3.5. 字符串
一個字符串是一個不可改變的字節序列. 字符串可以包含任意的數據, 包括字節值0, 但是通常包含人類可讀的文本. 文本字符串通常被解釋爲采用UTF8編碼的Unicode碼點(rune)序列, 我們稍後會詳細討論這個問題.
內置的 len 函數可以返迴一個字符串的字節數目(不是rune字符數目), 索引操作 s[i] 返迴第i個字節的字節值, i 必鬚滿足 0 ≤ i< len(s) 條件約束.
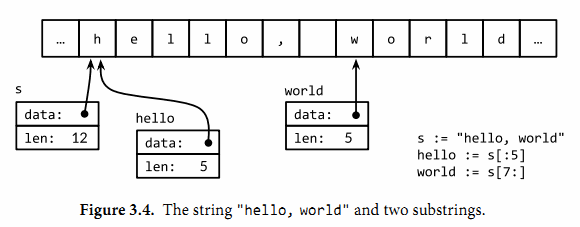
s := "hello, world"
fmt.Println(len(s)) // "12"
fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
Attempting to access a byte outside this range results in a panic:
如果視圖訪問超齣字符串范圍的字節將會導致panic異常:
c := s[len(s)] // panic: index out of range
第i個字節併不一定是字符串的第i個字符, 因此對於非ASCII字符的UTF8編碼會要兩個或多個字節. 我們簡單説下字符的工作方式.
子字符串操作s[i:j]基於原始的s字符串的第i個字節開始到第j個字節(併不包含j本身)生成一個新字符串. 生成的子字符串將包含 j-i 個字節.
fmt.Println(s[0:5]) // "hello"
同樣, 如果索引超齣字符串范圍或者j小於i的話將導致panic異常.
不管i還是j都可能被忽略, 當它們被忽略時將采用0作爲開始位置, 采用 len(s) 作爲接受的位置.
fmt.Println(s[:5]) // "hello"
fmt.Println(s[7:]) // "world"
fmt.Println(s[:]) // "hello, world"
其中 + 操作符將兩個字符串鏈接構造一個新字符串:
fmt.Println("goodbye" + s[5:]) // "goodbye, world"
字符串可以用 == 和 < 進行比較; 比較通過逐個字節比較完成的, 因此比較的結果是字符串自然編碼的順序.
字符串的值是不可變的: 一個字符串包含的字節序列永遠不會被改變, 當然我們也可以給一個字符串變量分配一個新字符串值. 可以像下面這樣將一個字符串追加到另一個字符串
s := "left foot"
t := s
s += ", right foot"
這併不會導致原始的字符串值被改變, 但是 s 將因爲 += 語句持有一個新的字符串值, 但是 t 依然是包含原先的字符串值.
fmt.Println(s) // "left foot, right foot"
fmt.Println(t) // "left foot"
因爲字符串是不可脩改的, 因此嚐試脩改字符串內部數據的操作是被禁止的:
s[0] = 'L' // compile error: cannot assign to s[0]
不變性意味如果兩個字符串共享相同的底層數據是安全的, 這使得複製任何長度的字符串代價是低廉的. 同樣, 一個字符串 s 和對應的子字符串 s[7:] 也可以安全地共享相同的內存, 因此字符串切片操作代價也是低廉的. 在這兩種情況下都沒有必要分配新的內存. 圖3.4 演示了一個字符串和兩個字串共享相同的底層數據.
3.5.1. 字符串面值
字符串值也可以用字符串面值方式編寫, 隻要將一繫列字節序列包含在雙引號卽可:
"Hello, 世界"
因爲Go語言源文件總是用UTF8編碼, 併且Go的文本字符串也以UTF8編碼的方式處理, 我們可以將Unicode碼點也寫到字符串面值中.
在一個雙引號包含的字符串面值中, 可以用以反斜槓\開頭的轉義序列插入任意的數據. 下面換行, 迴車和 製表符等常見的ASCII控製代碼的轉義方式:
\a 響鈴
\b 退格
\f 換頁
\n 換行
\r 迴車
\t 製表符
\v 垂直製表符
\' 單引號 (隻用在 '\'' 形式的rune符號面值中)
\" 雙引號 (隻用在 "..." 形式的字符串面值中)
\\ 反斜槓
可以通過十六進製或八進製轉義在字符串面值包含任意的字節. 一個十六進製的轉義是 \xhh, 其中兩個h表示十六進製數字(大寫或小寫都可以). 一個八進製轉義是 \ooo, 包含三個八進製的o數字(0到7), 但是不能超過\377. 每一個單一的字節表達一個特定的值. 稍後我們將看到如何將一個Unicode碼點寫到字符串面值中.
一個原生的字符串面值形式是 ..., 使用反引號 ``` 代替雙引號. 在原生的字符串面值中, 沒有轉義操作; 全部的內容都是字面的意思, 包含退格和換行, 因此一個程序中的原生字符串面值可能跨越多行. 唯一的特殊處理是是刪除迴車以保證在所有平颱上的值都是一樣的, 包括那些把迴車也放入文本文件的繫統.
原生字符串面值用於編寫正則表達式會很方便, 因爲正則表達式往往會包含很多反斜槓. 原生字符串面值同時廣泛應用於HTML模闆, JSON面值, 命令行提示信息, 以及那些需要擴展到多行的場景.
const GoUsage = `Go is a tool for managing Go source code.
Usage:
go command [arguments]
...`
3.5.2. Unicode
在很久以前, 世界比較簡單的, 起碼計算機就隻有一個ASCII字符集: 美國信息交換標準代碼. ASCII, 更準確地説是美國的ASCII, 使用 7bit 來表示 128 個字符: 包含英文字母的大小寫, 數字, 各種標點符號和設置控製符. 對於早期的計算機程序, 這些足夠了, 但是這也導致了世界上很多其他地區的用戶無法直接使用自己的書寫繫統. 隨着互聯網的發展, 混合多種語言的數據變了很常見. 如何有效處理這些包含了各種語言的豐富多樣的數據呢?
答案就是使用Unicode(unicode.org), 它收集了這個世界上所有的書寫繫統, 包括重音符號和其他變音符號, 製表符和迴車符, 還有很多神祕符號, 每個符號都分配一個Unicode碼點, Unicode碼點對應Go語言中的rune類型.
第八版本的Unicode標準收集了超過120,000個字符, 涵蓋超過100種語言. 這些在計算機程序和數據中是如何體現的那? 通用的表示一個Unicode碼點的數據類型是int32, 也就是Go語言中rune對應的類型; 它的同義詞rune符文正是這個意思.
我們可以將一個符文序列表示爲一個int32序列. 這種編碼方式叫UTF-32或UCS-4, 每個Unicode碼點都使用同樣的大小32bit來表示. 這種方式比較簡單統一, 它會浪費很多存儲空間, 因爲大數據計算機可讀的文本是ASCII字符, 本來每個ASCII字符隻需要8bit或1字節就能表示. 卽使是常用的字符也遠少於65,536個, 也就是説用16bit編碼方式就能表達常用字符. 但是, 還有更好的編碼方法嗎?
3.5.3. UTF-8
UTF8是一個將Unicode碼點編碼爲字節序列的變長編碼. UTF8編碼由Go語言之父 Ken Thompson 和 Rob Pike 共同發明, 現在已經是Unicode的標準. UTF8使用1到4個字節來表示每個Unicode碼點符號, ASCII部分字符隻使用1個字節, 常用字符部分使用2或3個字節. 每個符號編碼後第一個字節的高端bit位用於表示總共有多少個字節. 如果第一個字節的高端bit爲0, 則表示對應7bit的ASCII字符, 每個字符一個字節, 和傳統的ASCII編碼兼容. 如果第一個字節的高端bit是110, 則説明需要2個字節; 後續的每個高端bit都以10開頭. 更大的Unicode碼點也是采用類似的策略處理.
0xxxxxx runes 0-127 (ASCII)
11xxxxx 10xxxxxx 128-2047 (values <128 unused)
110xxxx 10xxxxxx 10xxxxxx 2048-65535 (values <2048 unused)
1110xxx 10xxxxxx 10xxxxxx 10xxxxxx 65536-0x10ffff (other values unused)
變長的編碼無法直接通過索引來訪問第n個字符, 但是UTF8穫得了很多額外的優點. 首先UTF8編碼比較緊湊, 兼容ASCII, 併且可以自動同步: 它可以通過向前迴朔最多2個字節就能確定當前字符編碼的開始字節的位置. 它也是一個前綴編碼, 所以當從左向右解碼時不會有任何歧義也併不需要向前査看. 沒有任何字符的編碼是其它字符編碼的子串, 或是其它編碼序列的字串, 因此蒐索一個字符時隻要蒐索它的字節編碼序列卽可, 不用擔心前後的上下文會對蒐索結果産生榦擾. 同時UTF8編碼的順序和Unicode碼點的順序一致, 因此可以直接排序UTF8編碼序列. 同業也沒有嵌入的NUL(0)字節, 可以很好地兼容那些使用NUL作爲字符串結尾的編程語言.
Go的源文件采用UTF8編碼, 併且Go處理UTF8編碼的文本也很齣色. unicode 包提供了諸多處理 rune 字符相關功能的函數函數(區分字母和數組, 或者是字母的大寫和小寫轉換等), unicode/utf8 包了提供了rune 字符序列的UTF8編碼和解碼的功能.
有很多Unicode字符很難直接從鍵盤輸入, 併且很多字符有着相似的結構; 有一些甚至是不可見的字符. Go字符串面值中的Unicode轉義字符讓我們可以通過Unicode碼點輸入特殊的字符. 有兩種形式, \uhhhh 對應16bit的碼點值, \Uhhhhhhhh 對應32bit的碼點值, 其中h是一個十六進製數字; 一般很少需要使用32bit的形式. 每一個對應碼點的UTF8編碼. 例如: 下面的字母串面值都表示相同的值:
"世界"
"\xe4\xb8\x96\xe7\x95\x8c"
"\u4e16\u754c"
"\U00004e16\U0000754c"
上面三個轉義序列爲第一個字符串提供替代寫法, 但是它們的值都是相同的.
Unicode轉義也可以使用在rune字符中. 下面三個字符是等價的:
'世' '\u4e16' '\U00004e16'
對於小於256碼點值可以寫在一個十六進製轉義字節中, 例如 '\x41' 對應 'A' 字符, 但是對於更大的碼點則必鬚使用 \u 或 \U 轉義形式. 因此, '\xe4\xb8\x96' 併不是一個合法的rune字符, 雖然這三個字節對應一個有效的UTF8編碼的碼點.
得意於UTF8優良的設計, 諸多字符串操作都不需要解碼. 我們可以不用解碼直接測試一個字符串是否是另一個字符串的前綴:
func HasPrefix(s, prefix string) bool {
return len(s) >= len(prefix) && s[:len(prefix)] == prefix
}
或者是後綴測試:
func HasSuffix(s, suffix string) bool {
return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix
}
或者是包含子串測試:
func Contains(s, substr string) bool {
for i := 0; i < len(s); i++ {
if HasPrefix(s[i:], substr) {
return true
}
}
return false
}
對於UTF8編碼後文本的處理和原始的字節處理邏輯一樣. 但是對應很多其它編碼則併不是這樣的. (上面的函數都來自 strings 字符串處理包, 雖然它們的實現包含了一個用哈希技術優化的 Contains 實現.)
另以方面, 如果我們眞的關心每個Unicode字符, 我們可以使用其它機製. 考慮前面的第一個例子中的字符串, 它包混合了中西兩種字符. 圖3.5展示了它的內存表示形式. 字符串包含13個字節, 以UTF8形式編碼, 但是隻對應9個Unicode字符:
import "unicode/utf8"
s := "Hello, 世界"
fmt.Println(len(s)) // "13"
fmt.Println(utf8.RuneCountInString(s)) // "9"
爲了處理這些眞實的字符, 我們需要一個UTF8解碼器. unicode/utf8 包提供了實現, 我們可以這樣使用:
for i := 0; i < len(s); {
r, size := utf8.DecodeRuneInString(s[i:])
fmt.Printf("%d\t%c\n", i, r)
i += size
}
每一次調用 DecodeRuneInString 函數都返迴一個 r 和 長度, r 對應字符本身, 長度對應r采用UTF8編碼後的字節數目. 長度可以用於更新第i個字符在字符串中的字節索引位置. 但是這種方式是笨拙的, 我們需要更簡潔的語法. 幸運的是, Go的range循環在處理字符串的時候, 會自動隱式解碼UTF8字符串. 下面的循環運行如圖3.5所示; 需要註意的是對於非ASCII, 索引更新的步長超過1個字節.

for i, r := range "Hello, 世界" {
fmt.Printf("%d\t%q\t%d\n", i, r, r)
}
我們可以使用一個簡單的循環來統計字符串中字符的數目, 像這樣:
n := 0
for _, _ = range s {
n++
}
想其它形式的循環那樣, 我們可以忽略不需要的變量:
n := 0
for range s {
n++
}
或者我們可以直接調用 utf8.RuneCountInString(s) 函數.
正如我們前面提到了, 文本字符串采用UTF8編碼隻是一種慣例,但是對於循環的眞正字符串併不是一個慣例, 這是正確的. 如果用於循環的字符串隻是一個普通的二進製數據, 或者是含有錯誤編碼的UTF8數據, 將會發送什麽?
每一個UTF8字符解碼, 不管是顯示地調用 utf8.DecodeRuneInString 解碼或在 range 循環中隱式地解碼, 如果遇到一個錯誤的輸入字節, 將生成一個特别的Unicode字符 '\uFFFD', 在印刷中這個符號通常是一個黑色六角或鑽石形狀, 里面包含一個白色的問號(?). 當程序遇到這樣的一個字符, 通常是一個信號, 説明輸入併不是一個完美沒有錯誤的的UTF8編碼字符串.
UTF8作爲交換格式是非常方便的, 但是在程序內部采用rune類型可能更方便, 因爲rune大小一致, 支持數組索引和方便切割.
string 接受到 []rune 的轉換, 可以將一個UTF8編碼的字符串解碼爲Unicode字符序列:
// "program" in Japanese katakana
s := "プログラム"
fmt.Printf("% x\n", s) // "e3 83 97 e3 83 ad e3 82 b0 e3 83 a9 e3 83 a0"
r := []rune(s)
fmt.Printf("%x\n", r) // "[30d7 30ed 30b0 30e9 30e0]"
(在第一個Printf中的 % x 參數用於在每個十六進製數字前插入一個空格.)
如果是將一個 []rune 類型的Unicode字符切片或數組轉爲string, 則對它們進行UTF8編碼:
fmt.Println(string(r)) // "プログラム"
將一個整數轉型爲字符串意思是生成整數作爲Unicode碼點的UTF8編碼的字符串:
fmt.Println(string(65)) // "A", not "65"
fmt.Println(string(0x4eac)) // "京"
如果對應碼點的字符是無效的, 則用'\uFFFD'無效字符作爲替換:
fmt.Println(string(1234567)) // "(?)"
3.5.4. 字符串和Byte切片
標準庫中有四個包對字符串處理尤爲重要: bytes, strings, strconv, 和 unicode. strings 包提供了許多如字符串的査詢, 替換, 比較, 截斷, 拆分, 和合併等功能.
bytes 包也提供了很多類似功能的函數, 但是針對和字符串有着相同結構的 []byte 類型. 因爲字符串是隻讀的, 因此逐步構建字符串會導致很多分配和複製. 在這種情況下, 使用 bytes.Buffer 類型會更有效, 稍後我們將展示.
strconv 包提供了 布爾型, 整型數, 浮點數和對應字符串間的相互轉換, 還提供了雙引號的字符串面值形式的轉換.
unicode 包提供了類似 IsDigit, IsLetter, IsUpper, 和 IsLower 等功能, 它們用於給字符分類. 每個函數有一個單一的rune類型的參數, 然後返迴一個布爾值. 像 ToUpper 和 ToLower 之類的轉換函數將用於rune字符的大小寫轉換. 所有的這些函數都是遵循Unicode標準定義的字母,數字等分類規范. strings 包也有類似的函數, 它們是 ToUpper 和 ToLower, 將原始字符串的每個字符都做相應的轉換, 然後返迴新的字符串.
下面的 basename 函數的靈感由Unix shell的同名工具而來. 在我們實現的版本中, basename(s) 將看起來像是繫統路徑的前綴刪除, 同時將看似文件類型的後綴名刪除:
fmt.Println(basename("a/b/c.go")) // "c"
fmt.Println(basename("c.d.go")) // "c.d"
fmt.Println(basename("abc")) // "abc"
第一個版本併沒有使用任何庫, 全部手工實現:
gopl.io/ch3/basename1
// basename removes directory components and a .suffix.
// e.g., a => a, a.go => a, a/b/c.go => c, a/b.c.go => b.c
func basename(s string) string {
// Discard last '/' and everything before.
for i := len(s) - 1; i >= 0; i-- {
if s[i] == '/' {
s = s[i+1:]
break
}
}
// Preserve everything before last '.'.
for i := len(s) - 1; i >= 0; i-- {
if s[i] == '.' {
s = s[:i]
break
}
}
return s
}
一個簡化的版本使用了 strings.LastIndex 庫函數:
gopl.io/ch3/basename2
func basename(s string) string {
slash := strings.LastIndex(s, "/") // -1 if "/" not found
s = s[slash+1:]
if dot := strings.LastIndex(s, "."); dot >= 0 {
s = s[:dot]
}
return s
}
path 和 path/filepath 包提供了關於文件名更一般的函數操作. 使用斜槓分隔路徑可以在任何操作繫統上工作. 斜槓本身不應該用於文件名, 但是在其他一些領域可能是有效的, 例如URL路徑組件. 相比之下, path/filepath 包使用操作繫統本身的路徑規則, 例如 POSIX 繫統使用 /foo/bar, Microsoft Windows 使用 c:\foo\bar 等.
讓我們繼續另一個字符串的例子. 任務是將一個表示整值的字符串, 每隔三個字符插入一個逗號, 例如 "12345" 處理後成爲 "12,345". 這個版本隻適用於整數類型; 支持浮點數類型的支持留做練習.
gopl.io/ch3/comma
// comma inserts commas in a non-negative decimal integer string.
func comma(s string) string {
n := len(s)
if n <= 3 {
return s
}
return comma(s[:n-3]) + "," + s[n-3:]
}
輸入 comma 的參數是一個字符串. 如果輸入字符串的長度小於或等於3的話, 則不需要插入逗號. 否則, comma 將在最後三個字符前切割爲兩個兩個子串, 然後用前面的子串遞歸調用自身.
一個字符串包含的字節數組, 一旦創建, 是不可變的. 相比之下, 一個字節切片的原始則可以自由地脩改.
字符串和字節切片可以相互轉換:
s := "abc"
b := []byte(s)
s2 := string(b)
從概念上講, []byte(s) 轉換是分配了一個新的字節數組保存了字符串數據的拷貝, 然後引用這個字節數組. 編譯器的優化可以避免在一些場景下分配和複製字符串數據, 但總的來説需要確保在b被脩改的情況下, 原始的s字符串也不會改變. 將一個字節切片轉到字符串的 string(b) 操作則是構造一個拷貝, 以確保s2字符串是隻讀的.
爲了避免轉換中不必要的內存分配, bytes包和strings同時提供了許多類似的實用函數. 下面是strings包中的六個函數:
func Contains(s, substr string) bool
func Count(s, sep string) int
func Fields(s string) []string
func HasPrefix(s, prefix string) bool
func Index(s, sep string) int
func Join(a []string, sep string) string
bytes 包中對應的六個函數:
func Contains(b, subslice []byte) bool
func Count(s, sep []byte) int
func Fields(s []byte) [][]byte
func HasPrefix(s, prefix []byte) bool
func Index(s, sep []byte) int
func Join(s [][]byte, sep []byte) []byte
唯一的區别是字符串類型參數被替換成了字節切片類型的參數.
bytes 包還提供了 Buffer 類型用於字節切片的緩存. 一個 Buffer 開始是空的, 但是隨着 string, byte, 和 []byte 等類型數據的寫入可以動態增長, 一個 bytes.Buffer 變量併不需要處理化, 因此零值也是有效的:
gopl.io/ch3/printints
// intsToString is like fmt.Sprintf(values) but adds commas.
func intsToString(values []int) string {
var buf bytes.Buffer
buf.WriteByte('[')
for i, v := range values {
if i > 0 {
buf.WriteString(", ")
}
fmt.Fprintf(&buf, "%d", v)
}
buf.WriteByte(']')
return buf.String()
}
func main() {
fmt.Println(intsToString([]int{1, 2, 3})) // "[1, 2, 3]"
}
當向 bytes.Buffer 添加任意字符的UTF8編碼, 最好使用 bytes.Buffer 的 WriteRune 方法, 但是 WriteByte 方法對於寫入類似 '[' 和 ']' 等 ASCII 字符則更有效.
bytes.Buffer 類型有着諸多實用的功能, 我們在第七章討論接口時層涉及到, 我們將看看如何將它用作一個I/O 的輸入和輸齣對象, 例如 Fprintf 的 io.Writer 輸齣, 或作爲輸入源 io.Reader.
練習3.10: 編寫一個非遞歸版本的comma函數, 使用 bytes.Buffer 代替字符串鏈接操作.
練習3.11: 完善 comma 函數, 以支持浮點數處理和一個可選的正負號處理.
練習3.12: 編寫一個函數, 判斷兩個字符串是否是是相互打亂的, 也就是説它們有着相同的字符, 但是對應不同的順序.
3.5.5. 字符串和數字的轉換
除了字符串, 字符, 字節 之間的轉換, 字符串和數值之間的轉換也比較常見. 由 strconv 包提供這類轉換功能.
將一個整數轉爲字符串, 一種方法是用 fmt.Sprintf; 另一個方法是用 strconv.Itoa(“整數到ASCII”):
x := 123
y := fmt.Sprintf("%d", x)
fmt.Println(y, strconv.Itoa(x)) // "123 123"
FormatInt和FormatUint可以用不同的進製來格式化數字:
fmt.Println(strconv.FormatInt(int64(x), 2)) // "1111011"
fmt.Printf 函數的 %b, %d, %u, 和 %x 等參數提供功能往往比strconv 包的 Format 函數方便很多, 特别是在需要包含附加信息的時候:
s := fmt.Sprintf("x=%b", x) // "x=1111011"
如果要將一個字符串解析爲整數, 可以使用 strconv 包的 Atoi 或 ParseInt 函數, 還有用於解析無符號整數的 ParseUint 函數:
x, err := strconv.Atoi("123") // x is an int
y, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits
ParseInt 函數的第三個參數是用於指定整型數的大小; 例如16表示int16, 0則表示int. 在任何情況下, 返迴的結果 y 總是 int64 類型, 你可以通過強製類型轉換將它轉爲更小的整數類型.
有時候也會使用 fmt.Scanf 來解析輸入的字符串和數字, 特别是當字符串和數字混合在一行的時候, 它可以靈活處理不完整或不規則的輸入.