mirror of
https://github.com/chefyuan/algorithm-base.git
synced 2024-11-16 17:13:39 +00:00
487 lines
22 KiB
Markdown
487 lines
22 KiB
Markdown
|
|
|
|||
|
|
|
|||
|
|
> 为保证代码严谨性,文中所有代码均在 leetcode 刷题网站 AC ,大家可以放心食用。
|
|||
|
|
|
|||
|
|
皇上生辰之际,举国同庆,袁记菜馆作为天下第一饭店,所以被选为这次庆典的菜品供应方,这次庆典对于袁记菜馆是一项前所未有的挑战,毕竟是第一次给皇上庆祝生辰,稍有不慎就是掉脑袋的大罪,整个袁记菜馆内都在紧张的布置着。此时突然有一个店小二慌慌张张跑到袁厨面前汇报,到底发生了什么事,让店小二如此慌张呢?
|
|||
|
|
|
|||
|
|
袁记菜馆内
|
|||
|
|
|
|||
|
|
店小二:不好了不好了,掌柜的,出大事了。
|
|||
|
|
|
|||
|
|
袁厨:发生什么事了,慢慢说,如此慌张,成何体统。(开店开久了,架子出来了哈)
|
|||
|
|
|
|||
|
|
店小二:皇上按照咱们菜单点了 666 道菜,但是咱们做西湖醋鱼的师傅请假回家结婚了,不知道皇上有没有点这道菜,如果点了这道菜,咱们做不出来,那咱们店可就完了啊。
|
|||
|
|
|
|||
|
|
(袁厨听了之后,吓得一屁股坐地上了,缓了半天说道)
|
|||
|
|
|
|||
|
|
袁厨:别说那么多了,快给我找找皇上点的菜里面,有没有这道菜!
|
|||
|
|
|
|||
|
|
找了很久,并且核对了很多遍,最后确认皇上没有点这道菜。菜馆内的人都松了一口气
|
|||
|
|
|
|||
|
|
通过上面的一个例子,让我们简单了解了字符串匹配。
|
|||
|
|
|
|||
|
|
字符串匹配:设 S 和 T 是给定的两个串,在主串 S 中找到模式串 T 的过程称为字符串匹配,如果在主串 S 中找到 模式串 T ,则称匹配成功,函数返回 T 在 S 中首次出现的位置,否则匹配不成功,返回 -1。
|
|||
|
|
|
|||
|
|
例:
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
在上图中,我们试图找到模式 T = baab,在主串 S = abcabaabcabac 中第一次出现的位置,即为红色阴影部分, T 第一次在 S 中出现的位置下标为 4 ( 字符串的首位下标是 0 ),所以返回 4。如果模式串 T 没有在主串 S 中出现,则返回 -1。
|
|||
|
|
|
|||
|
|
解决上面问题的算法我们称之为字符串匹配算法,今天我们来介绍三种字符串匹配算法,大家记得打卡呀,说不准面试的时候就问到啦。
|
|||
|
|
|
|||
|
|
## BF算法(Brute Force)
|
|||
|
|
|
|||
|
|
这个算法很容易理解,就是我们将模式串和主串进行比较,一致时则继续比较下一字符,直到比较完整个模式串。不一致时则将模式串后移一位,重新从模式串的首位开始对比,重复刚才的步骤下面我们看下这个方法的动图解析,看完肯定一下就能搞懂啦。
|
|||
|
|
|
|||
|
|
视频详解
|
|||
|
|
|
|||
|
|
**因为不可以放置视频,所以想看视频的同学,可以去看公众号原文,那里有视频**
|
|||
|
|
|
|||
|
|
通过上面的代码是不是一下就将这个算法搞懂啦,下面我们用这个算法来解决下面这个经典题目吧。
|
|||
|
|
|
|||
|
|
### leetcdoe 28. 实现 strStr()
|
|||
|
|
|
|||
|
|
#### 题目描述
|
|||
|
|
|
|||
|
|
给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
|
|||
|
|
|
|||
|
|
示例 1:
|
|||
|
|
|
|||
|
|
> 输入: haystack = "hello", needle = "ll"
|
|||
|
|
> 输出: 2
|
|||
|
|
|
|||
|
|
示例 2:
|
|||
|
|
|
|||
|
|
> 输入: haystack = "aaaaa", needle = "bba"
|
|||
|
|
> 输出: -1
|
|||
|
|
|
|||
|
|
#### 题目解析
|
|||
|
|
|
|||
|
|
其实这个题目很容易理解,但是我们需要注意的是一下几点,比如我们的模式串为 0 时,应该返回什么,我们的模式串长度大于主串长度时,应该返回什么,也是我们需要注意的地方。下面我们来看一下题目代码吧。
|
|||
|
|
|
|||
|
|
#### 题目代码
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int strStr(String haystack, String needle) {
|
|||
|
|
int haylen = haystack.length();
|
|||
|
|
int needlen = needle.length();
|
|||
|
|
//特殊情况
|
|||
|
|
if (haylen < needlen) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
if (needlen == 0) {
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
//主串
|
|||
|
|
for (int i = 0; i < haylen - needlen + 1; ++i) {
|
|||
|
|
int j;
|
|||
|
|
//模式串
|
|||
|
|
for (j = 0; j < needlen; j++) {
|
|||
|
|
//不符合的情况,直接跳出,主串指针后移一位
|
|||
|
|
if (haystack.charAt(i+j) != needle.charAt(j)) {
|
|||
|
|
break;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
//匹配成功
|
|||
|
|
if (j == needlen) {
|
|||
|
|
return i;
|
|||
|
|
}
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
我们看一下BF算法的另一种算法(显示回退),其实原理一样,就是对代码进行了一下修改,只要是看完咱们的动图,这个也能够一下就能看懂,大家可以结合下面代码中的注释和动图进行理解。
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int strStr(String haystack, String needle) {
|
|||
|
|
//i代表主串指针,j模式串
|
|||
|
|
int i,j;
|
|||
|
|
//主串长度和模式串长度
|
|||
|
|
int halen = haystack.length();
|
|||
|
|
int nelen = needle.length();
|
|||
|
|
//循环条件,这里只有 i 增长
|
|||
|
|
for (i = 0 , j = 0; i < halen && j < nelen; ++i) {
|
|||
|
|
//相同时,则移动 j 指针
|
|||
|
|
if (haystack.charAt(i) == needle.charAt(j)) {
|
|||
|
|
++j;
|
|||
|
|
} else {
|
|||
|
|
//不匹配时,将 j 重新指向模式串的头部,将 i 本次匹配的开始位置的下一字符
|
|||
|
|
i -= j;
|
|||
|
|
j = 0;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
//查询成功时返回索引,查询失败时返回 -1;
|
|||
|
|
int renum = j == nelen ? i - nelen : -1;
|
|||
|
|
return renum;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## BM算法(Boyer-Moore)
|
|||
|
|
|
|||
|
|
我们刚才说过了 BF 算法,但是 BF 算法是有缺陷的,比如我们下面这种情况
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
如上图所示,如果我们利用 BF 算法,遇到不匹配字符时,每次右移一位模式串,再重新从头进行匹配,我们观察一下,我们的模式串 abcdex 中每个字符都不一样,但是我们第一次进行字符串匹配时,abcde 都匹配成功,到 x 时失败,又因为模式串每位都不相同,所以我们不需要再每次右移一位,再重新比较,我们可以直接跳过某些步骤。如下图
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
我们可以跳过其中某些步骤,直接到下面这个步骤。那我们是依据什么原则呢?
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
### 坏字符规则
|
|||
|
|
|
|||
|
|
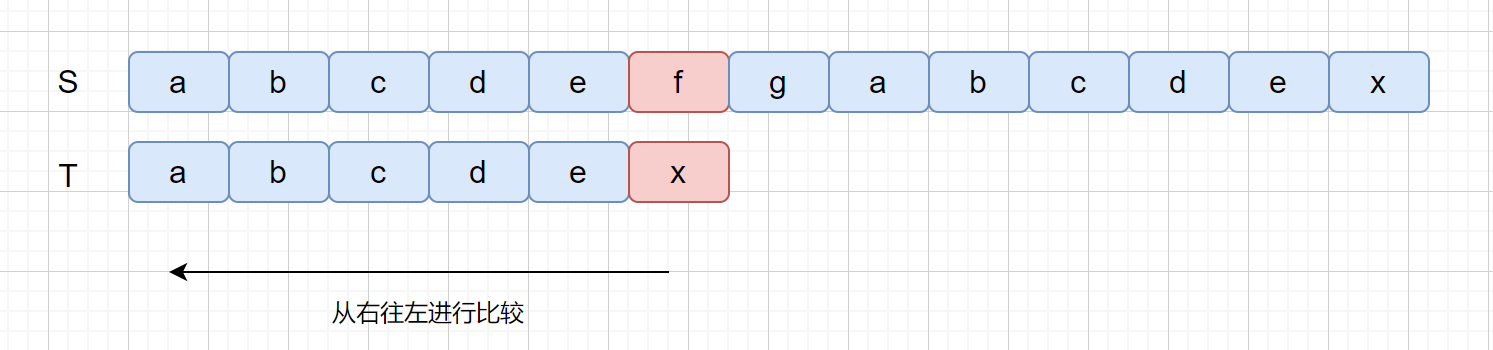
我们之前的 BF 算法是从前往后进行比较 ,BM 算法是从后往前进行比较,我们来看一下具体过程,我们还是利用上面的例子。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
BM 算法是从后往前进行比较,此时我们发现比较的第一个字符就不匹配,我们将**主串**这个字符称之为**坏字符**,也就是 f ,我们发现坏字符之后,模式串 T 中查找是否含有该字符(f),我们发现并不存在 f,此时我们只需将模式串右移到坏字符的后面一位即可。如下图
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
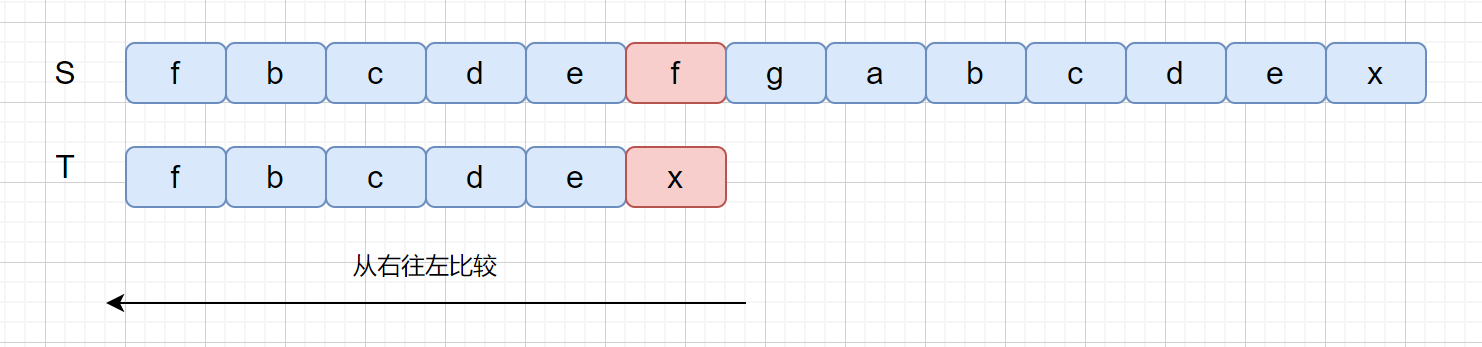
那我们在模式串中找到坏字符该怎么办呢?
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
此时我们的坏字符为 f ,我们在模式串中,查找发现含有坏字符 f,我们则需要移动模式串 T ,将模式串中的 f 和坏字符对齐。见下图。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
然后我们继续从右往左进行比较,发现 d 为坏字符,则需要将模式串中的 d 和坏字符对齐。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
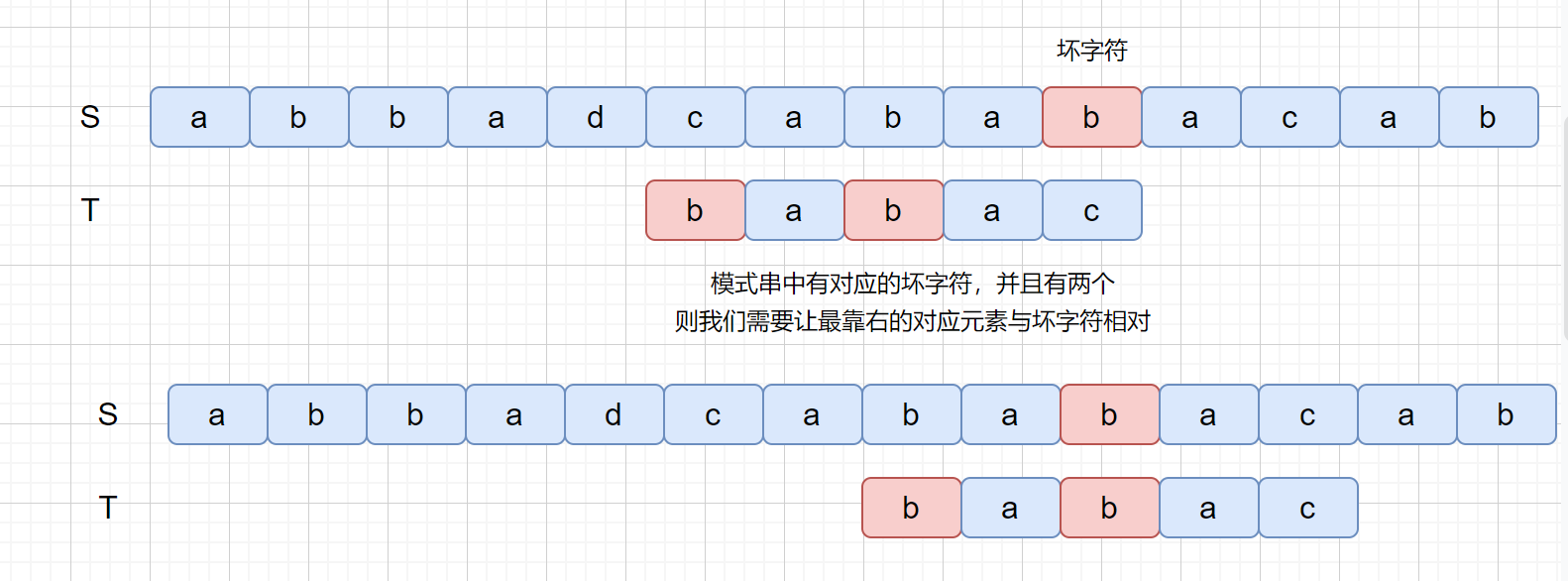
那么我们在来思考一下这种情况,那就是模式串中含有多个坏字符怎么办呢?
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
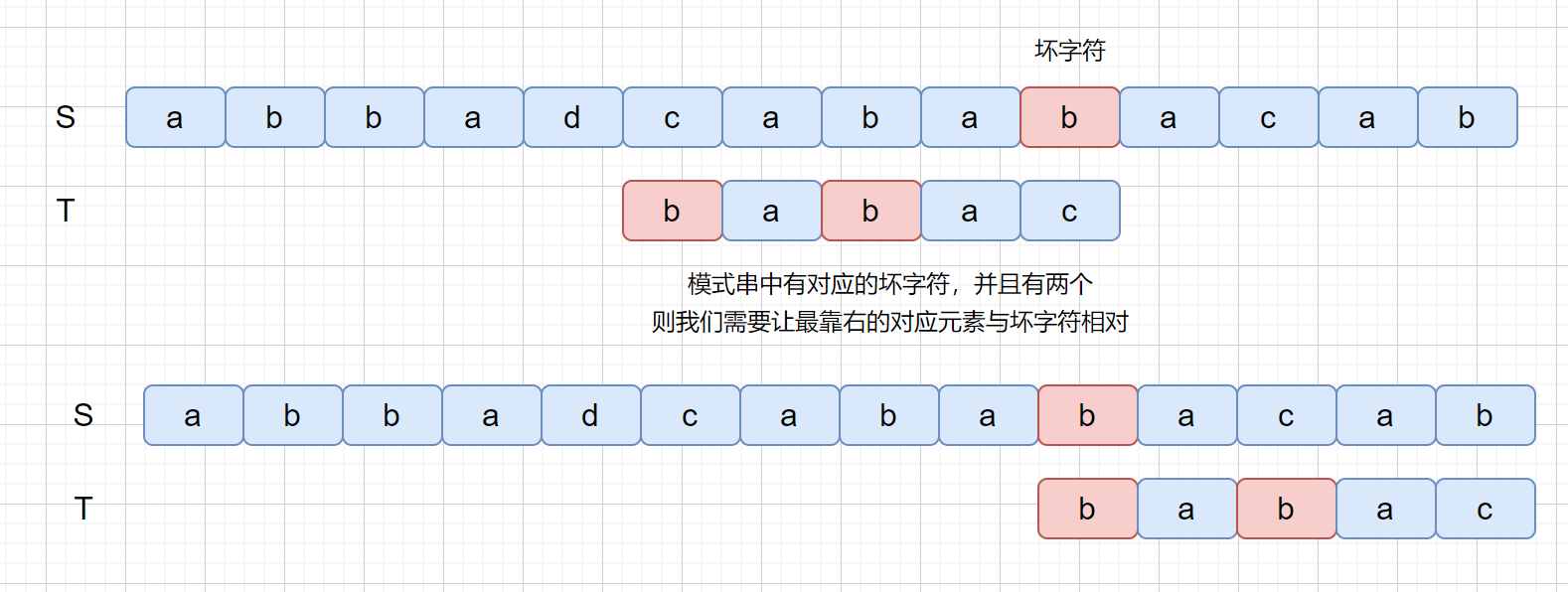
那么我们为什么要让**最靠右的对应元素与坏字符匹配**呢?如果上面的例子我们没有按照这条规则看下会产生什么问题。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
如果没有按照我们上述规则,则会**漏掉我们的真正匹配**。我们的主串中是**含有 babac** 的,但是却**没有匹配成功**,所以应该遵守**最靠右的对应字符与坏字符相对**的规则。
|
|||
|
|
|
|||
|
|
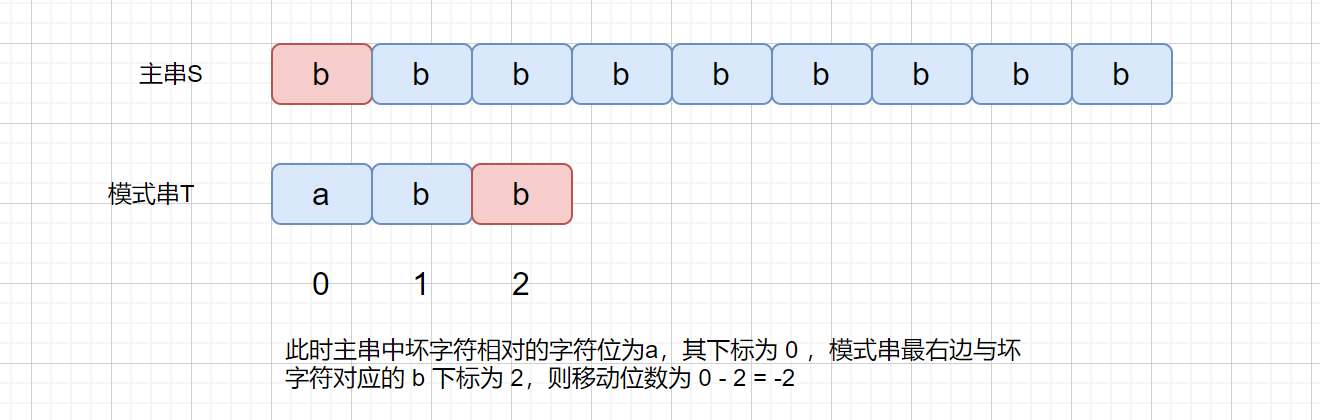
我们上面一共介绍了三种移动情况,分别是下方的模式串中没有发现与坏字符对应的字符,发现一个对应字符,发现两个。这三种情况我们分别移动不同的位数,那我们是根据依据什么来决定移动位数的呢?下面我们给图中的字符加上下标。见下图
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
下面我们来考虑一下这种情况。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
此时这种情况肯定是不行的,不往右移动,甚至还有可能左移,那么我们有没有什么办法解决这个问题呢?继续往下看吧。
|
|||
|
|
|
|||
|
|
### 好后缀规则
|
|||
|
|
|
|||
|
|
好后缀其实也很容易理解,我们之前说过 BM 算法是从右往左进行比较,下面我们来看下面这个例子。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
这里如果我们按照坏字符进行移动是不合理的,这时我们可以使用好后缀规则,那么什么是好后缀呢?
|
|||
|
|
|
|||
|
|
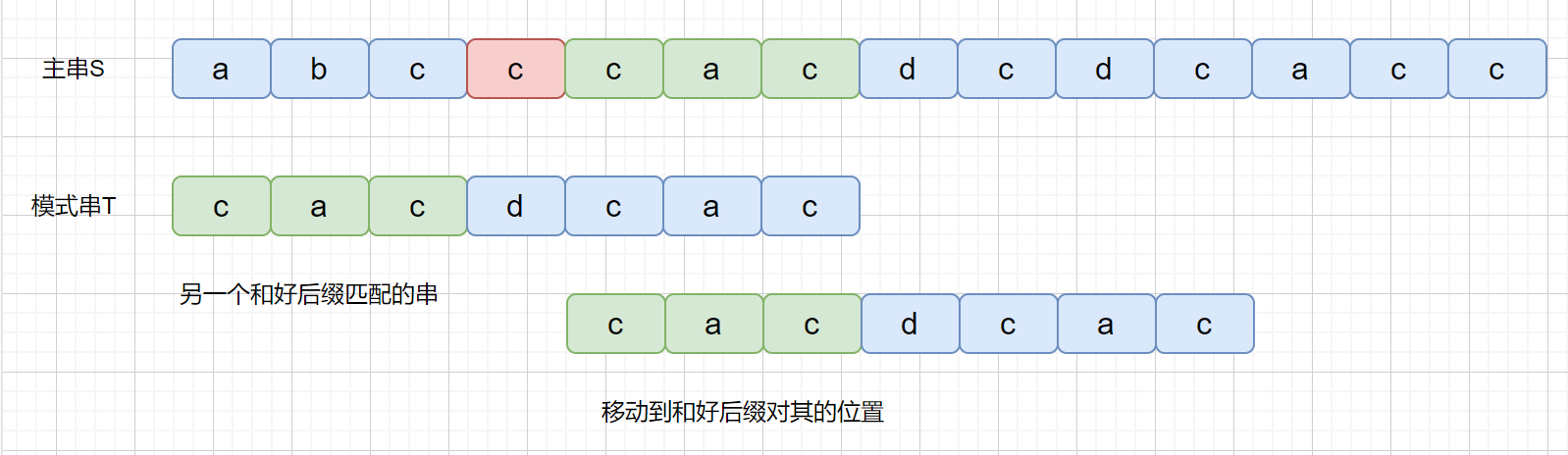
BM 算法是从右往左进行比较,发现坏字符的时候此时 cac 已经匹配成功,在红色阴影处发现坏字符。此时已经匹配成功的 cac 则为我们的好后缀,此时我们拿它在模式串中查找,如果找到了另一个和好后缀相匹配的串,那我们就将另一个和**好后缀相匹配**的串 ,滑到和好后缀对齐的位置。
|
|||
|
|
|
|||
|
|
是不是感觉有点拗口,没关系,我们看下图,红色代表坏字符,绿色代表好后缀
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
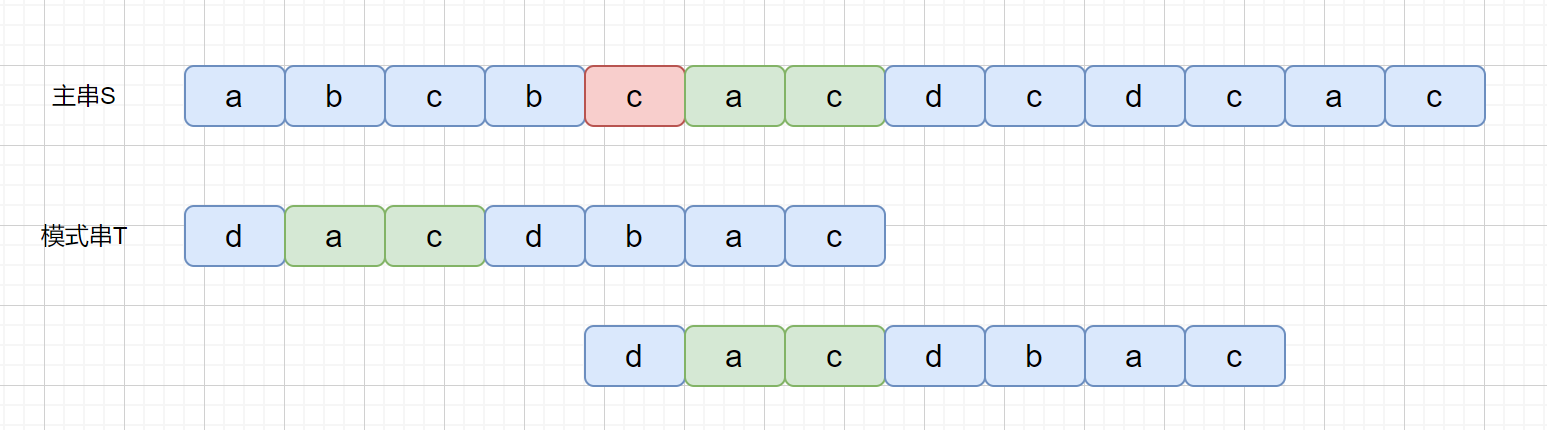
上面那种情况搞懂了,但是我们思考一下下面这种情况
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
上面我们说到了,如果在模式串的**头部**没有发现好后缀,发现好后缀的子串也可以。但是为什么要强调这个头部呢?
|
|||
|
|
|
|||
|
|
我们下面来看一下这种情况
|
|||
|
|
|
|||
|
|
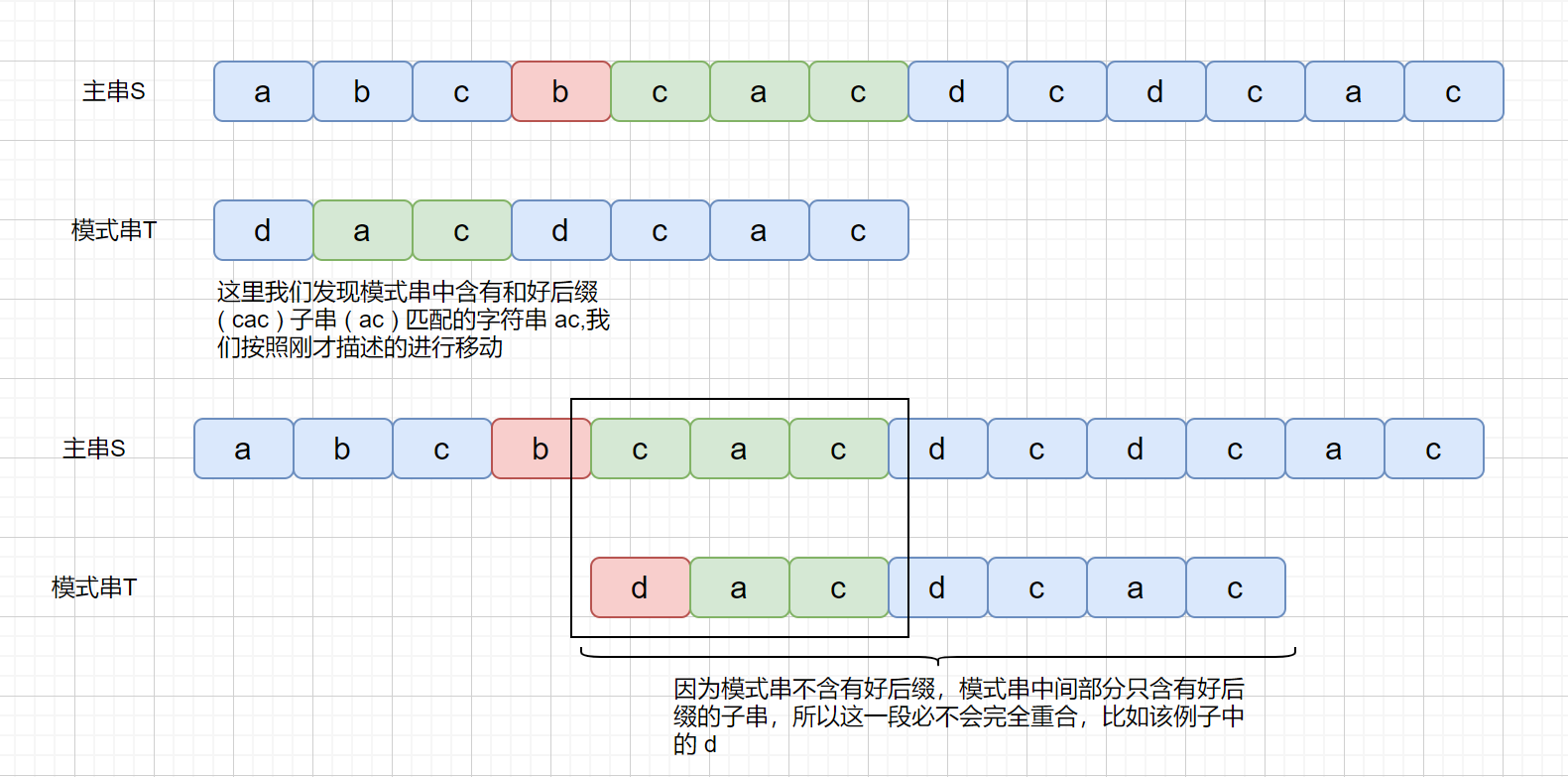
|
|||
|
|
|
|||
|
|
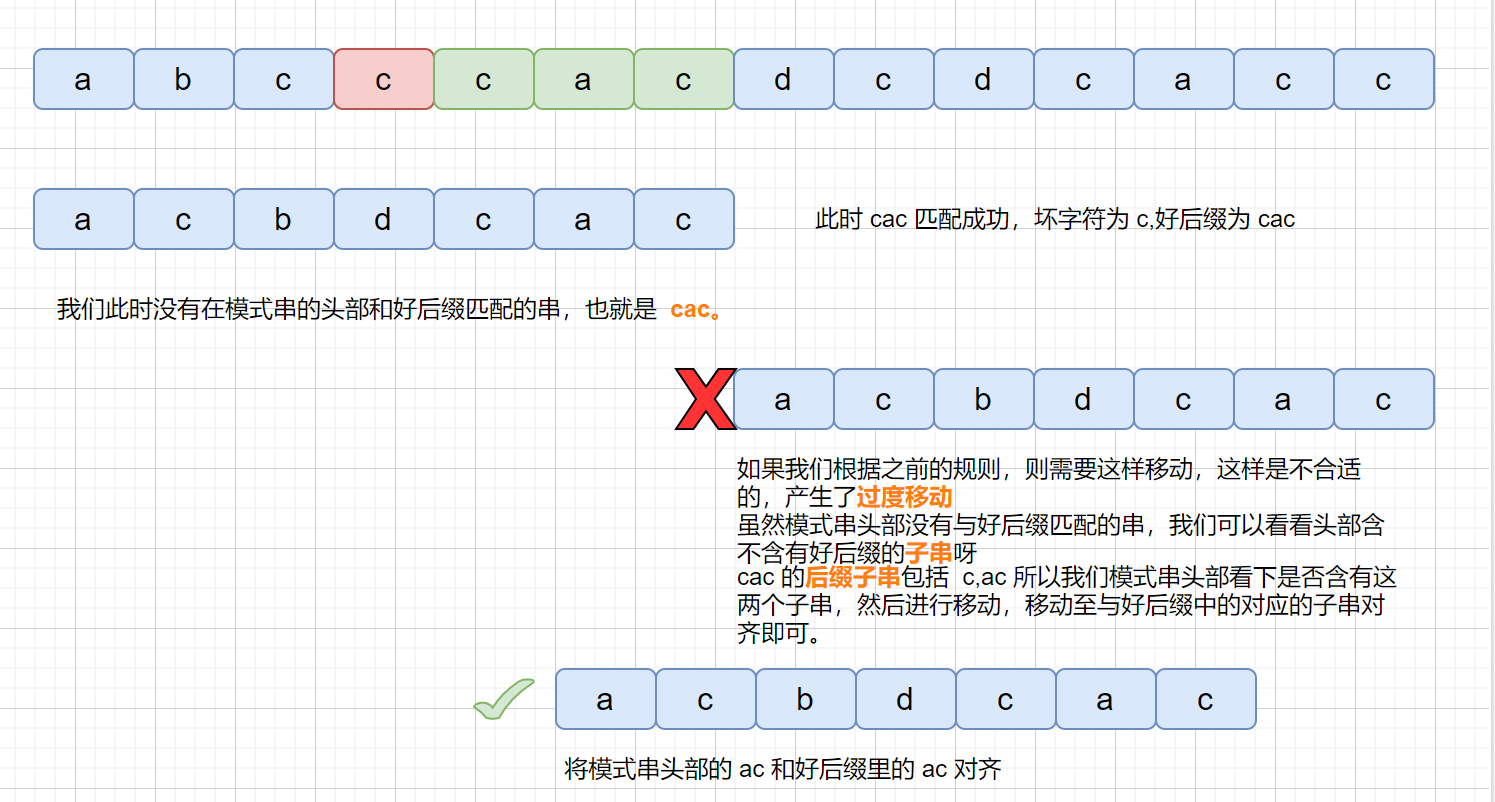
但是当我们在头部发现好后缀的子串时,是什么情况呢?
|
|||
|
|
|
|||
|
|
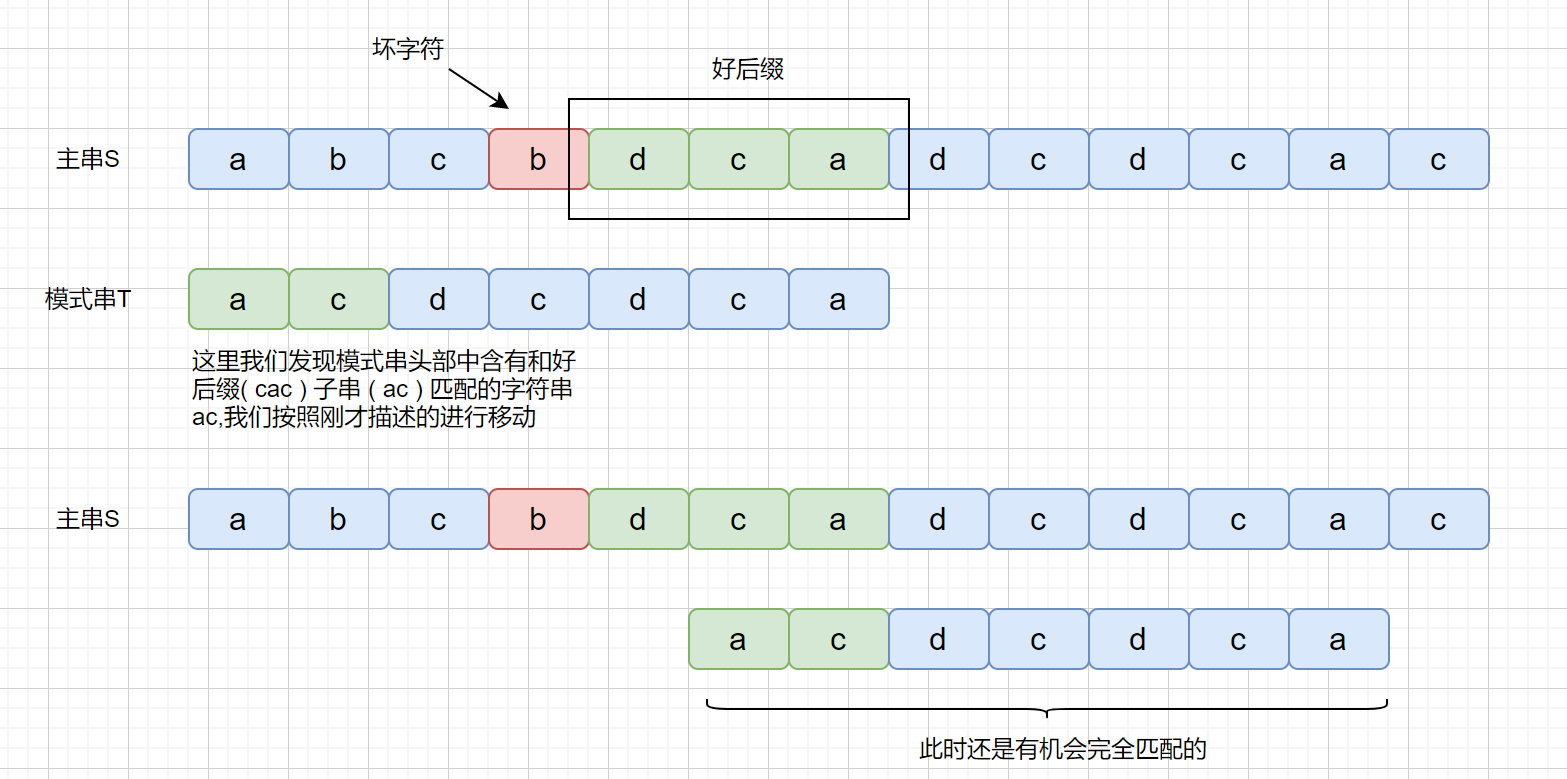
|
|||
|
|
|
|||
|
|
下面我们通过动图来看一下某一例子的具体的执行过程
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
视频
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
说到这里,坏字符和好后缀规则就算说完了,坏字符很容易理解,我们对好后缀总结一下
|
|||
|
|
|
|||
|
|
1.如果模式串**含有好后缀**,无论是中间还是头部可以按照规则进行移动。如果好后缀在模式串中出现多次,则以**最右侧的好后缀**为基准。
|
|||
|
|
|
|||
|
|
2.如果模式串**头部含有**好后缀子串则可以按照规则进行移动,中间部分含有好后缀子串则不可以。
|
|||
|
|
|
|||
|
|
3.如果在模式串尾部就出现不匹配的情况,即不存在好后缀时,则根据坏字符进行移动,这里有的文章没有提到,是个需要特别注意的地方,我是在这个论文里找到答案的,感兴趣的同学可以看下。
|
|||
|
|
|
|||
|
|
> Boyer R S,Moore J S. A fast string searching algorithm[J]. Communications of the ACM,1977,10: 762-772.
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
之前我们刚开始说坏字符的时候,是不是有可能会出现负值的情况,即往左移动的情况,所以我们为了解决这个问题,我们可以分别计算好后缀和坏字符往后滑动的位数**(好后缀不为 0 的情况)**,然后取两个数中最大的,作为模式串往后滑动的位数。
|
|||
|
|
|
|||
|
|
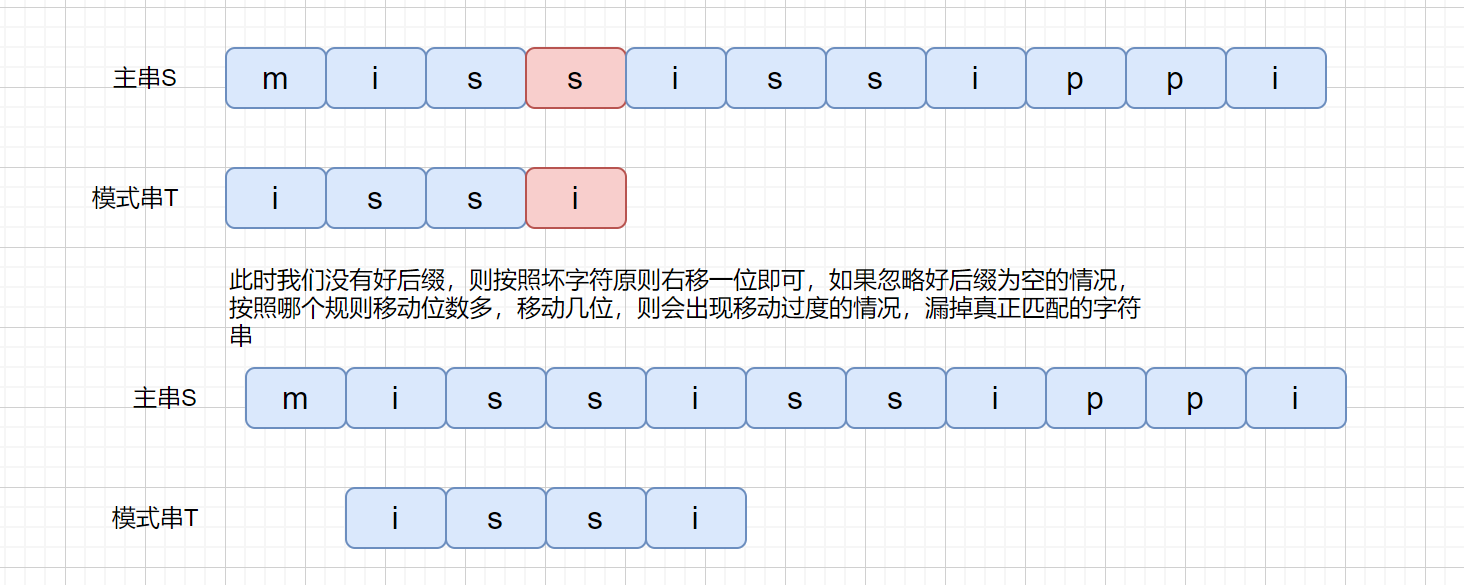
|
|||
|
|
|
|||
|
|
这破图画起来是真费劲啊。下面我们来看一下算法代码,代码有点长,我都标上了注释也在网站上 AC 了,如果各位感兴趣可以看一下,不感兴趣理解坏字符和好后缀规则即可。可以直接跳到 KMP 部分
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int strStr(String haystack, String needle) {
|
|||
|
|
char[] hay = haystack.toCharArray();
|
|||
|
|
char[] need = needle.toCharArray();
|
|||
|
|
int haylen = haystack.length();
|
|||
|
|
int needlen = need.length;
|
|||
|
|
return bm(hay,haylen,need,needlen);
|
|||
|
|
}
|
|||
|
|
//用来求坏字符情况下移动位数
|
|||
|
|
private static void badChar(char[] b, int m, int[] bc) {
|
|||
|
|
//初始化
|
|||
|
|
for (int i = 0; i < 256; ++i) {
|
|||
|
|
bc[i] = -1;
|
|||
|
|
}
|
|||
|
|
//m 代表模式串的长度,如果有两个 a,则后面那个会覆盖前面那个
|
|||
|
|
for (int i = 0; i < m; ++i) {
|
|||
|
|
int ascii = (int)b[i];
|
|||
|
|
bc[ascii] = i;//下标
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
//用来求好后缀条件下的移动位数
|
|||
|
|
private static void goodSuffix (char[] b, int m, int[] suffix,boolean[] prefix) {
|
|||
|
|
//初始化
|
|||
|
|
for (int i = 0; i < m; ++i) {
|
|||
|
|
suffix[i] = -1;
|
|||
|
|
prefix[i] = false;
|
|||
|
|
}
|
|||
|
|
for (int i = 0; i < m - 1; ++i) {
|
|||
|
|
int j = i;
|
|||
|
|
int k = 0;
|
|||
|
|
while (j >= 0 && b[j] == b[m-1-k]) {
|
|||
|
|
--j;
|
|||
|
|
++k;
|
|||
|
|
suffix[k] = j + 1;
|
|||
|
|
}
|
|||
|
|
if (j == -1) prefix[k] = true;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
public static int bm (char[] a, int n, char[] b, int m) {
|
|||
|
|
|
|||
|
|
int[] bc = new int[256];//创建一个数组用来保存最右边字符的下标
|
|||
|
|
badChar(b,m,bc);
|
|||
|
|
//用来保存各种长度好后缀的最右位置的数组
|
|||
|
|
int[] suffix_index = new int[m];
|
|||
|
|
//判断是否是头部,如果是头部则true
|
|||
|
|
boolean[] ispre = new boolean[m];
|
|||
|
|
goodSuffix(b,m,suffix_index,ispre);
|
|||
|
|
int i = 0;//第一个匹配字符
|
|||
|
|
//注意结束条件
|
|||
|
|
while (i <= n-m) {
|
|||
|
|
int j;
|
|||
|
|
//从后往前匹配,匹配失败,找到坏字符
|
|||
|
|
for (j = m - 1; j >= 0; --j) {
|
|||
|
|
if (a[i+j] != b[j]) break;
|
|||
|
|
}
|
|||
|
|
//模式串遍历完毕,匹配成功
|
|||
|
|
if (j < 0) {
|
|||
|
|
return i;
|
|||
|
|
}
|
|||
|
|
//下面为匹配失败时,如何处理
|
|||
|
|
//求出坏字符规则下移动的位数,就是我们坏字符下标减最右边的下标
|
|||
|
|
int x = j - bc[(int)a[i+j]];
|
|||
|
|
int y = 0;
|
|||
|
|
//好后缀情况,求出好后缀情况下的移动位数,如果不含有好后缀的话,则按照坏字符来
|
|||
|
|
if (y < m-1 && m - 1 - j > 0) {
|
|||
|
|
y = move(j, m, suffix_index,ispre);
|
|||
|
|
}
|
|||
|
|
//移动
|
|||
|
|
i = i + Math.max(x,y);
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
// j代表坏字符的下标
|
|||
|
|
private static int move (int j, int m, int[] suffix_index, boolean[] ispre) {
|
|||
|
|
//好后缀长度
|
|||
|
|
int k = m - 1 - j;
|
|||
|
|
//如果含有长度为 k 的好后缀,返回移动位数,
|
|||
|
|
if (suffix_index[k] != -1) return j - suffix_index[k] + 1;
|
|||
|
|
//找头部为好后缀子串的最大长度,从长度最大的子串开始
|
|||
|
|
for (int r = j + 2; r <= m-1; ++r) {
|
|||
|
|
//如果是头部
|
|||
|
|
if (ispre[m-r] == true) {
|
|||
|
|
return r;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
//如果没有发现好后缀匹配的串,或者头部为好后缀子串,则移动到 m 位,也就是匹配串的长度
|
|||
|
|
return m;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
我们来理解一下我们代码中用到的两个数组,因为两个规则的移动位数,只与模式串有关,与主串无关,所以我们可以提前求出每种情况的移动情况,保存到数组中。
|
|||
|
|
|
|||
|
|
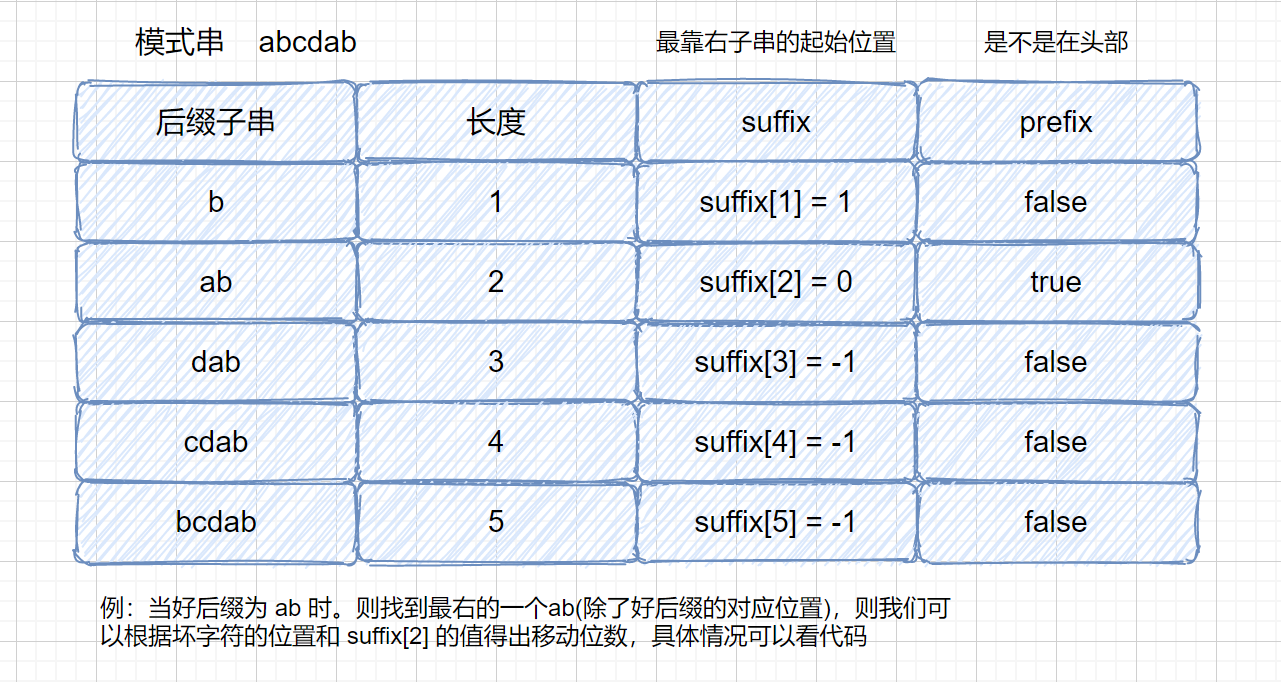
|
|||
|
|
|
|||
|
|
## KMP算法(Knuth-Morris-Pratt)
|
|||
|
|
|
|||
|
|
我们刚才讲了 BM 算法,虽然不是特别容易理解,但是如果你用心看的话肯定可以看懂的,我们再来看一个新的算法,这个算法是考研时必考的算法。实际上 BM 和 KMP 算法的本质是一样的,你理解了 BM 再来理解 KMP 那就是分分钟的事啦。
|
|||
|
|
|
|||
|
|
我们先来看一个实例
|
|||
|
|
|
|||
|
|
视频
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
为了让读者更容易理解,我们将指针移动改成了模式串移动,两者相对与主串的移动是一致的,重新比较时都是从指针位置继续比较。
|
|||
|
|
|
|||
|
|
通过上面的实例是不是很快就能理解 KMP 算法的思想了,但是 KMP 的难点不是在这里,不过多思考,认真看理解起来也是很轻松的。
|
|||
|
|
|
|||
|
|
在上面的例子中我们提到了一个名词,**最长公共前后缀**,这个是什么意思呢?下面我们通过一个较简单的例子进行描述。
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
此时我们在红色阴影处匹配失败,绿色为匹配成功部分,则我们观察匹配成功的部分。
|
|||
|
|
|
|||
|
|
我们来看一下匹配成功部分的所有前缀
|
|||
|
|
|
|||
|
|
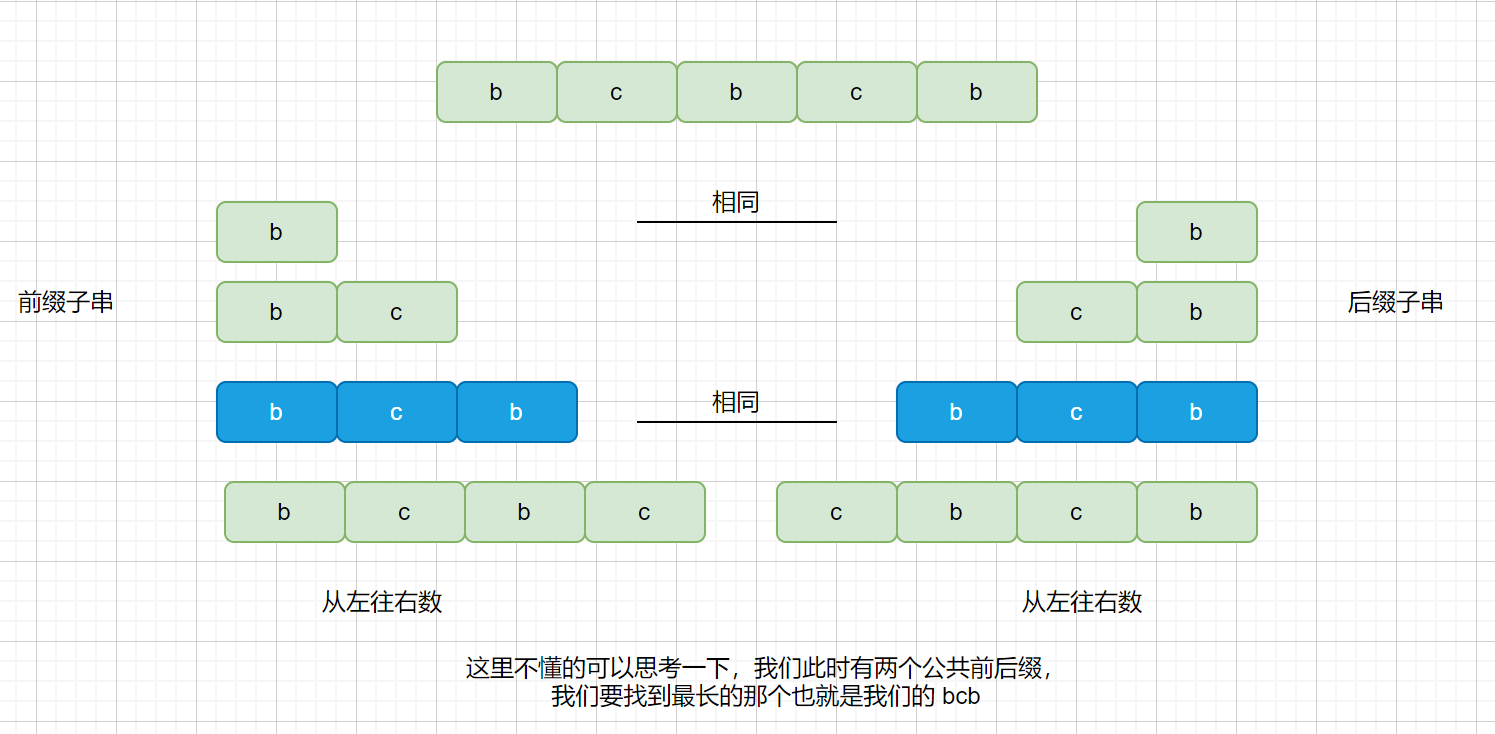
|
|||
|
|
|
|||
|
|
我们的最长公共前后缀如下图,则我们需要这样移动
|
|||
|
|
|
|||
|
|

|
|||
|
|
|
|||
|
|
好啦,看完上面的图,KMP的核心原理已经基本搞定了,但是我们现在的问题是,我们应该怎么才能知道他的最长公共前后缀的长度是多少呢?怎么知道移动多少位呢?
|
|||
|
|
|
|||
|
|
刚才我们在 BM 中说到,我们移动位数跟主串无关,只跟模式串有关,跟我们的 bc,suffix,prefix 数组的值有关,我们通过这些数组就可以知道我们每次移动多少位啦,其实 KMP 也有一个数组,这个数组叫做 next 数组,那么这个 next 数组存的是什么呢?
|
|||
|
|
|
|||
|
|
next 数组存的咱们最长公共前后缀中,前缀的结尾字符下标。是不是感觉有点别扭,我们通过一个例子进行说明。
|
|||
|
|
|
|||
|
|
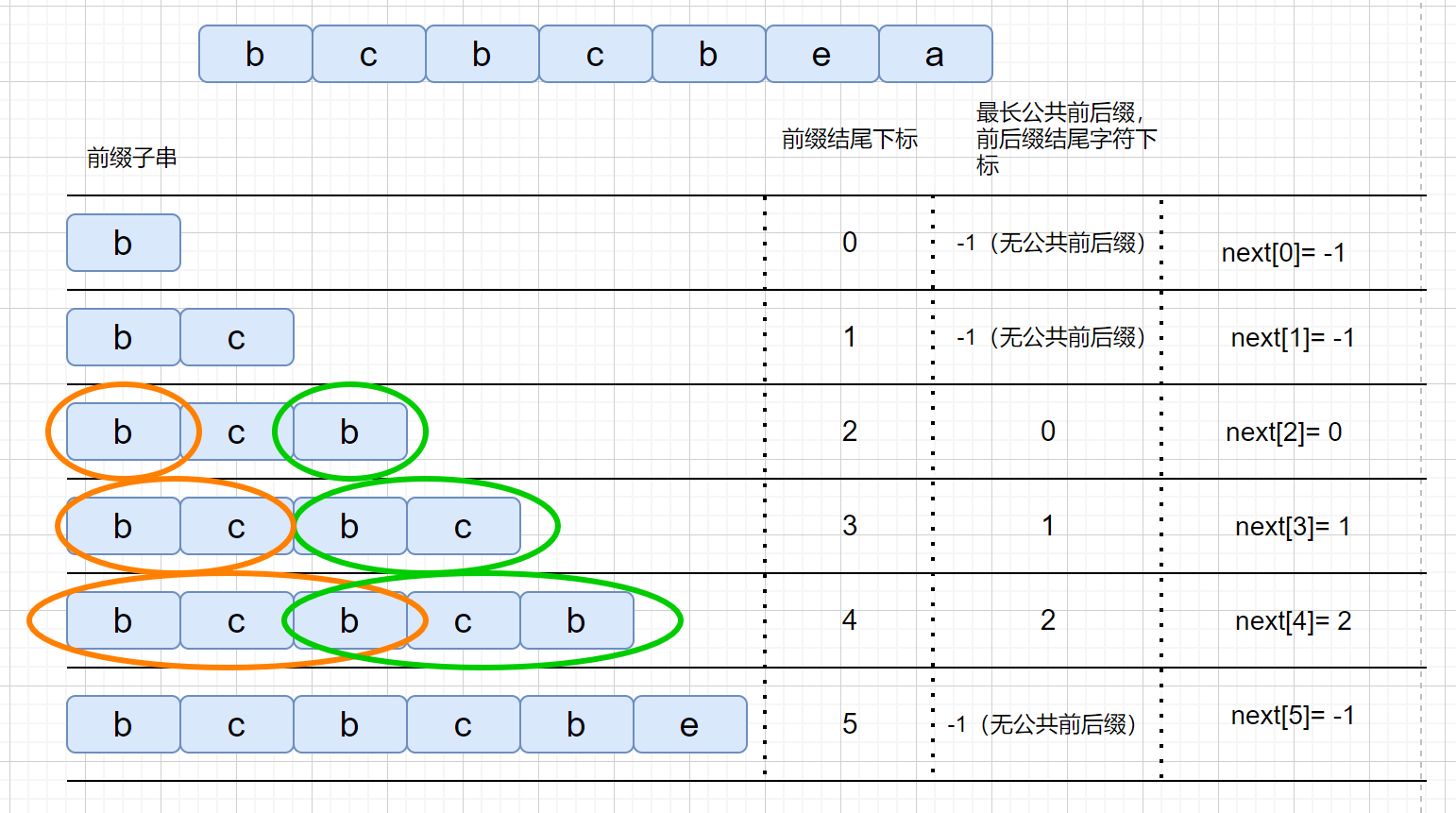
|
|||
|
|
|
|||
|
|
我们知道 next 数组之后,我们的 KMP 算法实现起来就很容易啦,另外我们看一下 next 数组到底是干什么用的。
|
|||
|
|
|
|||
|
|
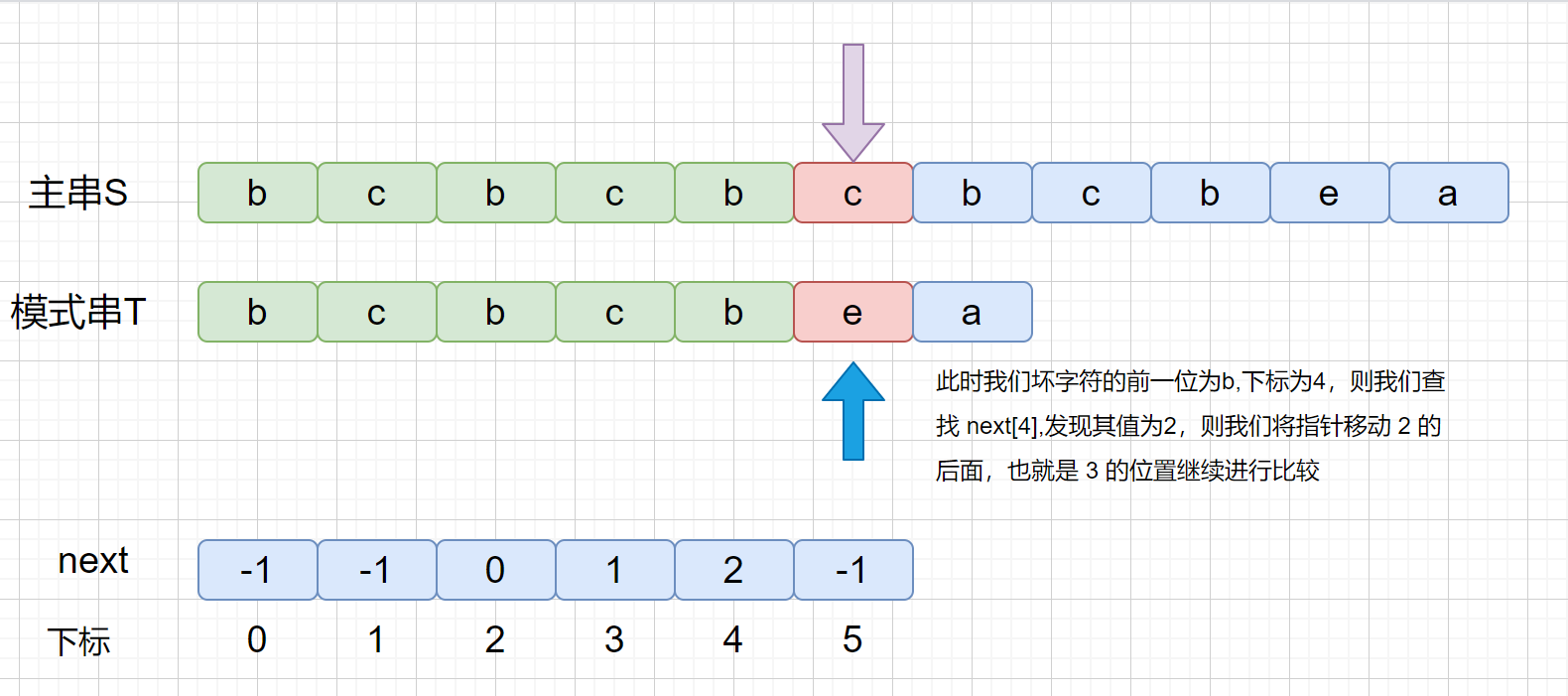
|
|||
|
|
|
|||
|
|
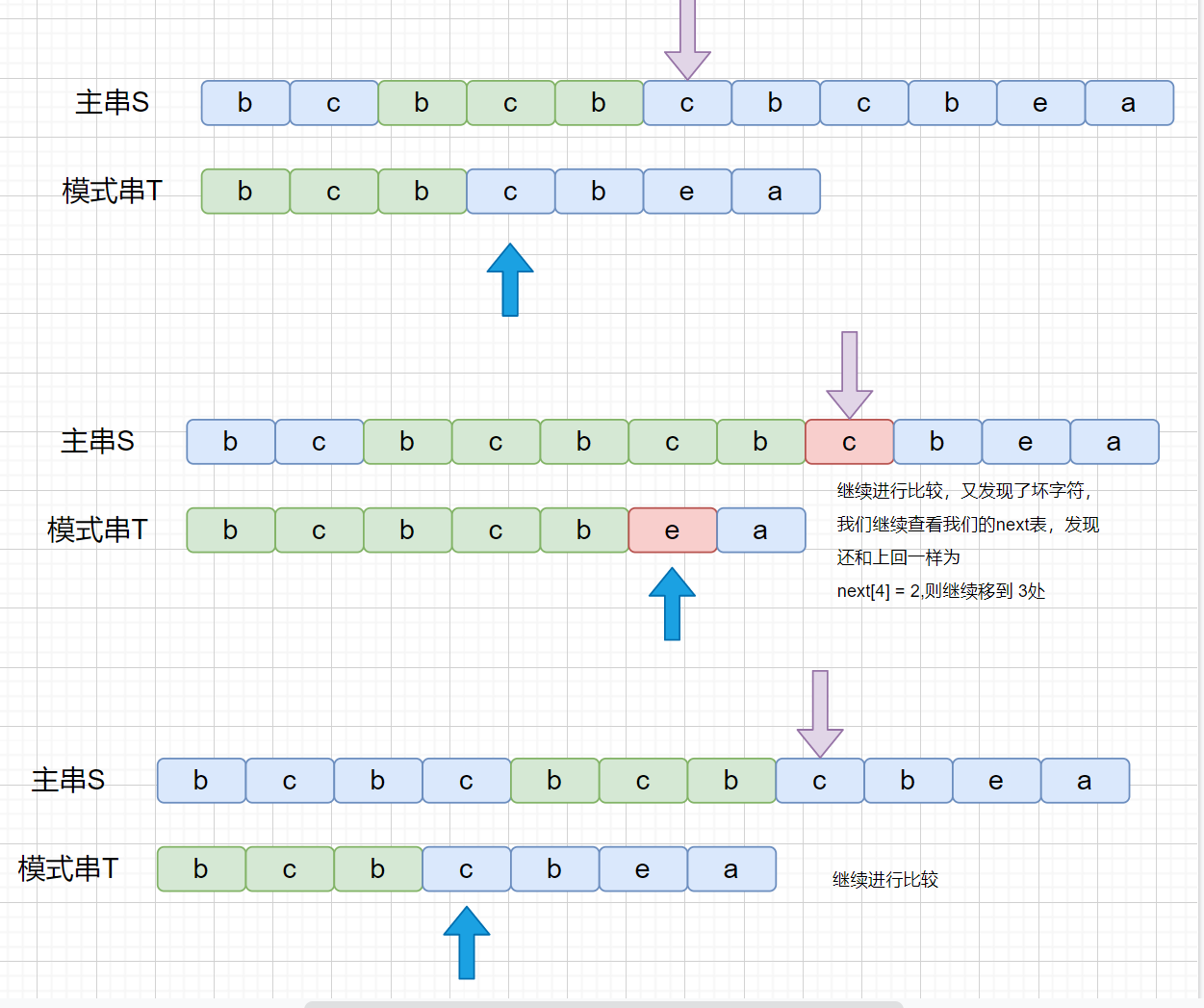
|
|||
|
|
|
|||
|
|
剩下的就不用说啦,完全一致啦,咱们将上面这个例子,翻译成和咱们开头对应的动画大家看一下。
|
|||
|
|
|
|||
|
|
**因为不可以放置视频,所以想看视频的同学,可以去看公众号原文,那里有视频**
|
|||
|
|
|
|||
|
|
下面我们看一下代码,标有详细注释,大家认真看呀。
|
|||
|
|
|
|||
|
|
**注:很多教科书的 next 数组表示方式不一致,理解即可**
|
|||
|
|
|
|||
|
|
```java
|
|||
|
|
class Solution {
|
|||
|
|
public int strStr(String haystack, String needle) {
|
|||
|
|
//两种特殊情况
|
|||
|
|
if (needle.length() == 0) {
|
|||
|
|
return 0;
|
|||
|
|
}
|
|||
|
|
if (haystack.length() == 0) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
// char 数组
|
|||
|
|
char[] hasyarr = haystack.toCharArray();
|
|||
|
|
char[] nearr = needle.toCharArray();
|
|||
|
|
//长度
|
|||
|
|
int halen = hasyarr.length;
|
|||
|
|
int nelen = nearr.length;
|
|||
|
|
//返回下标
|
|||
|
|
return kmp(hasyarr,halen,nearr,nelen);
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
public int kmp (char[] hasyarr, int halen, char[] nearr, int nelen) {
|
|||
|
|
//获取next 数组
|
|||
|
|
int[] next = next(nearr,nelen);
|
|||
|
|
int j = 0;
|
|||
|
|
for (int i = 0; i < halen; ++i) {
|
|||
|
|
//发现不匹配的字符,然后根据 next 数组移动指针,移动到最大公共前后缀的,
|
|||
|
|
//前缀的后一位,和咱们移动模式串的含义相同
|
|||
|
|
while (j > 0 && hasyarr[i] != nearr[j]) {
|
|||
|
|
j = next[j - 1] + 1;
|
|||
|
|
//超出长度时,可以直接返回不存在
|
|||
|
|
if (nelen - j + i > halen) {
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
//如果相同就将指针同时后移一下,比较下个字符
|
|||
|
|
if (hasyarr[i] == nearr[j]) {
|
|||
|
|
++j;
|
|||
|
|
}
|
|||
|
|
//遍历完整个模式串,返回模式串的起点下标
|
|||
|
|
if (j == nelen) {
|
|||
|
|
return i - nelen + 1;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
return -1;
|
|||
|
|
}
|
|||
|
|
//这一块比较难懂,不想看的同学可以忽略,了解大致含义即可,或者自己调试一下,看看运行情况
|
|||
|
|
//我会每一步都写上注释
|
|||
|
|
public int[] next (char[] needle,int len) {
|
|||
|
|
//定义 next 数组
|
|||
|
|
int[] next = new int[len];
|
|||
|
|
// 初始化
|
|||
|
|
next[0] = -1;
|
|||
|
|
int k = -1;
|
|||
|
|
for (int i = 1; i < len; ++i) {
|
|||
|
|
//我们此时知道了 [0,i-1]的最长前后缀,但是k+1的指向的值和i不相同时,我们则需要回溯
|
|||
|
|
//因为 next[k]就时用来记录子串的最长公共前后缀的尾坐标(即长度)
|
|||
|
|
//就要找 k+1前一个元素在next数组里的值,即next[k+1]
|
|||
|
|
while (k != -1 && needle[k + 1] != needle[i]) {
|
|||
|
|
k = next[k];
|
|||
|
|
}
|
|||
|
|
// 相同情况,就是 k的下一位,和 i 相同时,此时我们已经知道 [0,i-1]的最长前后缀
|
|||
|
|
//然后 k - 1 又和 i 相同,最长前后缀加1,即可
|
|||
|
|
if (needle[k+1] == needle[i]) {
|
|||
|
|
++k;
|
|||
|
|
}
|
|||
|
|
next[i] = k;
|
|||
|
|
|
|||
|
|
}
|
|||
|
|
return next;
|
|||
|
|
}
|
|||
|
|
}
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
这篇文章真的写了很久很久,觉得还不错的话,就麻烦您点个赞吧,大家也可以去我的公众号看我的所有文章,每个都有动图解析,公众号:[袁厨的算法小屋](https://cdn.jsdelivr.net/gh/tan45du/tan45du.github.io.photo@master/photo/qrcode_for_gh_1f36d2ef6df9_258.5lojyphpkso0.jpg)
|
|||
|
|
|