mirror of
https://github.com/chefyuan/algorithm-base.git
synced 2024-12-28 21:36:17 +00:00
243 lines
12 KiB
Markdown
243 lines
12 KiB
Markdown
> 如果阅读时,发现错误,或者动画不可以显示的问题可以添加我微信好友 **[tan45du_one](https://raw.githubusercontent.com/tan45du/tan45du.github.io/master/个人微信.15egrcgqd94w.jpg)** ,备注 github + 题目 + 问题 向我反馈
|
||
>
|
||
> 感谢支持,该仓库会一直维护,希望对各位有一丢丢帮助。
|
||
>
|
||
> 另外希望手机阅读的同学可以来我的 <u>[**公众号:程序厨**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u> 两个平台同步,想要和题友一起刷题,互相监督的同学,可以在我的小屋点击<u>[**刷题小队**](https://raw.githubusercontent.com/tan45du/test/master/微信图片_20210320152235.2pthdebvh1c0.png)</u>进入。
|
||
|
||
**写在前面**
|
||
|
||
袁记菜馆内
|
||
|
||
> 袁厨:小二,最近快要过年了,咱们店也要给大家发点年终奖啦,你去根据咱们的**红黑豆小本本**,看一下大家都该发多少的年终奖,然后根据金额从小到大排好,按顺序一个一个发钱,大家回去过个好年,你也老大不小了,回去取个媳妇。
|
||
>
|
||
> 小二:好滴掌柜的,我现在马上就去。
|
||
|
||
上面说到的按照金额从大到小排好就是我们今天要讲的内容 --- 排序。
|
||
|
||
排序是我们生活中经常会面对的问题,体育课的时候,老师会让我们从矮到高排列,考研录取时,成绩会按总分从高到底进行排序(考研的各位读者,你们必能收到心仪学校给你们寄来的大信封),我们网购时,有时会按销量从高到低,价格从低到高,将最符合咱们预期的商品列在前面。
|
||
|
||
概念:将杂乱无章的数据元素,通过**一定的方法**(排序算法)按**关键字**(k)顺序排列的过程叫做排序。例如我们上面的销量和价格就是关键字
|
||
|
||
**排序算法的稳定性**
|
||
|
||
什么是排序算法的稳定性呢?
|
||
|
||
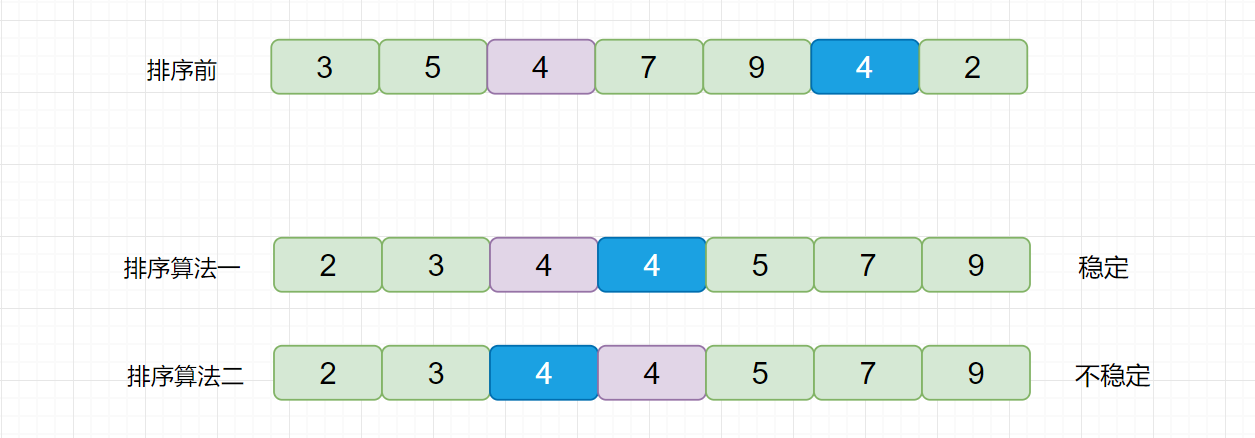
因为我们待排序的记录序列中可能存在两个或两个以上的关键字相等的记录,**排序结果可能会存在不唯一的情况**,所以我们排序之后,如果相等元素之间**原有的先后顺序不变**。则称所用的排序方法是**稳定的**,反之则称之为**不稳定的**。见下图
|
||
|
||
|
||
|
||
例如上图,我们的数组中有两个相同的元素 4, 我们分别用不同的排序算法对其排序,算法一排序之后,两个相同元素的**相对位置**没有发生改变,我们则称之为**稳定的排序算法**,算法二排序之后相对位置发生改变,则为**不稳定的排序算法**。
|
||
|
||
那排序算法的稳定性又有什么用呢?
|
||
|
||
在我们做题中大多只是将数组进行排序,只需考虑时间复杂度空间复杂度等指标,排序算法是否稳定,一般不进行考虑。但是在真正软件开发中排序算法的稳定性是一个特别重要的衡量指标。继续说我们刚才的例子。我们想要实现年终奖从少到多的排序,然后相同年终奖区间内的红豆数也按照从少到多进行排序。
|
||
|
||
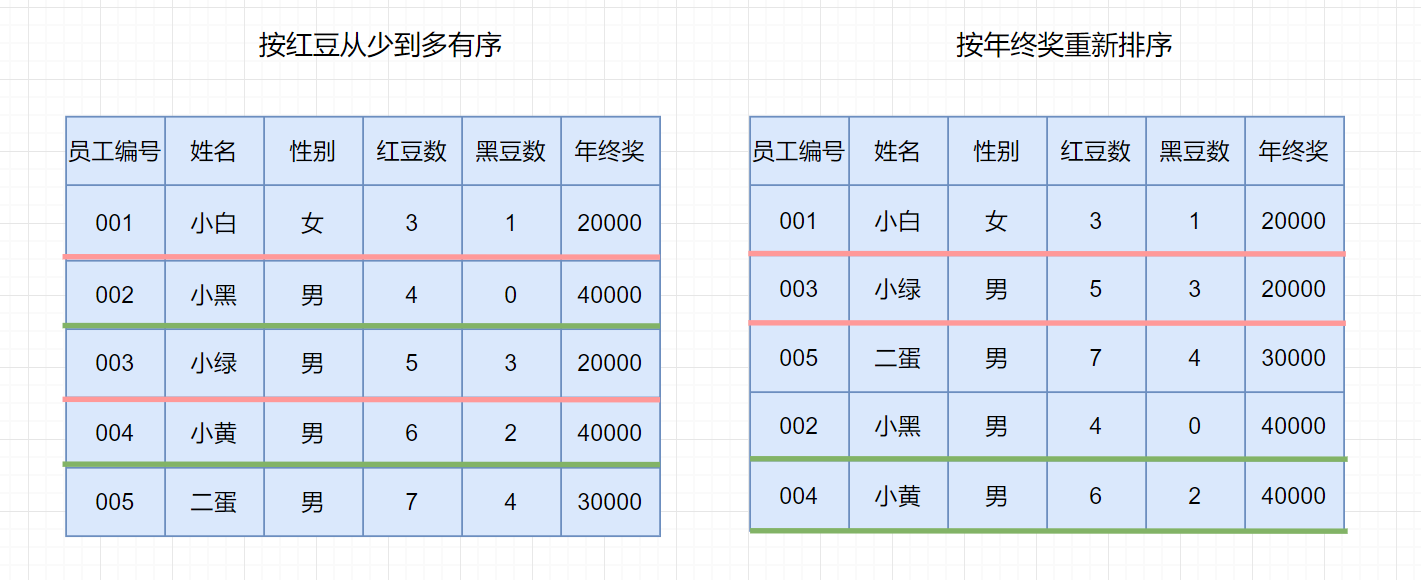
排序算法的稳定性在这里就显得至关重要。这是为什么呢?见下图
|
||
|
||
|
||
|
||
第一次排序之后,所有的职工按照**红豆数**从少到多有序。
|
||
|
||
第二次排序中,我们使用**稳定的排序算法**,所以经过第二次排序之后,年终奖相同的职工,仍然保持着红豆的有序(想对位置不变),红豆仍是从小到大排序。我们使用稳定的排序算法,只需要两次排序即可。
|
||
|
||
稳定排序可以让第一个关键字排序的结果服务于第二个关键字排序中数值相等的那些数。
|
||
|
||
上述情况如果我们利用不稳定的排序算法,实现这一效果是十分复杂的。
|
||
|
||
**比较类和非比较类**
|
||
|
||
我们根据元素是否依靠与其他元素的比较来决定元素间的相对次序。以此来区分比较类排序算法和非比较类排序算法。
|
||
|
||
**内排序和外排序**
|
||
|
||
内排序是在排序的整个过程中,待排序的所有记录全部被放置在内存中。外排序是由于排序的记录个数太多,不能同时放置在内存中,整个排序过程需要在内外存之间多次交换数据才能进行,常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
|
||
|
||
对我们内排序来说,我们主要受三个方面影响,时间性能,辅助空间,算法的复杂性
|
||
|
||
**时间性能**
|
||
|
||
在我们的排序算法执行过程中,主要执行两种操作比较和交换,比较是排序算法最起码的操作,移动指记录从一个位置移动到另一个位置。所以我们一个高效的排序算法,应该尽可能少的比较和移动。
|
||
|
||
**辅助空间**
|
||
|
||
执行算法所需要的辅助空间的多少,也是来衡量排序算法性能的一个重要指标
|
||
|
||
**算法的复杂度**
|
||
|
||
这里的算法复杂度不是指算法的时间复杂度,而是指算法本身的复杂度,过于复杂的算法也会影响排序的性能。
|
||
|
||
下面我们一起复习两种**简单排序算法**,**冒泡排序**和**简单选择排序**,看看有没有之前忽略的东西。
|
||
|
||
### **冒泡排序**(Bubble Sort)
|
||
|
||
估计我们在各个算法书上介绍排序时,第一个估计都是冒泡排序。主要是这个排序算法思路最简单,也最容易理解,(也可能是它的名字好听,哈哈),学过的老哥们也一起来复习一下吧,我们一起深挖一下冒泡排序。
|
||
|
||
冒泡排序的基本思想是,**两两比较相邻记录的关键字**,如果是反序则交换,直到没有反序为止。冒泡一次冒泡会让至少一个元素移动到它应该在的位置,那么如果数组有 n 个元素,重复 n 次后则能完成排序。根据定义可知那么冒泡排序显然是一种比较类排序。
|
||
|
||
**最简单的排序实现**
|
||
|
||
我们来看一下这段代码
|
||
|
||
Java Code:
|
||
|
||
```java
|
||
class Solution {
|
||
public int[] sortArray(int[] nums) {
|
||
int len = nums.length;
|
||
for (int i = 0; i < len; ++i) {
|
||
for (int j = i+1; j < len; ++j) {
|
||
if (nums[i] > nums[j]) {
|
||
swap(nums,i,j);
|
||
}
|
||
}
|
||
}
|
||
return nums;
|
||
|
||
}
|
||
public void swap(int[] nums,int i,int j) {
|
||
int temp = nums[i];
|
||
nums[i] = nums[j];
|
||
nums[j] = temp;
|
||
}
|
||
}
|
||
```
|
||
|
||
Python Code:
|
||
|
||
```python
|
||
from typing import List
|
||
class Solution:
|
||
def sortArray(self, nums: List[int])->List[int]:
|
||
leng = len(nums)
|
||
for i in range(0, leng):
|
||
for j in range(i + 1, leng):
|
||
if nums[i] > nums[j]:
|
||
self.swap(nums, i, j)
|
||
return nums
|
||
|
||
def swap(self, nums: List[int], i: int, j: int):
|
||
temp = nums[i]
|
||
nums[i] = nums[j]
|
||
nums[j] = temp
|
||
```
|
||
|
||
我们来思考一下上面的代码,每次让关键字 nums[i] 和 nums[j] 进行比较如果 nums[i] > nums[j] 时则进行交换,这样 nums[0] 在经过一次循环后一定为最小值。那么这段代码是冒泡排序吗?
|
||
|
||
显然不是,我们冒泡排序的思想是两两比较**相邻记录**的关键字,注意里面有相邻记录,所以这段代码不是我们的冒泡排序,下面我们用动图来模拟一下冒泡排序的执行过程,看完之后一定可以写出正宗的冒泡排序。
|
||
|
||

|
||
|
||
**题目代码**
|
||
|
||
```java
|
||
class Solution {
|
||
public int[] sortArray(int[] nums) {
|
||
int len = nums.length;
|
||
for (int i = 0; i < len; ++i) {
|
||
for (int j = 0; j < len - i - 1; ++j) {
|
||
if (nums[j] > nums[j+1]) {
|
||
swap(nums,j,j+1);
|
||
}
|
||
}
|
||
}
|
||
return nums;
|
||
}
|
||
public void swap(int[] nums,int i,int j) {
|
||
int temp = nums[i];
|
||
nums[i] = nums[j];
|
||
nums[j] = temp;
|
||
}
|
||
}
|
||
```
|
||
|
||
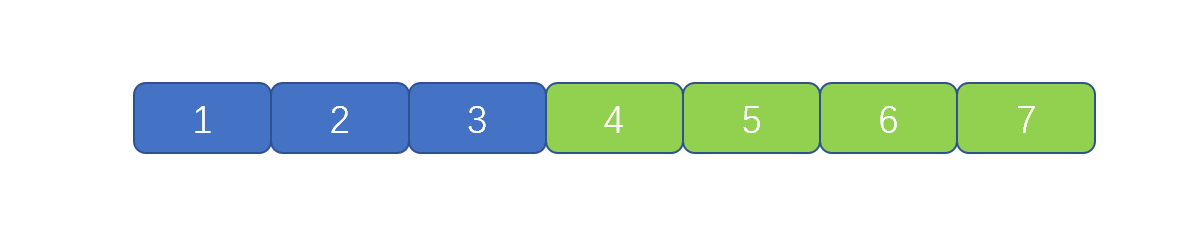
上图中的代码则为正宗的冒泡排序代码,但是我们是不是发现了这个问题
|
||
|
||
|
||
|
||
我们此时数组已经完全有序了,可以直接返回,但是动图中并没有返回,而是继续执行,那我们有什么办法让其完全有序时,直接返回,不继续执行吗?
|
||
|
||
我们设想一下,我们是通过 nums[j] 和 nums[j+1] 进行比较,如果大于则进行交换,那我们设想一下,如果一个完全有序的数组,我们进行冒泡排序,每次比较发现都不用进行交换。
|
||
|
||
那么如果没有交换则说明当前完全有序。那我们可不可以通过一个标志位来进行判断是否发生了交换呢?当然是可以的
|
||
|
||
我们来对冒泡排序进行改进
|
||
|
||
Java Code:
|
||
|
||
```java
|
||
class Solution {
|
||
public int[] sortArray(int[] nums) {
|
||
int len = nums.length;
|
||
//标志位
|
||
boolean flag = true;
|
||
//注意看 for 循环条件
|
||
for (int i = 0; i < len && flag; ++i) {
|
||
//如果没发生交换,则依旧为false,下次就会跳出循环
|
||
flag = false;
|
||
for (int j = 0; j < len - i - 1; ++j) {
|
||
if (nums[j] > nums[j+1]) {
|
||
swap(nums,j,j+1);
|
||
//发生交换,则变为true,下次继续判断
|
||
flag = true;
|
||
}
|
||
}
|
||
}
|
||
return nums;
|
||
|
||
}
|
||
public void swap(int[] nums,int i,int j) {
|
||
int temp = nums[i];
|
||
nums[i] = nums[j];
|
||
nums[j] = temp;
|
||
}
|
||
}
|
||
```
|
||
|
||
Python Code:
|
||
|
||
```python
|
||
from typing import List
|
||
class Solution:
|
||
def sortArray(self, nums: List[int])->List[int]:
|
||
leng = len(nums)
|
||
# 标志位
|
||
flag = True
|
||
for i in range(0, leng):
|
||
if not flag:
|
||
break
|
||
flag = False
|
||
for j in range(0, leng - i - 1):
|
||
if nums[j] > nums[j + 1]:
|
||
self.swap(nums, j, j + 1)
|
||
# 发生交换,则变为true,下次继续判断
|
||
flag = True
|
||
return nums
|
||
|
||
def swap(self, nums: List[int], i: int, j: int):
|
||
temp = nums[i]
|
||
nums[i] = nums[j]
|
||
nums[j] = temp
|
||
```
|
||
|
||
这样我们就避免掉了已经有序的情况下无意义的循环判断。
|
||
|
||
**冒泡排序时间复杂度分析**
|
||
|
||
最好情况,就是要排序的表完全有序的情况下,根据改进后的代码,我们只需要一次遍历即可,
|
||
|
||
只需 n -1 次比较,时间复杂度为 O(n)。最坏情况时,即待排序表逆序的情况,则需要比较(n-1) + (n-2) +.... + 2 + 1= n*(n-1)/2 ,并等量级的交换,则时间复杂度为 O(n^2)。*
|
||
|
||
_平均情况下,需要 n_(n-1)/4 次交换操作,比较操作大于等于交换操作,而复杂度的上限是 O(n^2),所以平均情况下的时间复杂度就是 O(n^2)。
|
||
|
||
**冒泡排序空间复杂度分析**
|
||
|
||
因为冒泡排序只是相邻元素之间的交换操作,只用到了常量级的额外空间,所以空间复杂度为 O(1)
|
||
|
||
**冒泡排序稳定性分析**
|
||
|
||
那么冒泡排序是稳定的吗?当然是稳定的,我们代码中,当 nums[j] > nums[j + 1] 时,才会进行交换,相等时不会交换,相等元素的相对位置没有改变,所以冒泡排序是稳定的。
|
||
|
||
| 算法名称 | 最好时间复杂度 | 最坏时间复杂度 | 平均时间复杂度 | 空间复杂度 | 是否稳定 |
|
||
| -------- | -------------- | -------------- | -------------- | ---------- | -------- |
|
||
| 冒泡排序 | O(n) | O(n^2) | O(n^2) | O(1) | 稳定 |
|