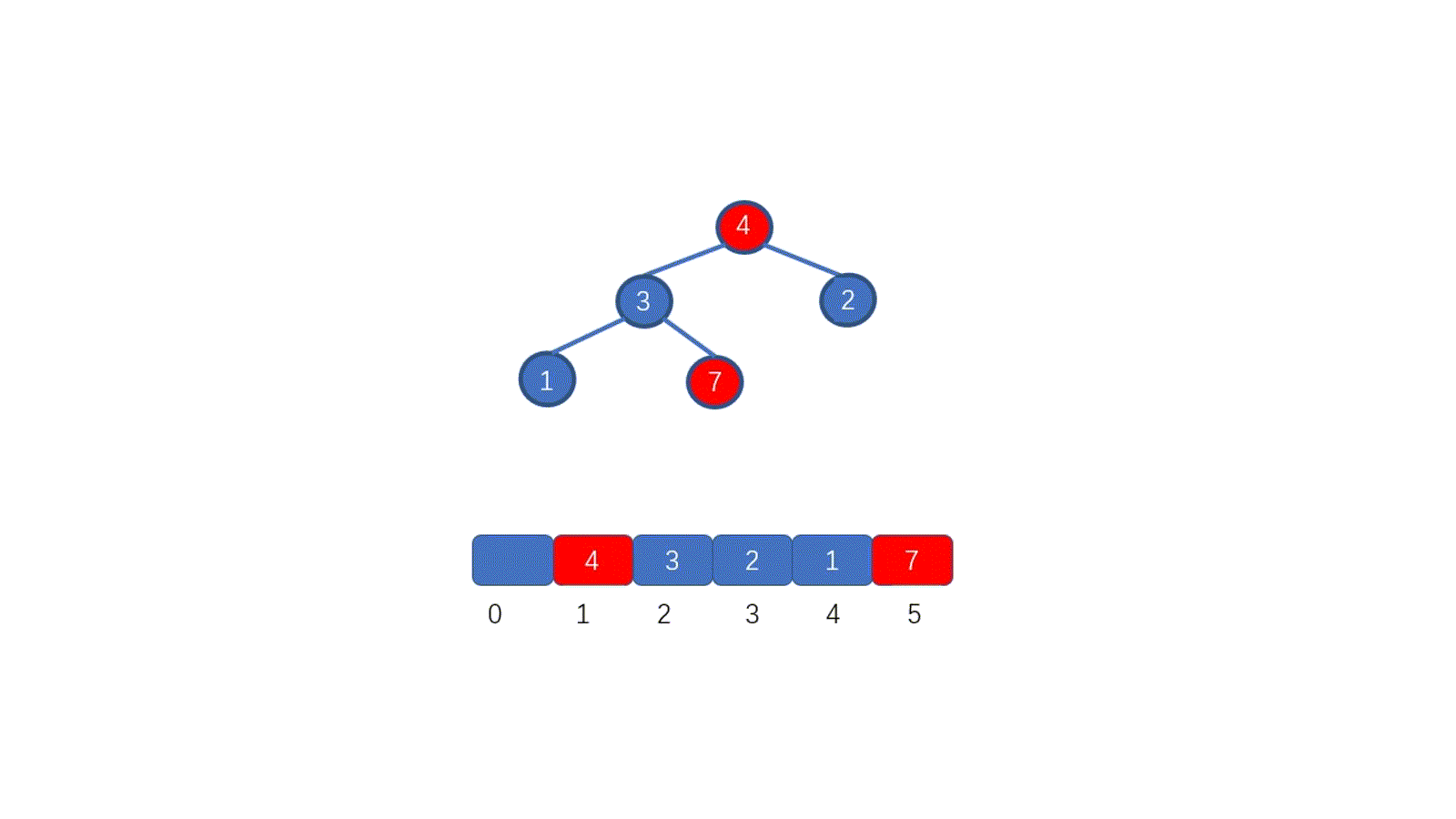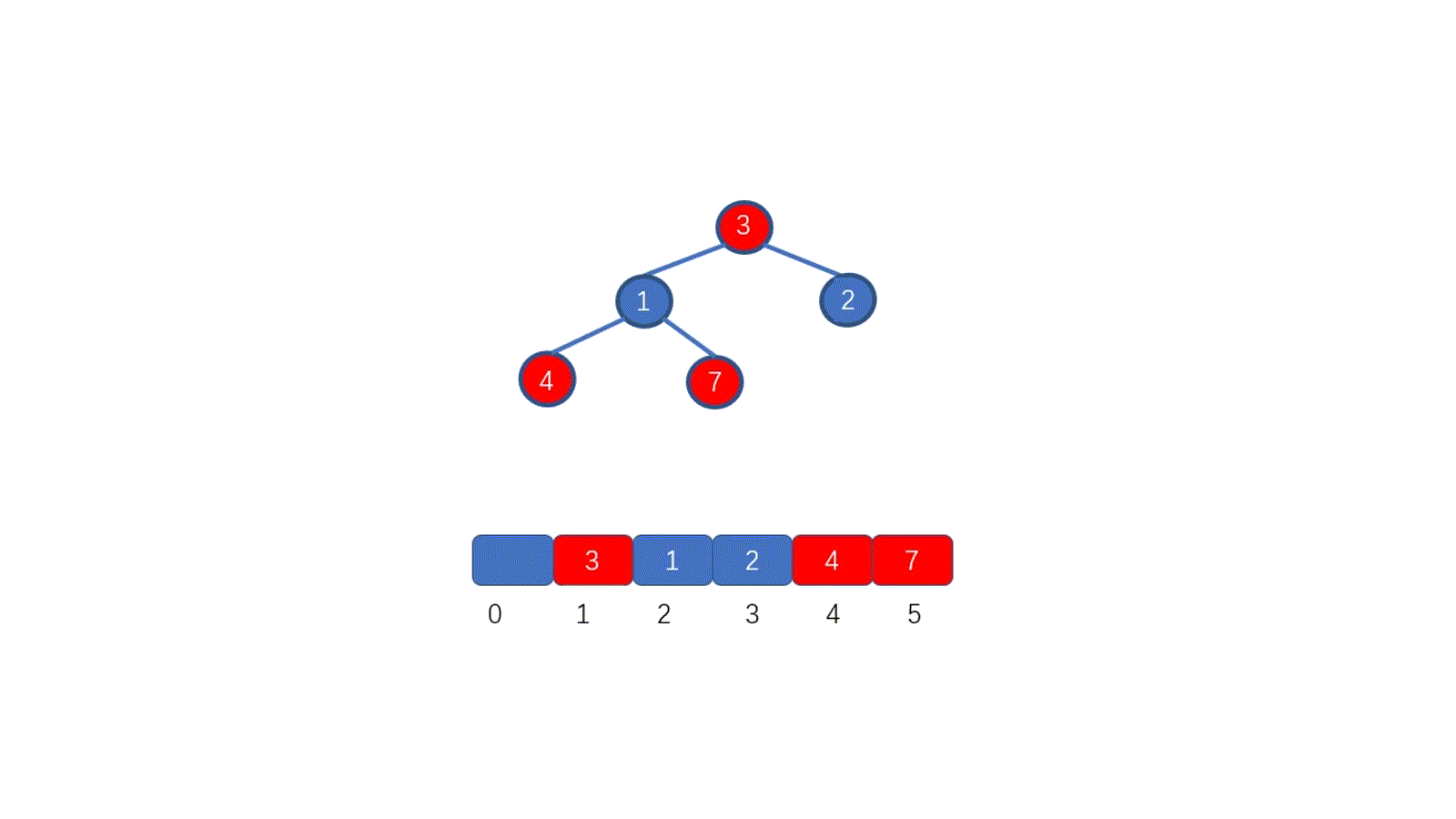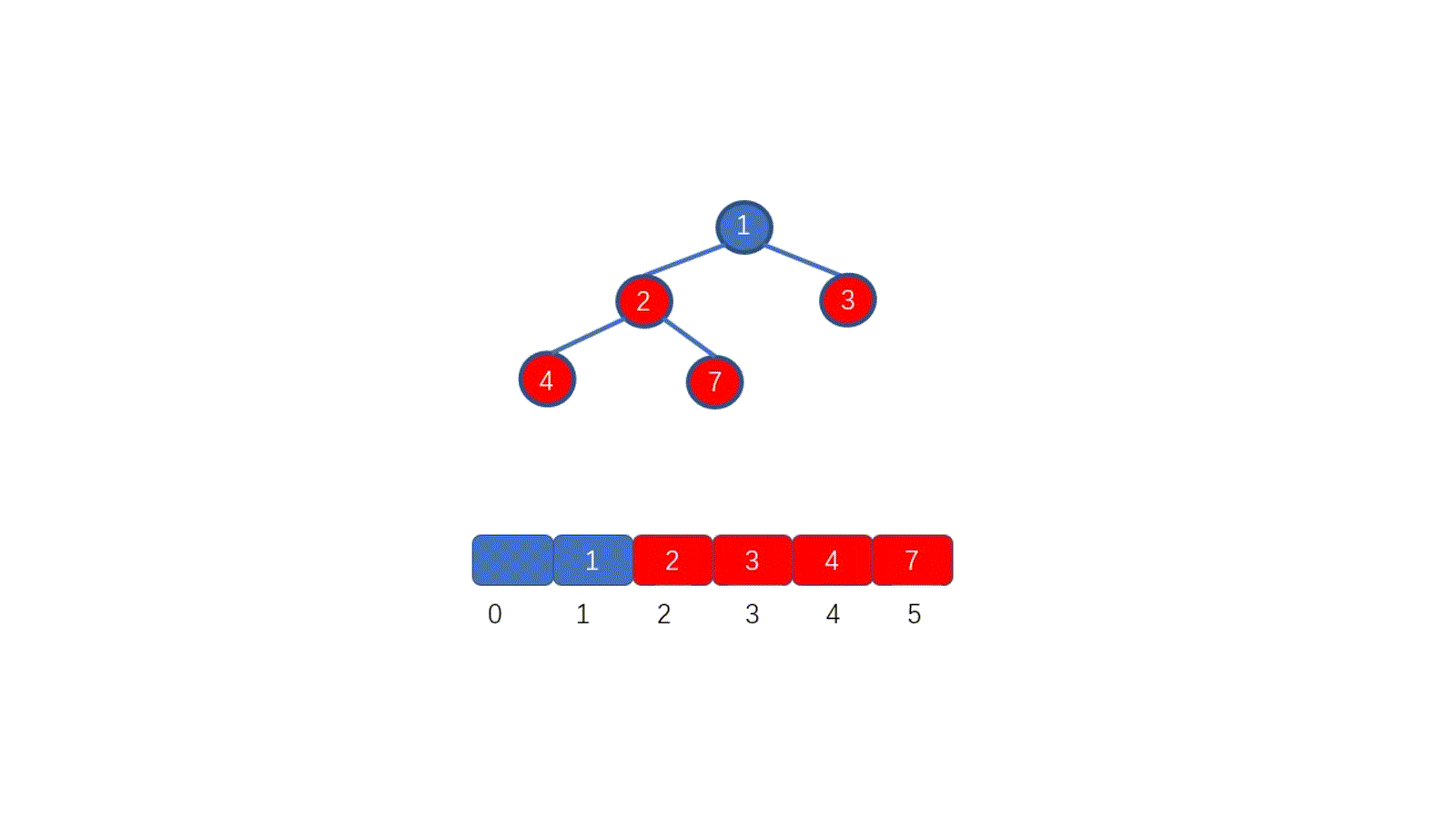
|
||||
|
||||
好啦,大家是不是已经搞懂啦,下面我们总结一下堆排序的具体执行过程
|
||||
|
||||
1.建堆,通过下沉操作建堆效率更高,具体过程是,找到最后一个非叶子节点,然后从后往前遍历执行下沉操作。
|
||||
|
||||
2.排序,将堆顶元素(代表最大元素)与最后一个元素交换,然后新的堆顶元素进行下沉操作,遍历执行上诉操作,则可以完成排序。
|
||||
|
||||
好啦,下面我们一起看代码吧
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray(int[] nums) {
|
||||
|
||||
int len = nums.length;
|
||||
int[] a = new int[len + 1];
|
||||
|
||||
for (int i = 0; i < nums.length; ++i) {
|
||||
a[i+1] = nums[i];
|
||||
}
|
||||
//下沉建堆
|
||||
for (int i = len/2; i >= 1; --i) {
|
||||
sink(a,i,len);
|
||||
}
|
||||
|
||||
int k = len;
|
||||
//排序
|
||||
while (k > 1) {
|
||||
swap(a,1,k--);
|
||||
sink(a,1,k);
|
||||
}
|
||||
for (int i = 1; i < len+1; ++i) {
|
||||
nums[i-1] = a[i];
|
||||
}
|
||||
return nums;
|
||||
}
|
||||
public void sink (int[] nums, int k,int end) {
|
||||
//下沉
|
||||
while (2 * k <= end) {
|
||||
int j = 2 * k;
|
||||
//找出子节点中最大或最小的那个
|
||||
if (j + 1 <= end && nums[j + 1] > nums[j]) {
|
||||
j++;
|
||||
}
|
||||
if (nums[j] > nums[k]) {
|
||||
swap(nums, j, k);
|
||||
} else {
|
||||
break;
|
||||
}
|
||||
k = j;
|
||||
}
|
||||
}
|
||||
public void swap (int nums[], int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
好啦,堆排序我们就到这里啦,是不是搞定啦,总的来说堆排序比其他排序算法稍微难理解一些,重点就是建堆,而且应用比较广泛,大家记得打卡呀。
|
||||
|
||||
好啦,我们再来分析一下堆排序的时间复杂度、空间复杂度以及稳定性。
|
||||
|
||||
**堆排序时间复杂度分析**
|
||||
|
||||
因为我们建堆的时间复杂度为 O(n),排序过程的时间复杂度为 O(nlogn),所以总的空间复杂度为 O(nlogn)
|
||||
|
||||
**堆排序空间复杂度分析**
|
||||
|
||||
这里需要注意,我们上面的描述过程中,为了更直观的描述,空出数组的第一位,这样我们就可以通过 i * 2 和 i * 2+1 来求得左孩子节点和右孩子节点 。我们也可以根据 i * 2 + 1 和 i * 2 + 2 来获取孩子节点,这样则不需要临时数组来处理原数组,将所有元素后移一位,所以堆排序的空间复杂度为 O(1),是原地排序算法。
|
||||
|
||||
**堆排序稳定性分析**
|
||||
|
||||
堆排序不是稳定的排序算法,在排序的过程,我们会将堆的最后一个节点跟堆顶节点交换,改变相同元素的原始相对位置。
|
||||
|
||||
最后我们来比较一下我们快速排序和堆排序
|
||||
|
||||
1.对于快速排序来说,数据是顺序访问的。而对于堆排序来说,数据是跳着访问的。这样对 CPU 缓存是不友好的
|
||||
|
||||
2.相同的的数据,排序过程中,堆排序的数据交换次数要多于快速排序。
|
||||
|
||||
所以上面两条也就说明了在实际开发中,堆排序的性能不如快速排序性能好。
|
||||
|
||||
好啦,今天的内容就到这里啦,咱们下期见。
|
||||
178
gif-algorithm/数据结构和算法/归并排序.md
Normal file
178
gif-algorithm/数据结构和算法/归并排序.md
Normal file
@@ -0,0 +1,178 @@
|
||||
### **归并排序**
|
||||
|
||||
归并排序是必须要掌握的排序算法,也算是面试高频考点,下面我们就一起来扒一扒归并排序吧,原理很简单,大家一下就能搞懂。
|
||||
|
||||
袁记菜馆内
|
||||
|
||||
第 23 届食神争霸赛开赛啦!
|
||||
|
||||
袁厨想在自己排名前4的分店中,挑选一个最优秀的厨师来参加食神争霸赛,选拔规则如下。
|
||||
|
||||
第一场 PK:每个分店选出两名厨师,首先进行店内 PK,选出店内里的胜者
|
||||
|
||||
第二场 PK: 然后店内的优胜者代表分店挑战其他某一分店的胜者(半决赛)
|
||||
|
||||
第三场 PK:最后剩下的两名胜者进行PK,选出最后的胜者。
|
||||
|
||||
示意图如下
|
||||
|
||||
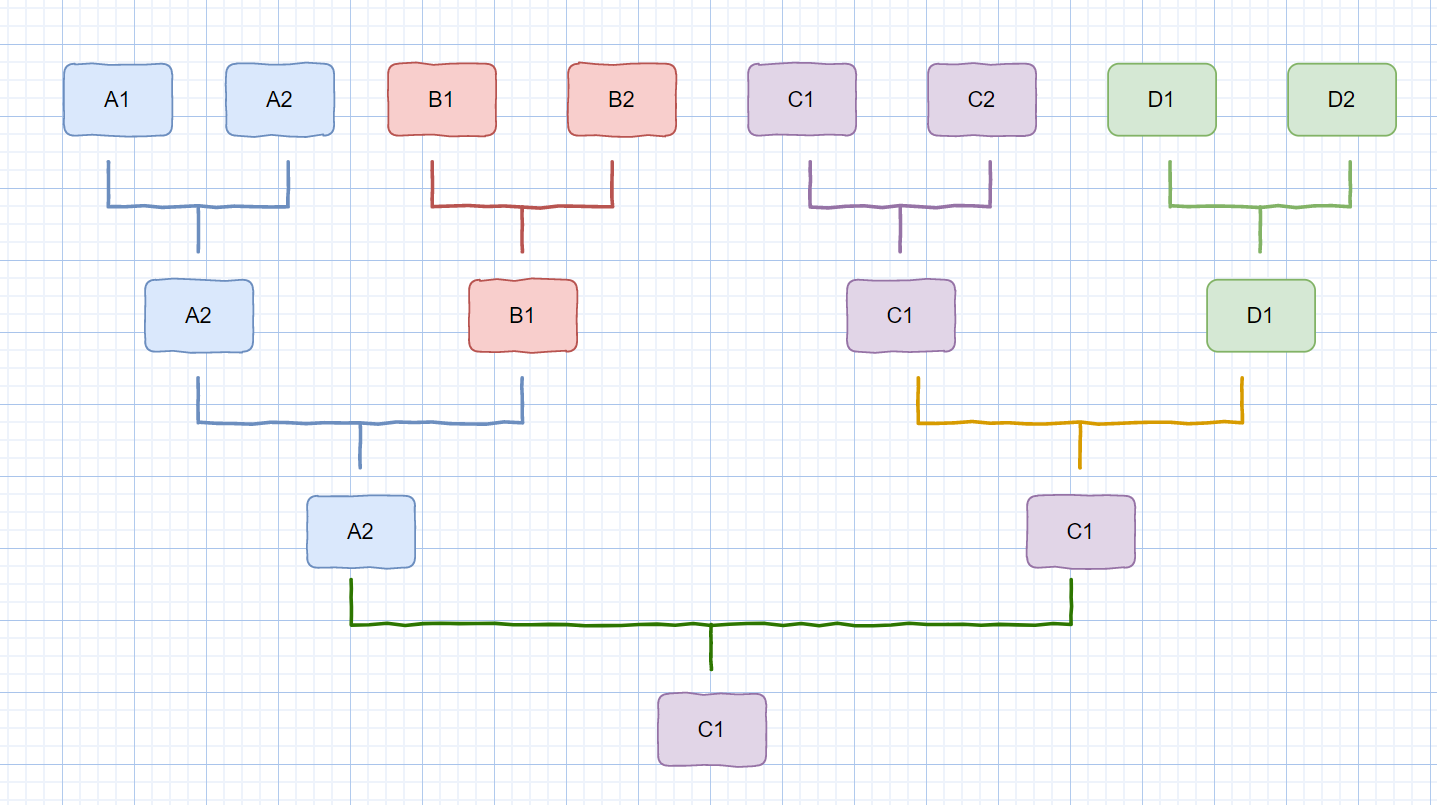
|
||||
|
||||
上面的例子大家应该不会陌生吧,其实我们归并排序和食神选拔赛的流程是有些相似的,下面我们一起来看一下吧
|
||||
|
||||
归并这个词语的含义就是合并,并入的意思,而在我们的数据结构中的定义是将**两个或两个以上的有序表和成一个新的有序表**。而我们这里说的归并排序就是使用归并的思想实现的排序方法。
|
||||
|
||||
归并排序使用的就是分治思想。顾名思义就是分而治之,将一个大问题分解成若干个小的子问题来解决。小的子问题解决了,大问题也就解决了。分治后面会专门写一篇文章进行描述滴,这里先简单提一下。
|
||||
|
||||
下面我们通过一个图片来描述一下归并排序的数据变换情况,见下图。
|
||||
|
||||
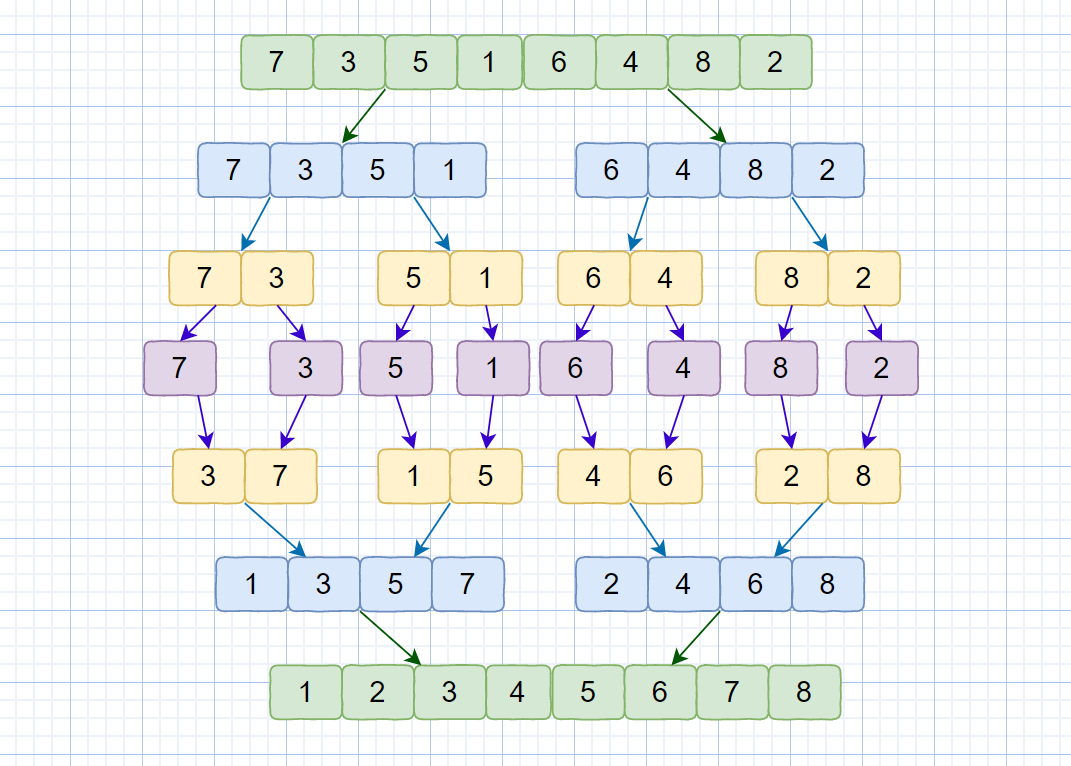
|
||||
|
||||
我们简单了解了归并排序的思想,从上面的描述中,我们可以知道算法的归并过程是比较难实现的,这也是这个算法的重点,看完我们这个视频就能懂个大概啦。
|
||||
|
||||
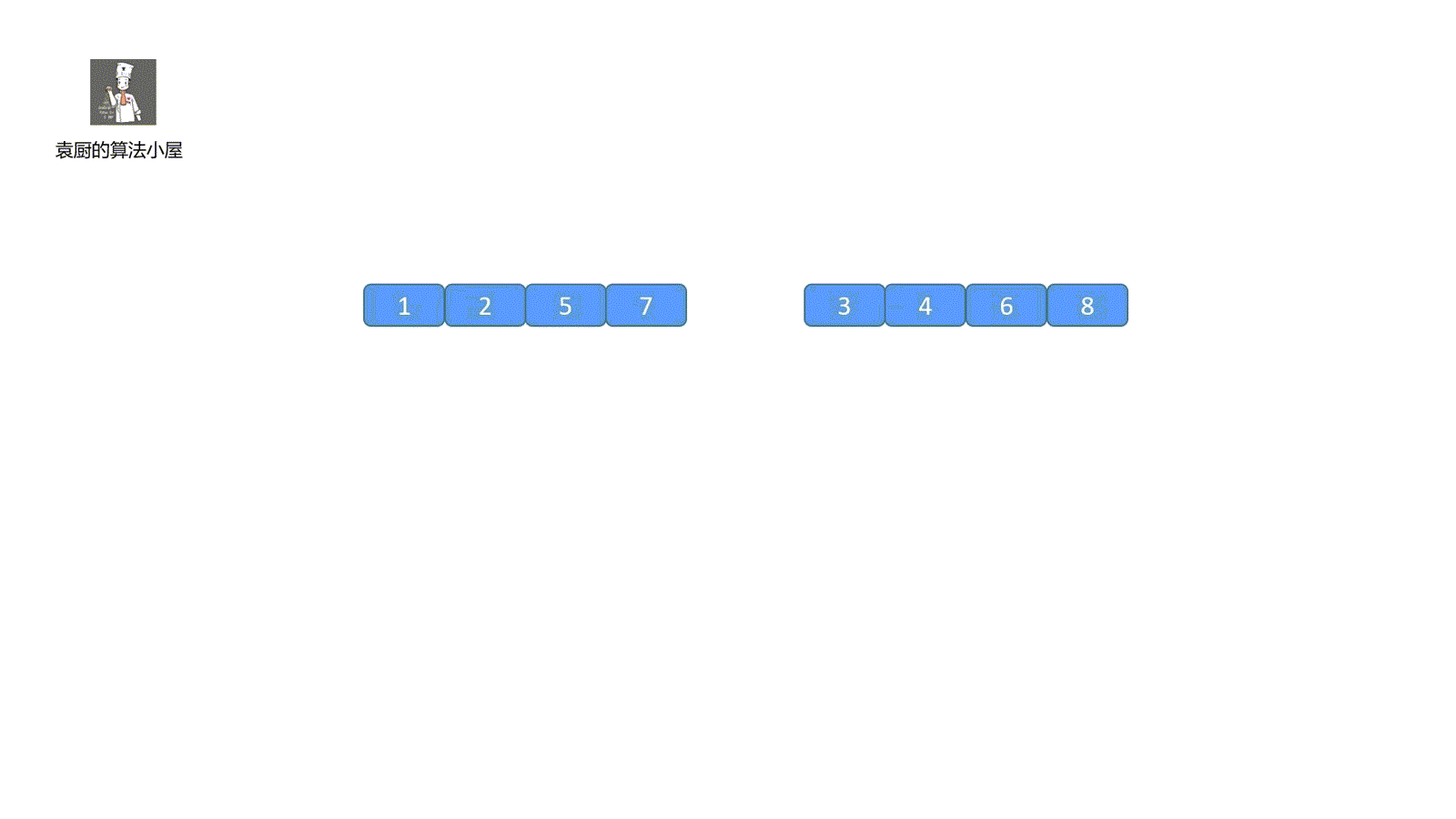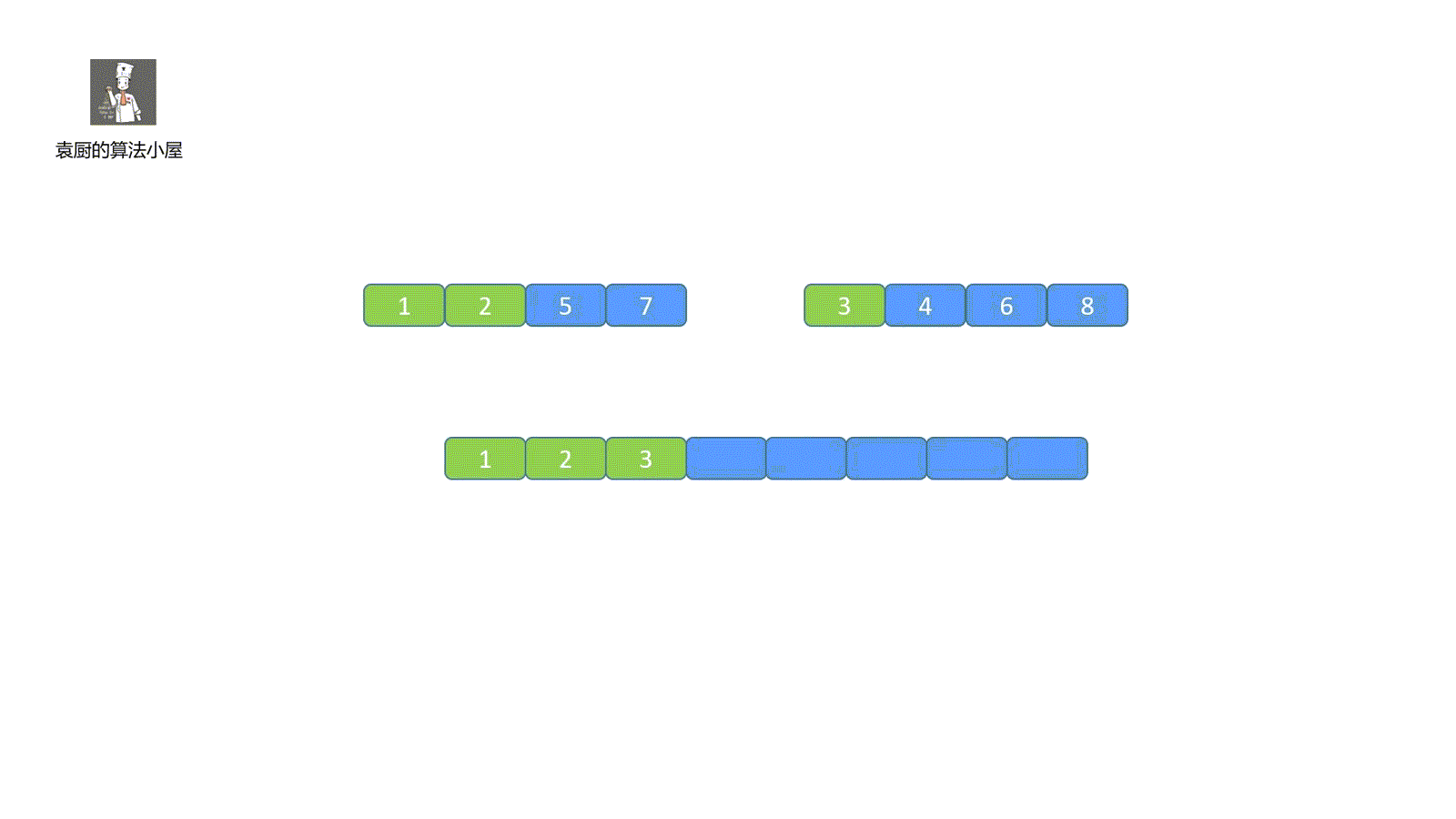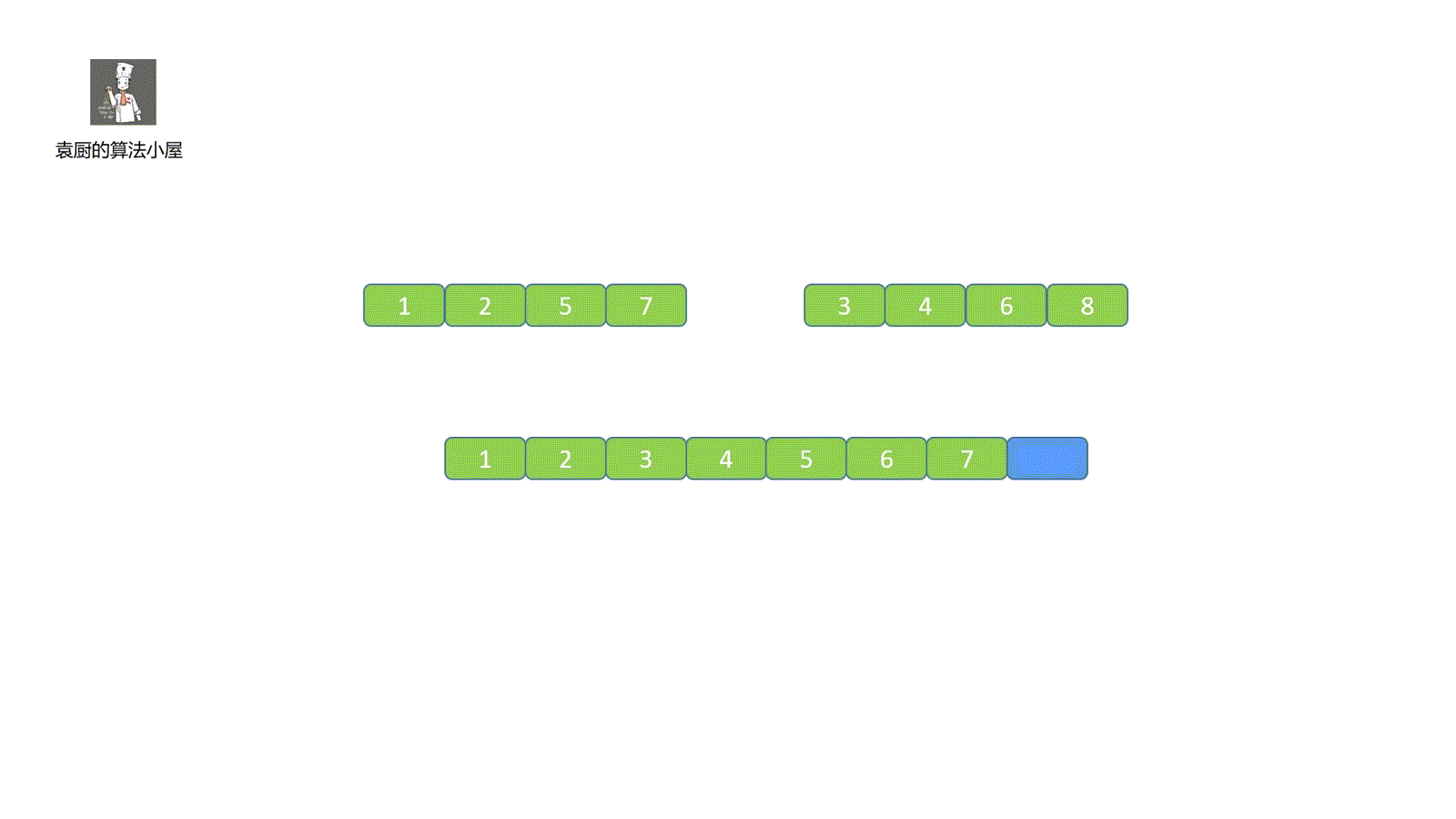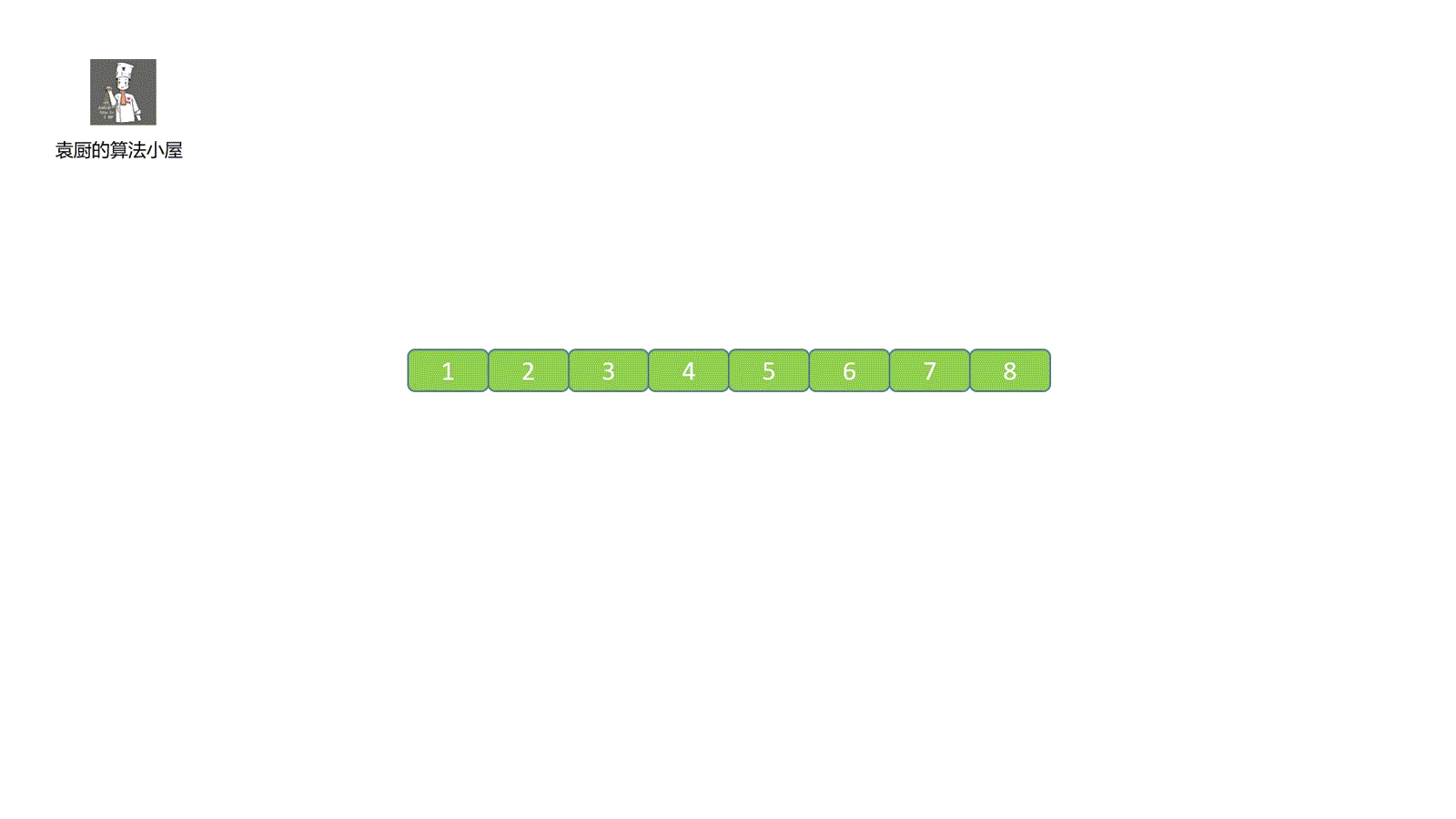
|
||||
|
||||
视频中归并步骤大家有没有看懂呀,没看懂也不用着急,下面我们一起来拆解一下,归并共有三步走。
|
||||
|
||||
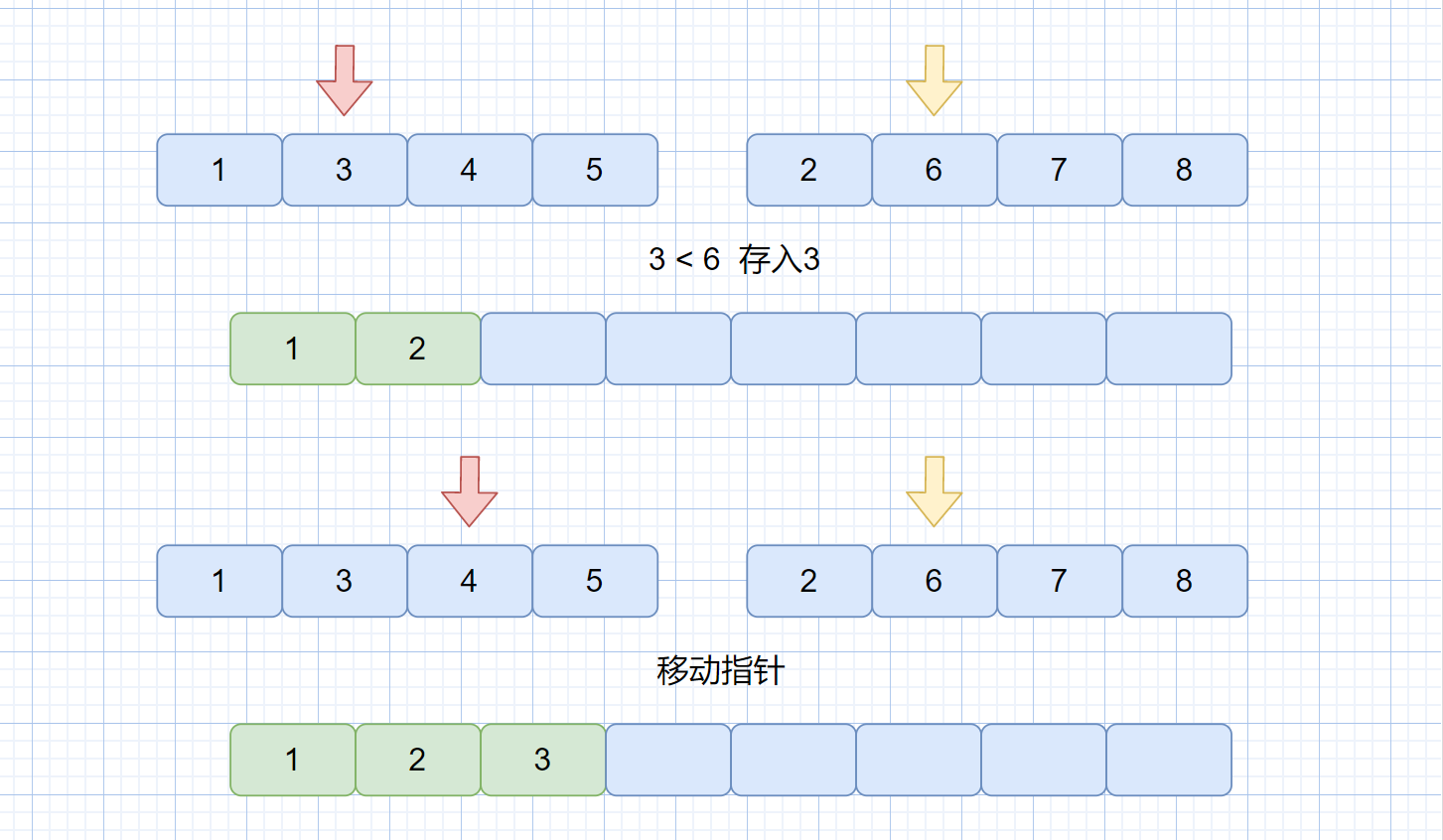
第一步:创建一个额外大集合用于存储归并结果,长度则为那两个小集合的和,从视频中也可以看的出
|
||||
|
||||
第二步:我们从左自右比较两个指针指向的值,将较小的那个存入大集合中,存入之后指针移动,并继续比较,直到某一小集合的元素全部都存到大集合中。见下图
|
||||
|
||||
|
||||
|
||||
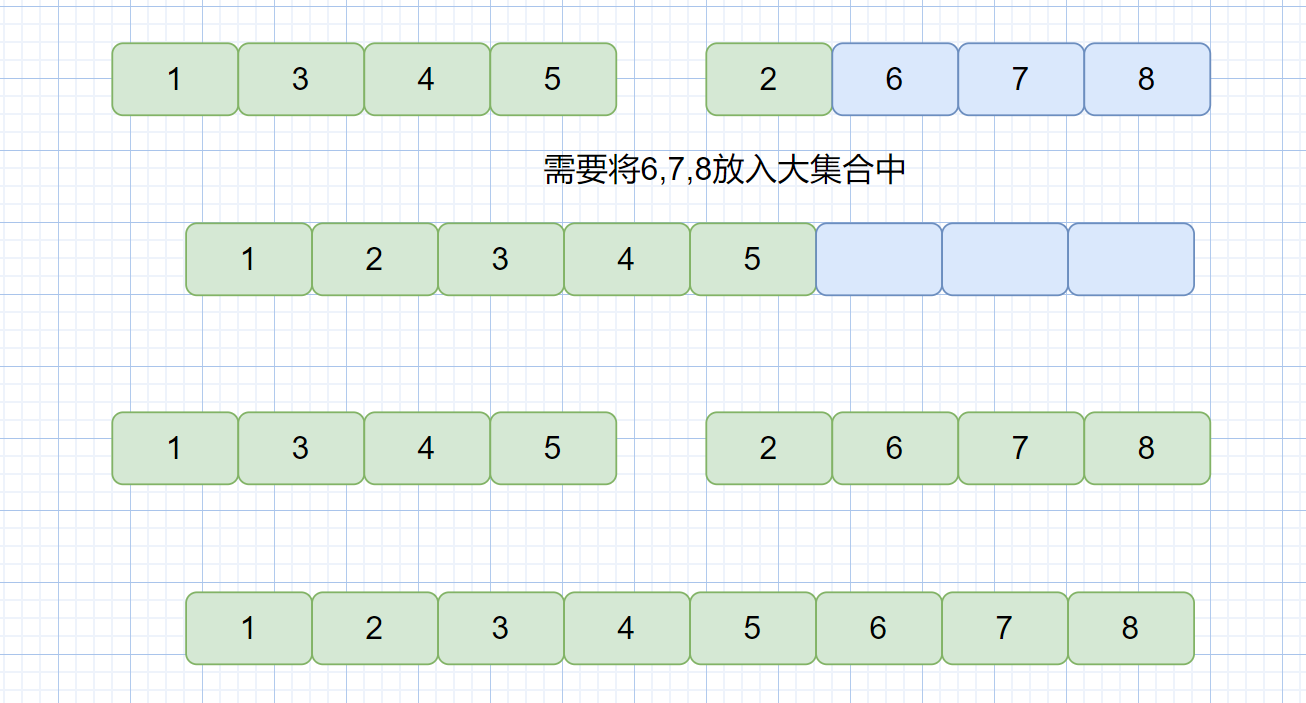
第三步:当某一小集合元素全部放入大集合中,则需将另一小集合中剩余的所有元素存到大集合中,见下图
|
||||
|
||||
|
||||
|
||||
好啦,看完视频和图解是不是能够写出个大概啦,了解了算法原理之后代码写起来就很简单啦,
|
||||
|
||||
下面我们看代码吧。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray(int[] nums) {
|
||||
mergeSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
}
|
||||
public void mergeSort(int[] arr, int left, int right) {
|
||||
if (left < right) {
|
||||
int mid = left + ((right - left) >> 1);
|
||||
mergeSort(arr,left,mid);
|
||||
mergeSort(arr,mid+1,right);
|
||||
merge(arr,left,mid,right);
|
||||
}
|
||||
}
|
||||
//归并
|
||||
public void merge(int[] arr,int left, int mid, int right) {
|
||||
//第一步,定义一个新的临时数组
|
||||
int[] temparr = new int[right -left + 1];
|
||||
int temp1 = left, temp2 = mid + 1;
|
||||
int index = 0;
|
||||
//对应第二步,比较每个指针指向的值,小的存入大集合
|
||||
while (temp1 <= mid && temp2 <= right) {
|
||||
if (arr[temp1] <= arr[temp2]) {
|
||||
temparr[index++] = arr[temp1++];
|
||||
} else {
|
||||
temparr[index++] = arr[temp2++];
|
||||
}
|
||||
}
|
||||
//对应第三步,将某一小集合的剩余元素存到大集合中
|
||||
if (temp1 <= mid) System.arraycopy(arr, temp1, temparr, index, mid - temp1 + 1);
|
||||
if (temp2 <= right) System.arraycopy(arr, temp2, temparr, index, right -temp2 + 1); //将大集合的元素复制回原数组
|
||||
System.arraycopy(temparr,0,arr,0+left,right-left+1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**归并排序时间复杂度分析**
|
||||
|
||||
我们一趟归并,需要将两个小集合的长度放到大集合中,则需要将待排序序列中的所有记录扫描一遍所以时间复杂度为O(n)。归并排序把集合一层一层的折半分组,则由完全二叉树的深度可知,整个排序过程需要进行 logn(向上取整)次,则总的时间复杂度为 O(nlogn)。另外归并排序的执行效率与要排序的原始数组的有序程度无关,所以在最好,最坏,平均情况下时间复杂度均为 O(nlogn) 。虽然归并排序时间复杂度很稳定,但是他的应用范围却不如快速排序广泛,这是因为归并排序不是原地排序算法,空间复杂度不为 O(1),那么他的空间复杂度为多少呢?
|
||||
|
||||
**归并排序的空间复杂度分析**
|
||||
|
||||
归并排序所创建的临时结合都会在方法结束时释放,单次归并排序的最大空间是 n ,所以归并排序的空间复杂度为 O(n).
|
||||
|
||||
**归并排序的稳定性分析**
|
||||
|
||||
归并排序的稳定性,要看我们的 merge 函数,我们代码中设置了 arr[temp1] <= arr[temp2] ,当两个元素相同时,先放入arr[temp1] 的值到大集合中,所以两个相同元素的相对位置没有发生改变,所以归并排序是稳定的排序算法。
|
||||
|
||||
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|
||||
| -------- | -------------- | -------------- | -------------- | ---------- | -------- |
|
||||
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
|
||||
|
||||
等等还没完嘞,不要走。
|
||||
|
||||
归并排序的递归实现是比较常见的,也是比较容易理解的,下面我们一起来扒一下归并排序的迭代写法。看看他是怎么实现的。
|
||||
|
||||
我们通过一个视频来了解下迭代方法的思想,
|
||||
|
||||

|
||||
|
||||
是不是通过视频了解个大概啦,下面我们来对视频进行解析。
|
||||
|
||||
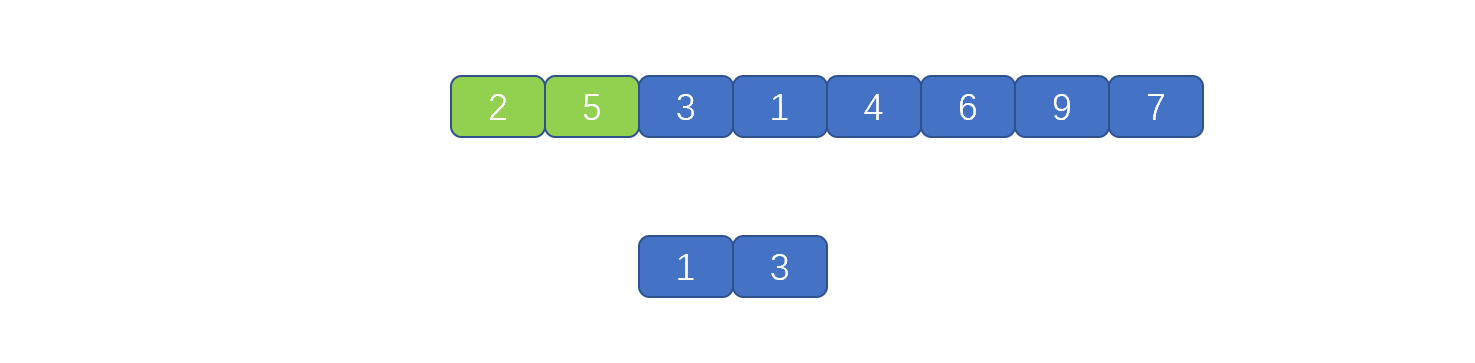
迭代实现的归并排序是将小集合合成大集合,小集合大小为 1,2,4,8,.....。依次迭代,见下图
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
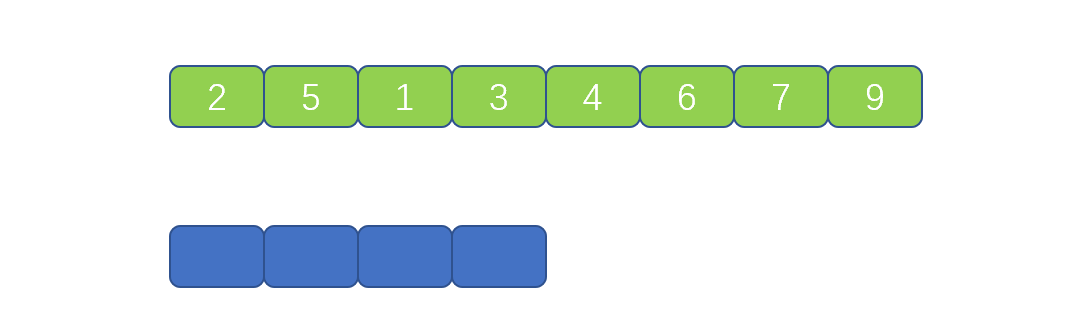
比如此时小集合大小为 1 。两个小集合分别为 [3],[1]。然后我们根据合并规则,见第一个视频,将[3],[1]合并到临时数组中,则小的先进,则实现了排序,然后再将临时数组的元素复制到原来数组中。则实现了一次合并。
|
||||
|
||||
下面则继续合并[4],[6]。具体步骤一致。所有的小集合合并完成后,则小集合的大小变为 2,继续执行刚才步骤,见下图。
|
||||
|
||||
|
||||
|
||||
此时子集合的大小为 2 ,则为 [2,5],[1,3] 继续按照上面的规则合并到临时数组中完成排序。 这就是迭代法的具体执行过程,
|
||||
|
||||
下面我们直接看代码吧。
|
||||
|
||||
注:递归法和迭代法的 merge函数代码一样。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray (int[] nums) {
|
||||
//代表子集合大小,1,2,4,8,16.....
|
||||
int k = 1;
|
||||
int len = nums.length;
|
||||
while (k < len) {
|
||||
mergePass(nums,k,len);
|
||||
k *= 2;
|
||||
}
|
||||
return nums;
|
||||
|
||||
}
|
||||
public void mergePass (int[] array, int k, int len) {
|
||||
|
||||
int i;
|
||||
for (i = 0; i < len-2*k; i += 2*k) {
|
||||
//归并
|
||||
merge(array,i,i+k-1,i+2*k-1);
|
||||
}
|
||||
//归并最后两个序列
|
||||
if (i + k < len) {
|
||||
merge(array,i,i+k-1,len-1);
|
||||
}
|
||||
|
||||
}
|
||||
public void merge (int[] arr,int left, int mid, int right) {
|
||||
//第一步,定义一个新的临时数组
|
||||
int[] temparr = new int[right -left + 1];
|
||||
int temp1 = left, temp2 = mid + 1;
|
||||
int index = 0;
|
||||
//对应第二步,比较每个指针指向的值,小的存入大集合
|
||||
while (temp1 <= mid && temp2 <= right) {
|
||||
if (arr[temp1] <= arr[temp2]) {
|
||||
temparr[index++] = arr[temp1++];
|
||||
} else {
|
||||
temparr[index++] = arr[temp2++];
|
||||
}
|
||||
}
|
||||
//对应第三步,将某一小集合的剩余元素存到大集合中
|
||||
if (temp1 <= mid) System.arraycopy(arr, temp1, temparr, index, mid - temp1 + 1);
|
||||
if (temp2 <= right) System.arraycopy(arr, temp2, temparr, index, right -temp2 + 1);
|
||||
//将大集合的元素复制回原数组
|
||||
System.arraycopy(temparr,0,arr,0+left,right-left+1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
424
gif-algorithm/数据结构和算法/快速排序.md
Normal file
424
gif-algorithm/数据结构和算法/快速排序.md
Normal file
@@ -0,0 +1,424 @@
|
||||
### 快速排序
|
||||
|
||||
今天我们来说一下快速排序,这个排序算法也是面试的高频考点,原理很简单,我们一起来扒一下他吧。
|
||||
|
||||
我们先来说一下快速排序的基本思想。
|
||||
|
||||
1.先从数组中找一个基准数
|
||||
|
||||
2.让其他比它大的元素移动到数列一边,比他小的元素移动到数列另一边,从而把数组拆解成两个部分。
|
||||
|
||||
3.再对左右区间重复第二步,直到各区间只有一个数。
|
||||
|
||||
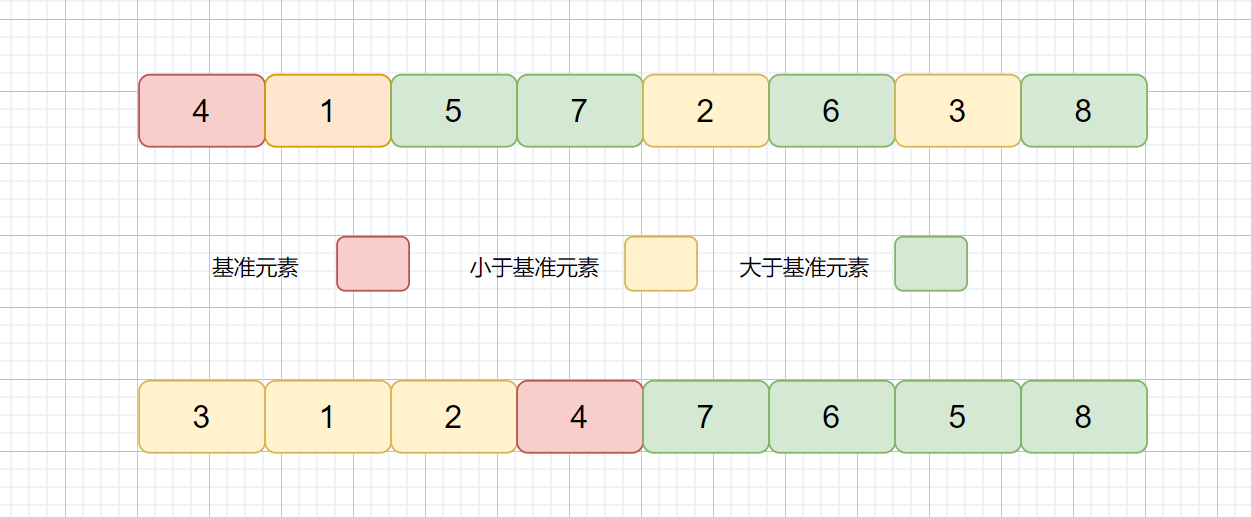
见下图
|
||||
|
||||
|
||||
|
||||
上图则为一次快排示意图,下面我们再利用递归,分别对左半边区间也就是 [3,1,2] 和右半区间 [7,6,5,8] 执行上诉过程,直至区间缩小为 1 也就是第三条,则此时所有的数据都有序。
|
||||
|
||||
简单来说就是我们利用基准数通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比基准数小,另一部分记录的关键字均比基准数大,然后分别对这两部分记录继续进行排序,进而达到有序。
|
||||
|
||||
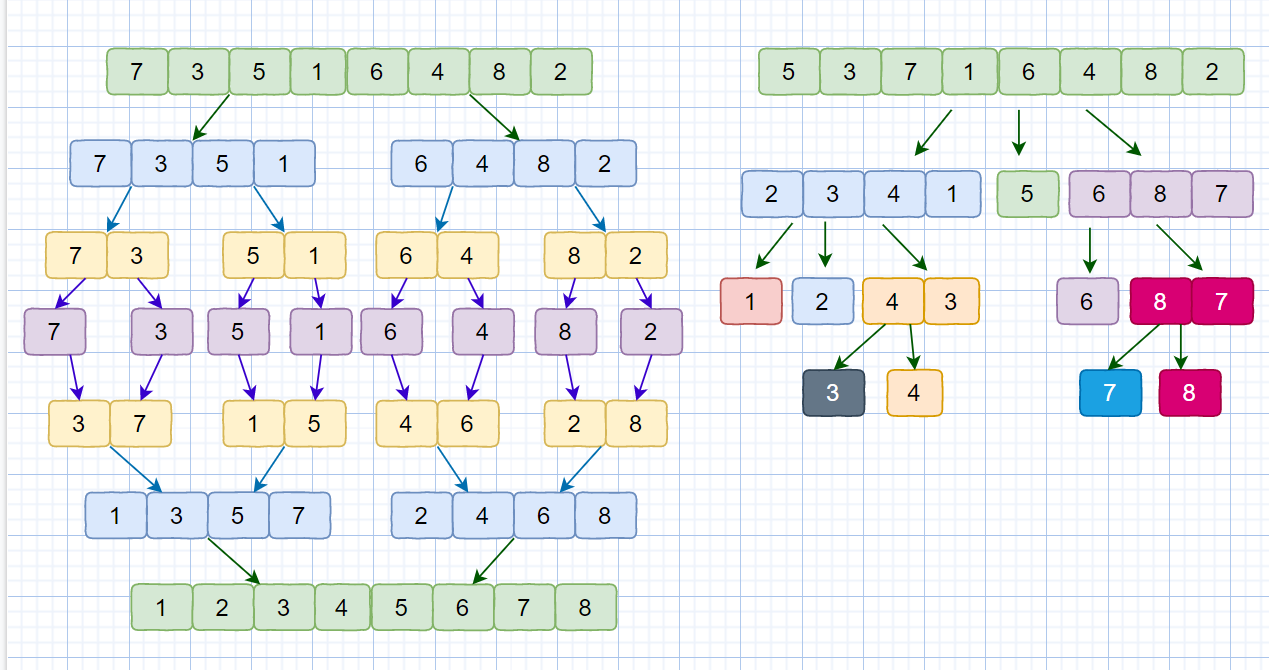
我们现在应该了解了快速排序的思想,那么大家还记不记得我们之前说过的归并排序,他们两个用到的都是分治思想,那他们两个有什么不同呢?见下图
|
||||
|
||||
注:快速排序我们以序列的第一个元素作为基准数
|
||||
|
||||
|
||||
|
||||
虽然归并排序和快速排序都用到了分治思想,但是归并排序是自下而上的,先处理子问题,然后再合并,将小集合合成大集合,最后实现排序。而快速排序是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题
|
||||
|
||||
我们根据思想可知,排序算法的核心就是如何利用基准数将记录分区,这里我们主要介绍两种容易理解的方法,一种是挖坑填数,另一种是利用双指针思想进行元素交换。
|
||||
|
||||
下面我们先来介绍下挖坑填数的分区方法
|
||||
|
||||
基本思想是我们首先以序列的第一个元素为基准数,然后将该位置挖坑,下面判断 nums[hight] 是否大于基准数,如果大于则左移 hight 指针,直至找到一个小于基准数的元素,将其填入之前的坑中,则 hight 位置会出现一个新的坑,此时移动 low 指针,找到大于基准数的元素,填入新的坑中。不断迭代直至完成分区。
|
||||
|
||||
大家直接看我们的视频模拟吧,一目了然。
|
||||
|
||||
注:为了便于理解所以采取了挖坑的形式展示
|
||||
|
||||

|
||||
|
||||
是不是很容易就理解啦,下面我们直接看代码吧。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray(int[] nums) {
|
||||
|
||||
quickSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
|
||||
}
|
||||
public void quickSort (int[] nums, int low, int hight) {
|
||||
|
||||
if (low < hight) {
|
||||
int index = partition(nums,low,hight);
|
||||
quickSort(nums,low,index-1);
|
||||
quickSort(nums,index+1,hight);
|
||||
}
|
||||
|
||||
}
|
||||
public int partition (int[] nums, int low, int hight) {
|
||||
|
||||
int pivot = nums[low];
|
||||
while (low < hight) {
|
||||
//移动hight指针
|
||||
while (low < hight && nums[hight] >= pivot) {
|
||||
hight--;
|
||||
}
|
||||
//填坑
|
||||
if (low < hight) nums[low] = nums[hight];
|
||||
while (low < hight && nums[low] <= pivot) {
|
||||
low++;
|
||||
}
|
||||
//填坑
|
||||
if (low < hight) nums[hight] = nums[low];
|
||||
}
|
||||
//基准数放到合适的位置
|
||||
nums[low] = pivot;
|
||||
return low;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
下面我们来看一下交换思路,原理一致,实现也比较简单。
|
||||
|
||||
见下图。
|
||||
|
||||
|
||||
|
||||
其实这种方法,算是对上面方法的挖坑填坑步骤进行合并,low 指针找到大于 pivot 的元素,hight 指针找到小于 pivot 的元素,然后两个元素交换位置,最后再将基准数归位。两种方法都很容易理解和实现,即使是完全没有学习过快速排序的同学,理解了思想之后也能自己动手实现,下面我们继续用视频模拟下这种方法的执行过程吧。
|
||||
|
||||

|
||||
|
||||
两种方法都很容易实现,对新手非常友好,大家可以自己去 AC 一下啊。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray (int[] nums) {
|
||||
|
||||
quickSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
|
||||
}
|
||||
|
||||
public void quickSort (int[] nums, int low, int hight) {
|
||||
|
||||
if (low < hight) {
|
||||
int index = partition(nums,low,hight);
|
||||
quickSort(nums,low,index-1);
|
||||
quickSort(nums,index+1,hight);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
public int partition (int[] nums, int low, int hight) {
|
||||
|
||||
int pivot = nums[low];
|
||||
int start = low;
|
||||
|
||||
while (low < hight) {
|
||||
while (low < hight && nums[hight] >= pivot) hight--;
|
||||
while (low < hight && nums[low] <= pivot) low++;
|
||||
if (low >= hight) break;
|
||||
swap(nums, low, hight);
|
||||
}
|
||||
//基准值归位
|
||||
swap(nums,start,low);
|
||||
return low;
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**快速排序的时间复杂度分析**
|
||||
|
||||
快排也是用递归来实现的。所以快速排序的时间性能取决于快速排序的递归树的深度。如果每次分区操作,都能正好把数组分成大小接近相等的两个小区间,那么此时的递归树是平衡的,性能也较好,递归树的深度也就和之前归并排序求解方法一致,然后我们每一次分区需要对数组扫描一遍,做 n 次比较,所以最优情况下,快排的时间复杂度是 O(nlogn)。
|
||||
|
||||
但是大多数情况下我们不能划分的很均匀,比如数组为正序或者逆序时,即 [1,2,3,4] 或 [4,3,2,1] 时,此时为最坏情况,那么此时我们则需要递归调用 n-1 次,此时的时间复杂度则退化到了 O(n^2)。
|
||||
|
||||
**快速排序的空间复杂度分析**
|
||||
|
||||
快速排序主要时递归造成的栈空间的使用,最好情况时其空间复杂度为O (logn),对应递归树的深度。最坏情况时则需要 n-1 次递归调用,此时空间复杂度为O(n).
|
||||
|
||||
**快速排序的稳定性分析**
|
||||
|
||||
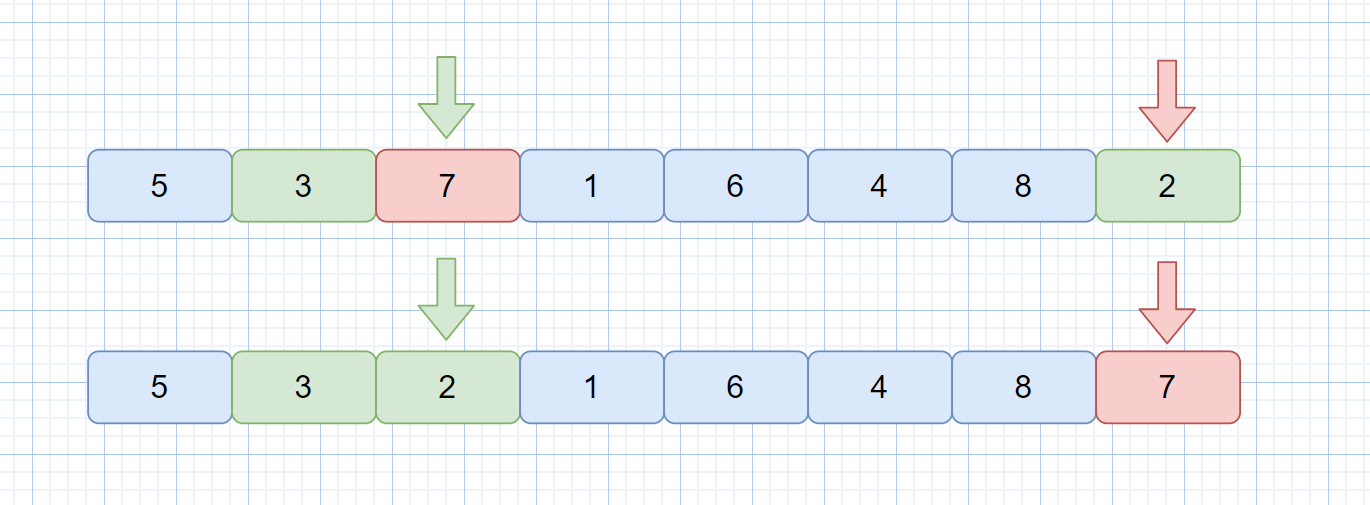
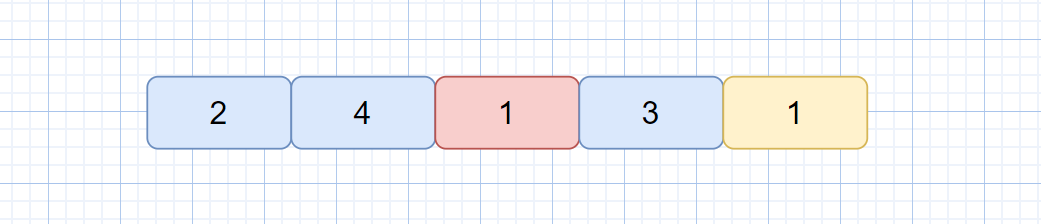
快速排序是一种不稳定的排序算法,因为其关键字的比较和交换是跳跃进行的,见下图。
|
||||
|
||||
|
||||
|
||||
此时无论使用哪一种方法,第一次排序后,黄色的 1 都会跑到红色 1 的前面,所以快速排序是不稳定的排序算法。
|
||||
|
||||

|
||||
|
||||
好啦,快速排序我们掌握的差不多了,下面我们一起来看看如何对其优化吧。
|
||||
|
||||
**快速排序的迭代写法**
|
||||
|
||||
该方法实现也是比较简单的,借助了栈来实现,很容易实现。主要利用了先进后出的特性,这里需要注意的就是入栈的顺序,这里算是一个小细节,需要注意一下。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
|
||||
public int[] sortArray(int[] nums) {
|
||||
Stack<Integer> stack = new Stack<>();
|
||||
stack.push(nums.length - 1);
|
||||
stack.push(0);
|
||||
while (!stack.isEmpty()) {
|
||||
int low = stack.pop();
|
||||
int hight = stack.pop();
|
||||
|
||||
if (low < hight) {
|
||||
int index = partition(nums, low, hight);
|
||||
stack.push(index - 1);
|
||||
stack.push(low);
|
||||
stack.push(hight);
|
||||
stack.push(index + 1);
|
||||
}
|
||||
}
|
||||
return nums;
|
||||
}
|
||||
|
||||
public int partition (int[] nums, int low, int hight) {
|
||||
|
||||
int pivot = nums[low];
|
||||
int start = low;
|
||||
while (low < hight) {
|
||||
|
||||
while (low < hight && nums[hight] >= pivot) hight--;
|
||||
while (low < hight && nums[low] <= pivot) low++;
|
||||
if (low >= hight) break;
|
||||
swap(nums, low, hight);
|
||||
}
|
||||
swap(nums,start,low);
|
||||
return low;
|
||||
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**快速排序优化**
|
||||
|
||||
**三数取中法**
|
||||
|
||||
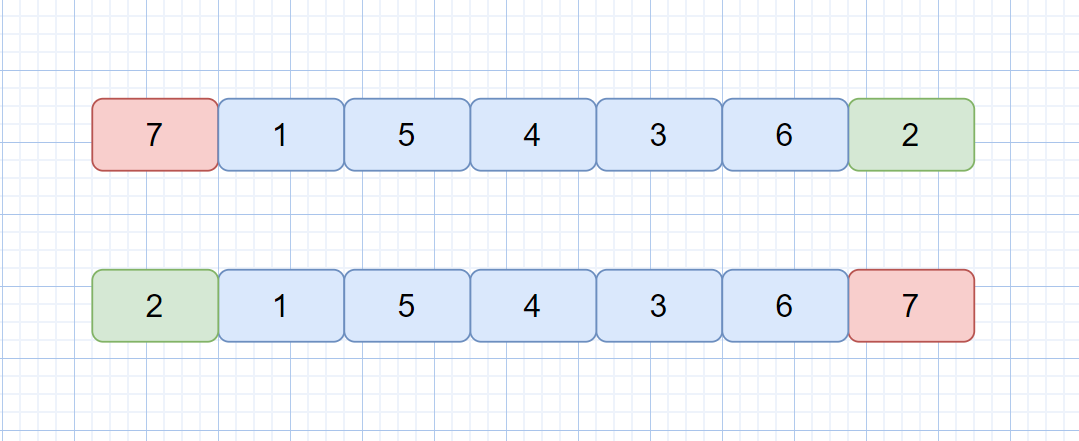
我们在上面的例子中选取的都是 nums[low] 做为我们的基准值,那么当我们遇到特殊情况时呢?见下图
|
||||
|
||||
|
||||
|
||||
我们按上面的方法,选取第一个元素做为基准元素,那么我们执行一轮排序后,发现仅仅是交换了 2 和 7 的位置,这是因为 7 为序列的最大值。所以我们的 pivot 的选取尤为重要,选取时应尽量避免选取序列的最大或最小值做为基准值。则我们可以利用三数取中法来选取基准值。
|
||||
|
||||
也就是选取三个元素中的中间值放到 nums[low] 的位置,做为基准值。这样就避免了使用最大值或最小值做为基准值。
|
||||
|
||||
所以我们可以加上这几行代码实现三数取中法。
|
||||
|
||||
```java
|
||||
int mid = low + ((hight-low) >> 1);
|
||||
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
||||
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
||||
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
||||
```
|
||||
|
||||
其含义就是让我们将中间元素放到 nums[low] 位置做为基准值,最大值放到 nums[hight],最小值放到 nums[mid],即 [4,2,3] 经过上面代码处理后,则变成了 [3,2,4].此时我们选取 3 做为基准值,这样也就避免掉了选取最大或最小值做为基准值的情况。
|
||||
|
||||
**三数取中法**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public int[] sortArray(int[] nums) {
|
||||
quickSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
}
|
||||
public void quickSort (int[] nums, int low, int hight) {
|
||||
if (low < hight) {
|
||||
int index = partition(nums,low,hight);
|
||||
quickSort(nums,low,index-1);
|
||||
quickSort(nums,index+1,hight);
|
||||
}
|
||||
}
|
||||
|
||||
public int partition (int[] nums, int low, int hight) {
|
||||
//三数取中,大家也可以使用其他方法
|
||||
int mid = low + ((hight-low) >> 1);
|
||||
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
||||
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
||||
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
||||
//下面和之前一样,仅仅是多了上面几行代码
|
||||
int pivot = nums[low];
|
||||
int start = low;
|
||||
while (low < hight) {
|
||||
while (low < hight && nums[hight] >= pivot) hight--;
|
||||
while (low < hight && nums[low] <= pivot) low++;
|
||||
if (low >= hight) break;
|
||||
swap(nums, low, hight);
|
||||
}
|
||||
swap(nums,start,low);
|
||||
return low;
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**和插入排序搭配使用**
|
||||
|
||||
我们之前说过,插入排序在元素个数较少时效率是最高的,所以当元素数量较少时,快速排序反而不如插入排序好用,所以我们可以设定一个阈值,当元素个数大于阈值时使用快速排序,小于等于该阈值时则使用插入排序。我们设定阈值为 7 。
|
||||
|
||||
**三数取中+插入排序**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
private static final int INSERTION_SORT_MAX_LENGTH = 7;
|
||||
|
||||
public int[] sortArray(int[] nums) {
|
||||
quickSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
}
|
||||
|
||||
public void quickSort (int[] nums, int low, int hight) {
|
||||
|
||||
if (hight - low <= INSERTION_SORT_MAX_LENGTH) {
|
||||
insertSort(nums,low,hight);
|
||||
return;
|
||||
}
|
||||
int index = partition(nums,low,hight);
|
||||
quickSort(nums,low,index-1);
|
||||
quickSort(nums,index+1,hight);
|
||||
}
|
||||
|
||||
public int partition (int[] nums, int low, int hight) {
|
||||
//三数取中,大家也可以使用其他方法
|
||||
int mid = low + ((hight-low) >> 1);
|
||||
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
||||
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
||||
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
||||
int pivot = nums[low];
|
||||
int start = low;
|
||||
while (low < hight) {
|
||||
while (low < hight && nums[hight] >= pivot) hight--;
|
||||
while (low < hight && nums[low] <= pivot) low++;
|
||||
if (low >= hight) break;
|
||||
swap(nums, low, hight);
|
||||
}
|
||||
swap(nums,start,low);
|
||||
return low;
|
||||
}
|
||||
|
||||
public void insertSort (int[] nums, int low, int hight) {
|
||||
|
||||
for (int i = low+1; i <= hight; ++i) {
|
||||
int temp = nums[i];
|
||||
int j;
|
||||
for (j = i-1; j >= 0; --j) {
|
||||
if (temp < nums[j]) {
|
||||
nums[j+1] = nums[j];
|
||||
continue;
|
||||
}
|
||||
break;
|
||||
}
|
||||
nums[j+1] = temp;
|
||||
}
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
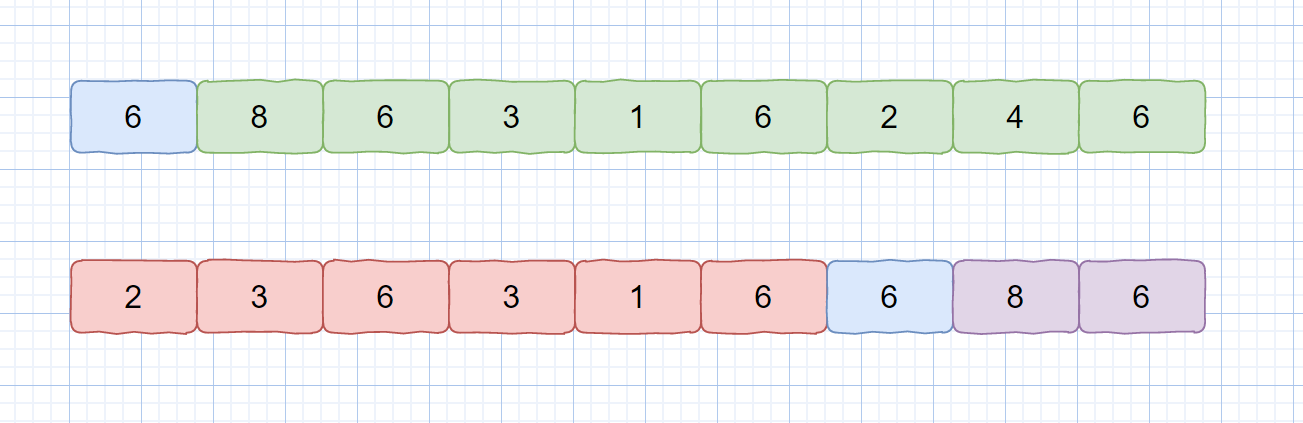
我们继续看下面这种情况
|
||||
|
||||
|
||||
|
||||
我们对其执行一次排序后,则会变成上面这种情况,然后我们继续对蓝色基准值的左区间和右区间执行相同操作。也就是 [2,3,6,3,1,6] 和 [8,6] 。我们注意观察一次排序的结果数组中是含有很多重复元素的。
|
||||
|
||||
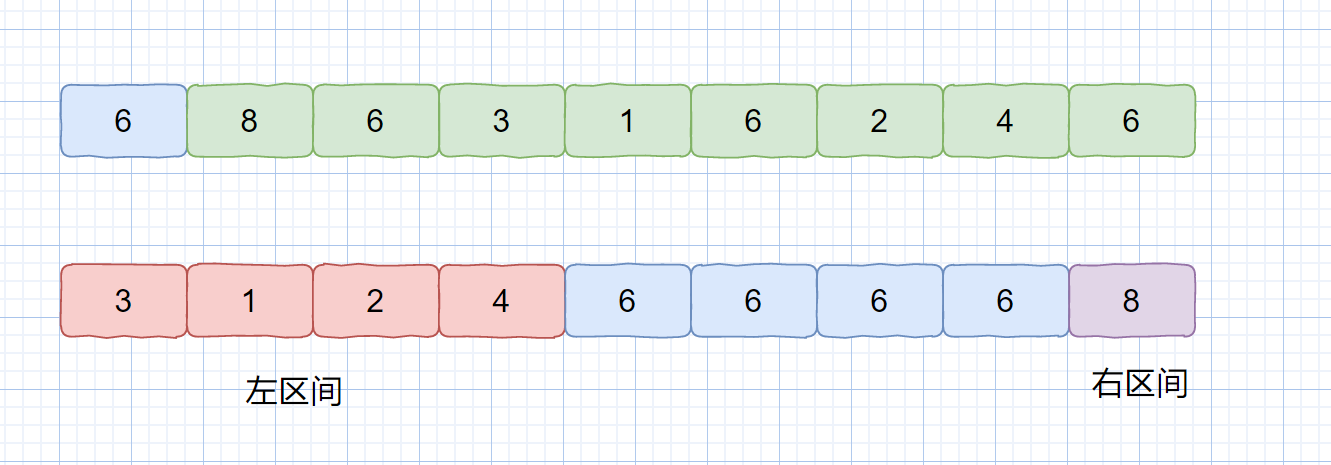
那么我们为什么不能将相同元素放到一起呢?这样就能大大减小递归调用时的区间大小,见下图。
|
||||
|
||||
|
||||
|
||||
这样就减小了我们的区间大小,将数组切分成了三部分,小于基准数的左区间,大于基准数的右区间,等于基准数的中间区间。
|
||||
|
||||
下面我们来看一下如何达到上面的情况,我们先来进行视频模拟,模拟之后应该就能明白啦。
|
||||
|
||||

|
||||
|
||||
我们来剖析一下视频,其实原理很简单,我们利用探路指针也就是 i,遇到比 pivot 大的元素,则和 right 指针进行交换,此时 right 指向的元素肯定比 pivot 大,则 right--,但是,此时我们的 nums[i] 指向的元素并不知道情况,所以我们的 i 指针不动,如果此时 nums[i] < pivot 则与 left 指针交换,注意此时我们的 left 指向的值肯定是 等于 povit的,所以交换后我们要 left++,i++, nums[i] == pivot 时,仅需要 i++ 即可,继续判断下一个元素。 我们也可以借助这个思想来解决经典的荷兰国旗问题。
|
||||
|
||||
好啦,我们下面直接看代码吧。
|
||||
|
||||
**三数取中+三向切分+插入排序**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
private static final int INSERTION_SORT_MAX_LENGTH = 7;
|
||||
public int[] sortArray(int[] nums) {
|
||||
quickSort(nums,0,nums.length-1);
|
||||
return nums;
|
||||
|
||||
}
|
||||
public void quickSort(int nums[], int low, int hight) {
|
||||
//插入排序
|
||||
if (hight - low <= INSERTION_SORT_MAX_LENGTH) {
|
||||
insertSort(nums,low,hight);
|
||||
return;
|
||||
}
|
||||
//三数取中
|
||||
int mid = low + ((hight-low) >> 1);
|
||||
if (nums[low] > nums[hight]) swap(nums,low,hight);
|
||||
if (nums[mid] > nums[hight]) swap(nums,mid,hight);
|
||||
if (nums[mid] > nums[low]) swap(nums,mid,low);
|
||||
//三向切分
|
||||
int left = low, i = low + 1, right = hight;
|
||||
int pvoit = nums[low];
|
||||
while (i <= right) {
|
||||
if (pvoit < nums[i]) {
|
||||
swap(nums,i,right);
|
||||
right--;
|
||||
} else if (pvoit == nums[i]) {
|
||||
i++;
|
||||
} else {
|
||||
swap(nums,left,i);
|
||||
left++;
|
||||
i++;
|
||||
}
|
||||
}
|
||||
quickSort(nums,low,left-1);
|
||||
quickSort(nums,right+1,hight);
|
||||
}
|
||||
public void insertSort (int[] nums, int low, int hight) {
|
||||
|
||||
for (int i = low+1; i <= hight; ++i) {
|
||||
int temp = nums[i];
|
||||
int j;
|
||||
for (j = i-1; j >= 0; --j) {
|
||||
if (temp < nums[j]) {
|
||||
nums[j+1] = nums[j];
|
||||
continue;
|
||||
}
|
||||
break;
|
||||
}
|
||||
nums[j+1] = temp;
|
||||
}
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
好啦,一些常用的优化方法都整理出来啦,还有一些其他的优化算法九数取中,优化递归操作等就不在这里进行描述啦,感兴趣的可以自己看一下。好啦,这期的文章就到这里啦,我们下期见,拜了个拜。
|
||||
|
||||
146
gif-algorithm/数据结构和算法/荷兰国旗.md
Normal file
146
gif-algorithm/数据结构和算法/荷兰国旗.md
Normal file
@@ -0,0 +1,146 @@
|
||||
今天我们一起来看一下可以用快速排序秒杀的经典题,或许这些题目大家已经做过,不过可以再来一起复习一遍,加深印象。
|
||||
|
||||
阅读这篇文章之前,大家要先去看一下我之前写过的快速排序,这样才不会对这篇文章一知半解。好啦,我们一起开整吧。
|
||||
|
||||
在上篇文章中,我们提到了,快速排序的优化,利用三向切分来优化数组中存在大量重复元素的情况,到啦这里各位应该猜到我想写什么了吧,
|
||||
|
||||
我们今天先来说一下那个非常经典的荷兰国旗问题。
|
||||
|
||||
> 题目来源:https://www.jianshu.com/p/356604b8903f
|
||||
|
||||
问题描述:
|
||||
|
||||
荷兰国旗是由红白蓝3种颜色的条纹拼接而成,如下图所示:
|
||||
|
||||

|
||||
|
||||
假设这样的条纹有多条,且各种颜色的数量不一,并且随机组成了一个新的图形,新的图形可能如下图所示,但是绝非只有这一种情况:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
需求是:把这些条纹按照颜色排好,红色的在上半部分,白色的在中间部分,蓝色的在下半部分,我们把这类问题称作荷兰国旗问题。
|
||||
|
||||
我们把荷兰国旗问题用数组的形式表达一下是这样的:
|
||||
|
||||
给定一个整数数组,给定一个值K,这个值在原数组中一定存在,要求把数组中小于 K 的元素放到数组的左边,大于K的元素放到数组的右边,等于K的元素放到数组的中间,最终返回一个整数数组,其中只有两个值,分别是等于K的数组部分的左右两个下标值。
|
||||
|
||||
例如,给定数组:[2, 3, 1, 9, 7, 6, 1, 4, 5],给定一个值4,那么经过处理原数组可能得一种情况是:[2, 3, 1, 1, 4, 9, 7, 6, 5],需要注意的是,小于4的部分不需要有序,大于4的部分也不需要有序,返回等于4部分的左右两个下标,即[4, 4]
|
||||
|
||||
这不就是我们之前说过的三向切分吗?一模一样!
|
||||
|
||||
那么 leetcode 有没有相似问题呢?我们一起来看下面这道题
|
||||
|
||||
**leetcode 75 颜色分类**
|
||||
|
||||
题目描述:
|
||||
|
||||
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
|
||||
|
||||
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
|
||||
|
||||
示例 1:
|
||||
|
||||
> 输入:nums = [2,0,2,1,1,0]
|
||||
> 输出:[0,0,1,1,2,2]
|
||||
|
||||
示例 2:
|
||||
|
||||
> 输入:nums = [2,0,1]
|
||||
> 输出:[0,1,2]
|
||||
|
||||
示例 3:
|
||||
|
||||
> 输入:nums = [0]
|
||||
> 输出:[0]
|
||||
|
||||
示例 4:
|
||||
|
||||
> 输入:nums = [1]
|
||||
> 输出:[1]
|
||||
|
||||
**做题思路**
|
||||
|
||||
这个题目我们使用 Arrays.sort() 解决,哈哈,但是那样太无聊啦,题目含义就是让我们将所有的 0 放在前面,2放在后面,1 放在中间,是不是和我们上面说的荷兰国旗问题一样。我们仅仅将 1 做为 pivot 值。
|
||||
|
||||
下面我们直接看代码吧,和三向切分基本一致。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public void sortColors(int[] nums) {
|
||||
int len = nums.length;
|
||||
int left = 0;
|
||||
//这里和三向切分不完全一致
|
||||
int i = left;
|
||||
int right = len-1;
|
||||
|
||||
while (i <= right) {
|
||||
if (nums[i] == 2) {
|
||||
swap(nums,i,right--);
|
||||
} else if (nums[i] == 0) {
|
||||
swap(nums,i++,left++);
|
||||
} else {
|
||||
i++;
|
||||
}
|
||||
}
|
||||
}
|
||||
public void swap (int[] nums, int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
另外我们看这段代码,有什么问题呢?那就是我们即使完全符合时,仍会交换元素,这样会大大降低我们的效率。
|
||||
|
||||
例如:[0,0,0,1,1,1,2,2,2]
|
||||
|
||||
此时我们完全符合情况,不需要交换元素,但是按照我们上面的代码,0,2 的每个元素会和自己进行交换,所以这里我们可以根据 i 和 left 的值是否相等来决定是否需要交换,大家可以自己写一下。
|
||||
|
||||
下面我们看一下另外一种写法
|
||||
|
||||
这个题目的关键点就是,当我们 nums[i] 和 nums[right] 交换后,我们的 nums[right] 此时指向的元素是符合要求的,但是我们 nums[i] 指向的元素不一定符合要求,所以我们需要继续判断。
|
||||
|
||||
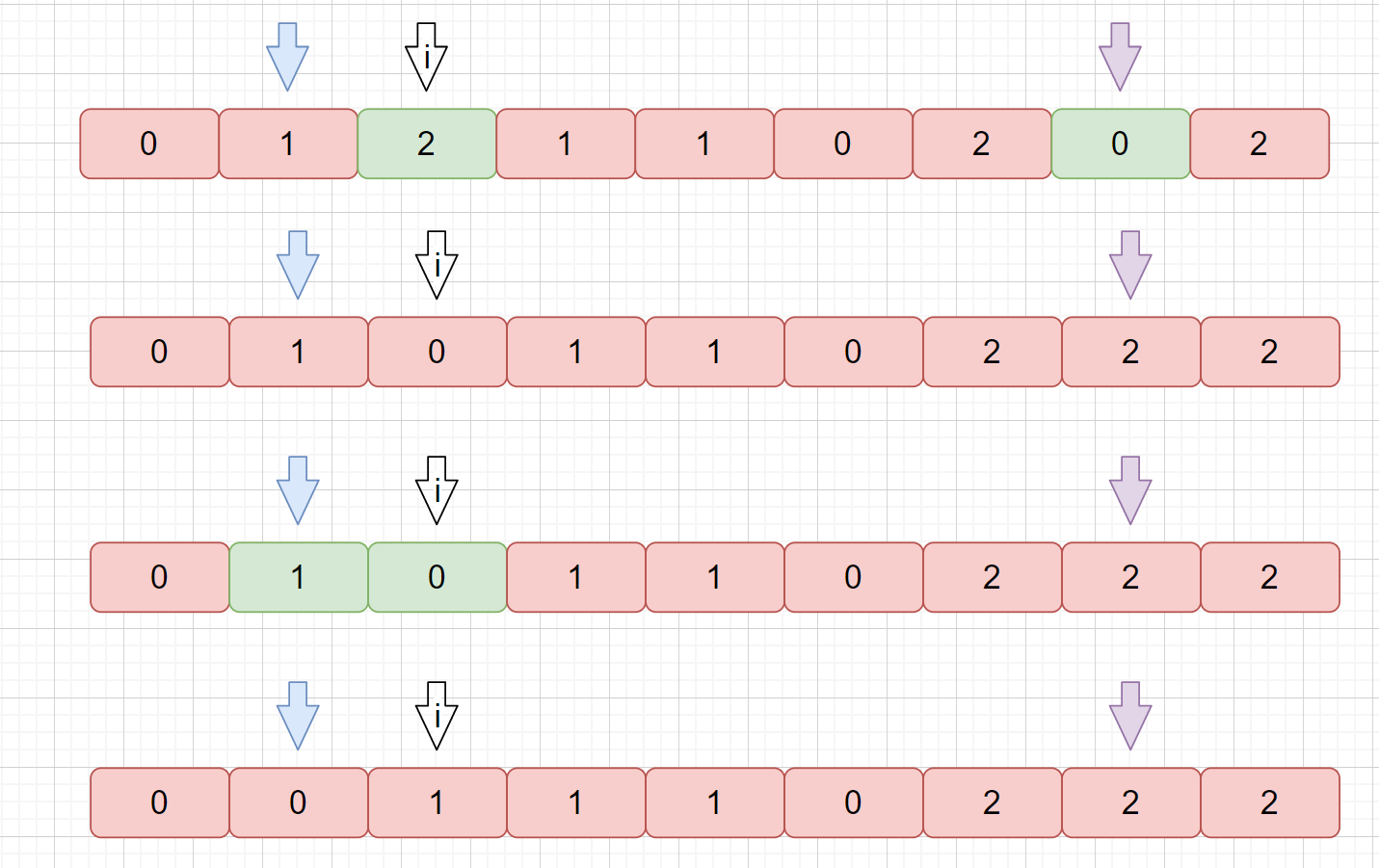
|
||||
|
||||
我们 2 和 0 交换后,此时 i 指向 0 ,0 应放在头部,所以不符合情况,所以 0 和 1 仍需要交换。下面我们来看一下动画来加深理解吧。
|
||||
|
||||

|
||||
|
||||
另一种代码表示
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
public void sortColors(int[] nums) {
|
||||
|
||||
int left = 0;
|
||||
int len = nums.length;
|
||||
int right = len - 1;
|
||||
for (int i = 0; i <= right; ++i) {
|
||||
if (nums[i] == 0) {
|
||||
swap(nums,i,left);
|
||||
left++;
|
||||
}
|
||||
if (nums[i] == 2) {
|
||||
swap(nums,i,right);
|
||||
right--;
|
||||
//如果不等于 1 则需要继续判断,所以不移动 i 指针,i--
|
||||
if (nums[i] != 1) {
|
||||
i--;
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
public void swap (int[] nums,int i, int j) {
|
||||
int temp = nums[i];
|
||||
nums[i] = nums[j];
|
||||
nums[j] = temp;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
好啦,这个问题到这就结束啦,是不是很简单啊,我们明天见!
|
||||
|
||||
180
gif-algorithm/数据结构和算法/逆序对问题.md
Normal file
180
gif-algorithm/数据结构和算法/逆序对问题.md
Normal file
@@ -0,0 +1,180 @@
|
||||
#### 逆序对
|
||||
|
||||
逆序对:在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对,见下图。
|
||||
|
||||
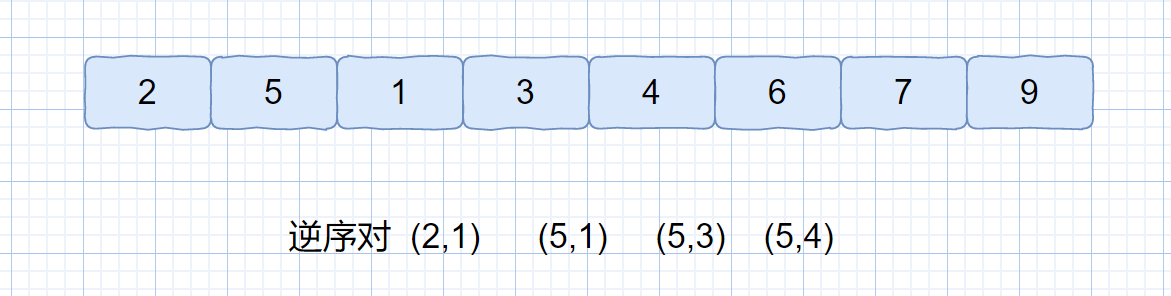
|
||||
|
||||
是不是很容易理解,因为数组是无序的,当较大的数,出现在较小数前面的时候,它俩则可以组成逆序对。因为数组的(有序度+逆序度)= n (n-1) / 2,逆序对个数 = 数组的逆序度,有序对个数 = 数组的有序度,所以我们知道有序对个数的话,也能得到逆序对的个数。另外我们如何通过归并排序来计算逆序对个数呢?
|
||||
|
||||
关键点在我们的**归并过程中**,我们先来看下归并过程中是怎么计算逆序对个数的。见下图
|
||||
|
||||
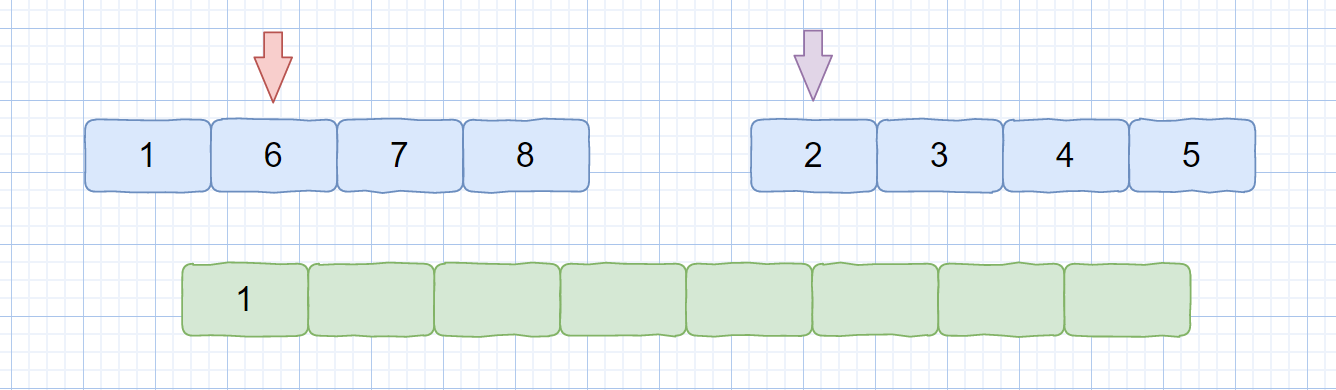
|
||||
|
||||
我们来拆解下上图,我们此时 temp1 指向元素为 6,temp2 指向元素为 2, nums[temp1] > temp[temp2],则此时我们需要将 temp2 指向的元素存入临时数组中,又因为每个小集合中的元素都是有序的,所以 temp1 后面的元素也一定大于 2,那么我们就可以根据 temp1 的索引得出逆序对中包含 2 的逆序对个数,则是 mid - temp + 1。
|
||||
|
||||
好啦这个题目你已经会做啦,下面我们一起来做下吧。
|
||||
|
||||
**题目描述**
|
||||
|
||||
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
|
||||
|
||||
**示例 1:**
|
||||
|
||||
> 输入: [7,5,6,4]
|
||||
> 输出: 5
|
||||
|
||||
**题目解析**
|
||||
|
||||
各位如果忘记归并排序的话,可以再看一下咱们之前的文章回顾一下 [归并排序详解](https://mp.weixin.qq.com/s/YK43J73UNFRjX4r0vh13ZA),这个题目我们仅仅在归并排序的基础上加了一行代码。那就是在归并过程时,nums[temp2] < nums[temp1] 时统计个数。下面我们直接看代码吧。
|
||||
|
||||
**题目代码**
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
//全局变量
|
||||
private int count;
|
||||
public int reversePairs(int[] nums) {
|
||||
count = 0;
|
||||
merge(nums,0,nums.length-1);
|
||||
return count;
|
||||
}
|
||||
|
||||
public void merge (int[] nums, int left, int right) {
|
||||
|
||||
if (left < right) {
|
||||
int mid = left + ((right - left) >> 1);
|
||||
merge(nums,left,mid);
|
||||
merge(nums,mid+1,right);
|
||||
mergeSort(nums,left,mid,right);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
public void mergeSort(int[] nums, int left, int mid, int right) {
|
||||
|
||||
int[] temparr = new int[right-left+1];
|
||||
int index = 0;
|
||||
int temp1 = left, temp2 = mid+1;
|
||||
|
||||
while (temp1 <= mid && temp2 <= right) {
|
||||
|
||||
if (nums[temp1] <= nums[temp2]) {
|
||||
temparr[index++] = nums[temp1++];
|
||||
} else {
|
||||
//增加的一行代码,用来统计逆序对个数
|
||||
count += (mid - temp1 + 1);
|
||||
temparr[index++] = nums[temp2++];
|
||||
}
|
||||
}
|
||||
|
||||
if (temp1 <= mid) System.arraycopy(nums,temp1,temparr,index,mid-temp1+1);
|
||||
if (temp2 <= right) System.arraycopy(nums,temp2,temparr,index,right-temp2+1);
|
||||
System.arraycopy(temparr,0,nums,left,right-left+1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
好啦,这个题目我们就解决啦,哦对,大家也可以顺手去解决下这个题目。leetcode 912 排序数组,这个题目大家可以用来练手,因为有些排序算法是面试高频考点,所以大家可以防止遗忘,多用这个题目进行练习,防止手生。下面则是我写文章时代码的提交情况,冒泡排序怎么优化都会超时,其他排序算法倒是都可以通过。
|
||||
|
||||
|
||||
|
||||
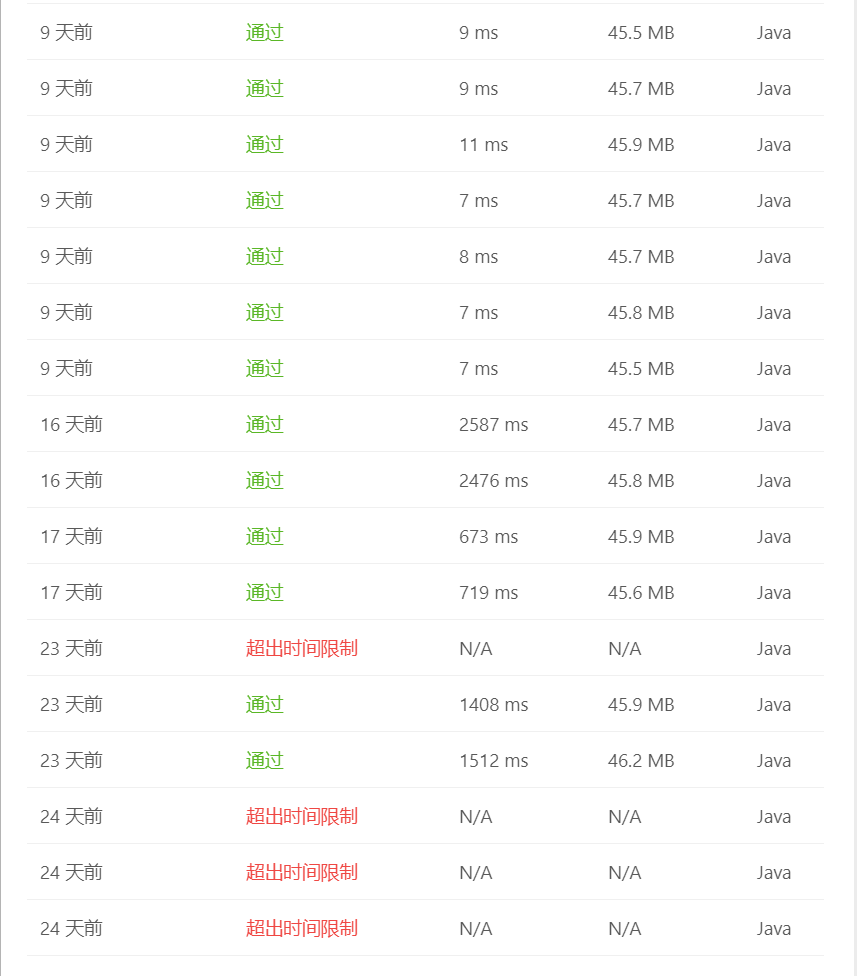
|
||||
|
||||
|
||||
|
||||
好啦,下面我们继续做一个题目吧,也完全可以用归并排序解决,稍微加了一丢丢代码,但是也是很好理解的。
|
||||
|
||||
#### 翻转对
|
||||
|
||||
**题目描述**
|
||||
|
||||
给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。
|
||||
|
||||
你需要返回给定数组中的重要翻转对的数量。
|
||||
|
||||
示例 1:
|
||||
|
||||
> 输入: [1,3,2,3,1]
|
||||
> 输出: 2
|
||||
|
||||
示例 2:
|
||||
|
||||
> 输入: [2,4,3,5,1]
|
||||
> 输出: 3
|
||||
|
||||
**题目解析**
|
||||
|
||||
我们理解了逆序对的含义之后,题目理解起来完全没有压力的,这个题目第一想法可能就是用暴力法解决,但是会超时,所以我们有没有办法利用归并排序来完成呢?
|
||||
|
||||
我们继续回顾一下归并排序的归并过程,两个小集合是有序的,然后我们需要将小集合归并到大集合中,则我们完全可以在归并之前,先统计一下翻转对的个数,然后再进行归并,则最后排序完成之后自然也就得出了翻转对的个数。具体过程见下图。
|
||||
|
||||

|
||||
|
||||
此时我们发现 6 > 2 * 2,所以此时是符合情况的,因为小数组是单调递增的,所以 6 后面的元素都符合条件,所以我们 count += mid - temp1 + 1;则我们需要移动紫色指针,判断后面是否还存在符合条件的情况。
|
||||
|
||||

|
||||
|
||||
我们此时发现 6 = 3 * 2,不符合情况,因为小数组都是完全有序的,所以我们可以移动红色指针,看下后面的数有没有符合条件的情况。这样我们就可以得到翻转对的数目啦。下面我们直接看动图加深下印象吧!
|
||||
|
||||

|
||||
|
||||
是不是很容易理解啊,那我们直接看代码吧,仅仅是在归并排序的基础上加了几行代码。
|
||||
|
||||
```java
|
||||
class Solution {
|
||||
private int count;
|
||||
|
||||
public int reversePairs(int[] nums) {
|
||||
count = 0;
|
||||
merge(nums, 0, nums.length - 1);
|
||||
return count;
|
||||
}
|
||||
|
||||
public void merge(int[] nums, int left, int right) {
|
||||
|
||||
if (left < right) {
|
||||
int mid = left + ((right - left) >> 1);
|
||||
merge(nums, left, mid);
|
||||
merge(nums, mid + 1, right);
|
||||
mergeSort(nums, left, mid, right);
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
public void mergeSort(int[] nums, int left, int mid, int right) {
|
||||
|
||||
int[] temparr = new int[right - left + 1];
|
||||
int temp1 = left, temp2 = mid + 1, index = 0;
|
||||
//计算翻转对
|
||||
while (temp1 <= mid && temp2 <= right) {
|
||||
//这里需要防止溢出
|
||||
if (nums[temp1] > 2 * (long) nums[temp2]) {
|
||||
count += mid - temp1 + 1;
|
||||
temp2++;
|
||||
} else {
|
||||
temp1++;
|
||||
}
|
||||
}
|
||||
//记得归位,我们还要继续使用
|
||||
temp1 = left;
|
||||
temp2 = mid + 1;
|
||||
//归并排序
|
||||
while (temp1 <= mid && temp2 <= right) {
|
||||
|
||||
if (nums[temp1] <= nums[temp2]) {
|
||||
temparr[index++] = nums[temp1++];
|
||||
} else {
|
||||
temparr[index++] = nums[temp2++];
|
||||
}
|
||||
}
|
||||
//照旧
|
||||
if (temp1 <= mid) System.arraycopy(nums, temp1, temparr, index, mid - temp1 + 1);
|
||||
if (temp2 <= right) System.arraycopy(nums, temp2, temparr, index, right - temp2 + 1);
|
||||
System.arraycopy(temparr, 0, nums, left, right - left + 1);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
###
|
||||
Reference in New Issue
Block a user